 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition Paper: Agent AI Towards a Holistic Intelligence
Feb 28, 2024Recent advancements in large foundation models have remarkably enhanced our understanding of sensory information in open-world environments. In leveraging the power of foundation models, it is crucial for AI research to pivot away from excessive reductionism and toward an emphasis on systems that function as cohesive wholes. Specifically, we emphasize developing Agent AI -- an embodied system that integrates large foundation models into agent actions. The emerging field of Agent AI spans a wide range of existing embodied and agent-based multimodal interactions, including robotics, gaming, and healthcare systems, etc. In this paper, we propose a novel large action model to achieve embodied intelligent behavior, the Agent Foundation Model. On top of this idea, we discuss how agent AI exhibits remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Furthermore, we discuss the potential of Agent AI from an interdisciplinary perspective, underscoring AI cognition and consciousness within scientific discourse. We believe that those discussions serve as a basis for future research directions and encourage broader societal engagement.
An Interactive Agent Foundation Model
Feb 08, 2024



The development of artificial intelligence systems is transitioning from creating static, task-specific models to dynamic, agent-based systems capable of performing well in a wide range of applications. We propose an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm for training AI agents across a wide range of domains, datasets, and tasks. Our training paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction, enabling a versatile and adaptable AI framework. We demonstrate the performance of our framework across three separate domains -- Robotics, Gaming AI, and Healthcare. Our model demonstrates its ability to generate meaningful and contextually relevant outputs in each area. The strength of our approach lies in its generality, leveraging a variety of data sources such as robotics sequences, gameplay data, large-scale video datasets, and textual information for effective multimodal and multi-task learning. Our approach provides a promising avenue for developing generalist, action-taking, multimodal systems.
Agent AI: Surveying the Horizons of Multimodal Interaction
Jan 07, 2024



Multi-modal AI systems will likely become a ubiquitous presence in our everyday lives. A promising approach to making these systems more interactive is to embody them as agents within physical and virtual environments. At present, systems leverage existing foundation models as the basic building blocks for the creation of embodied agents. Embedding agents within such environments facilitates the ability of models to process and interpret visual and contextual data, which is critical for the creation of more sophisticated and context-aware AI systems. For example, a system that can perceive user actions, human behavior, environmental objects, audio expressions, and the collective sentiment of a scene can be used to inform and direct agent responses within the given environment. To accelerate research on agent-based multimodal intelligence, we define "Agent AI" as a class of interactive systems that can perceive visual stimuli, language inputs, and other environmentally-grounded data, and can produce meaningful embodied action with infinite agent. In particular, we explore systems that aim to improve agents based on next-embodied action prediction by incorporating external knowledge, multi-sensory inputs, and human feedback. We argue that by developing agentic AI systems in grounded environments, one can also mitigate the hallucinations of large foundation models and their tendency to generate environmentally incorrect outputs. The emerging field of Agent AI subsumes the broader embodied and agentic aspects of multimodal interactions. Beyond agents acting and interacting in the physical world, we envision a future where people can easily create any virtual reality or simulated scene and interact with agents embodied within the virtual environment.
Localized Symbolic Knowledge Distillation for Visual Commonsense Models
Dec 12, 2023


Instruction following vision-language (VL) models offer a flexible interface that supports a broad range of multimodal tasks in a zero-shot fashion. However, interfaces that operate on full images do not directly enable the user to "point to" and access specific regions within images. This capability is important not only to support reference-grounded VL benchmarks, but also, for practical applications that require precise within-image reasoning. We build Localized Visual Commonsense models, which allow users to specify (multiple) regions as input. We train our model by sampling localized commonsense knowledge from a large language model (LLM): specifically, we prompt an LLM to collect commonsense knowledge given a global literal image description and a local literal region description automatically generated by a set of VL models. With a separately trained critic model that selects high-quality examples, we find that training on the localized commonsense corpus can successfully distill existing VL models to support a reference-as-input interface. Empirical results and human evaluations in a zero-shot setup demonstrate that our distillation method results in more precise VL models of reasoning compared to a baseline of passing a generated referring expression to an LLM.
MindAgent: Emergent Gaming Interaction
Sep 19, 2023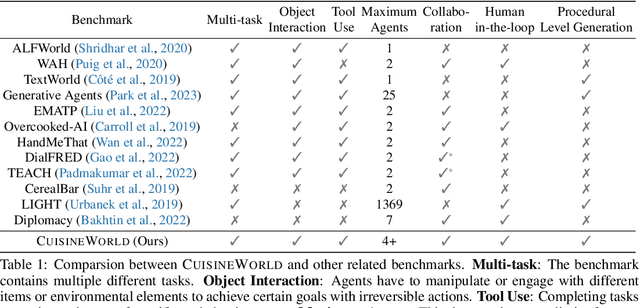
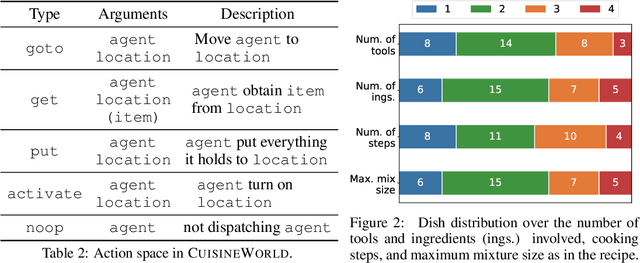
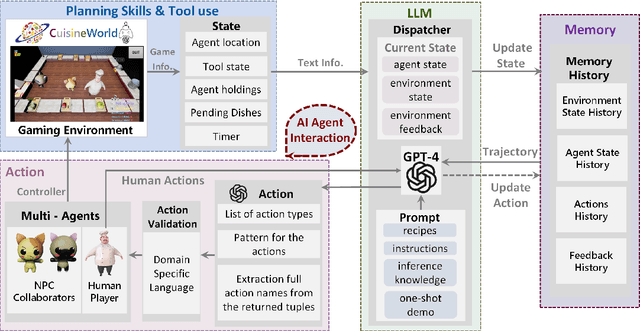
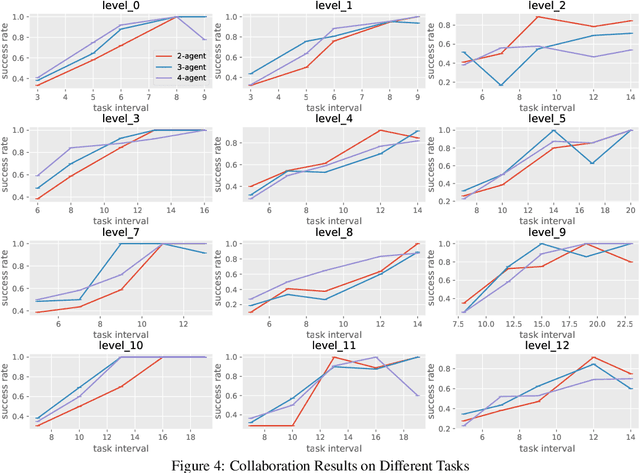
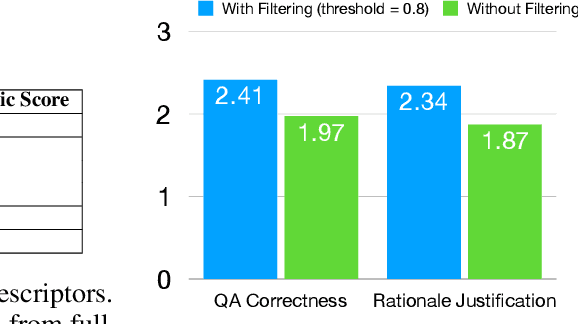
Large Language Models (LLMs) have the capacity of performing complex scheduling in a multi-agent system and can coordinate these agents into completing sophisticated tasks that require extensive collaboration. However, despite the introduction of numerous gaming frameworks, the community has insufficient benchmarks towards building general multi-agents collaboration infrastructure that encompass both LLM and human-NPCs collaborations. In this work, we propose a novel infrastructure - MindAgent - to evaluate planning and coordination emergent capabilities for gaming interaction. In particular, our infrastructure leverages existing gaming framework, to i) require understanding of the coordinator for a multi-agent system, ii) collaborate with human players via un-finetuned proper instructions, and iii) establish an in-context learning on few-shot prompt with feedback. Furthermore, we introduce CUISINEWORLD, a new gaming scenario and related benchmark that dispatch a multi-agent collaboration efficiency and supervise multiple agents playing the game simultaneously. We conduct comprehensive evaluations with new auto-metric CoS for calculating the collaboration efficiency. Finally, our infrastructure can be deployed into real-world gaming scenarios in a customized VR version of CUISINEWORLD and adapted in existing broader Minecraft gaming domain. We hope our findings on LLMs and the new infrastructure for general-purpose scheduling and coordination can help shed light on how such skills can be obtained by learning from large language corpora.
ArK: Augmented Reality with Knowledge Interactive Emergent Ability
May 01, 2023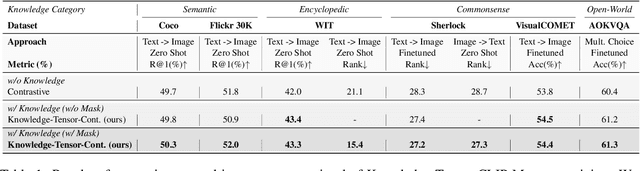
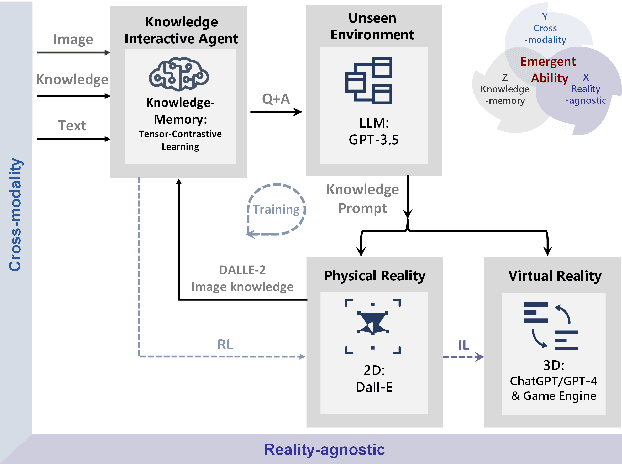

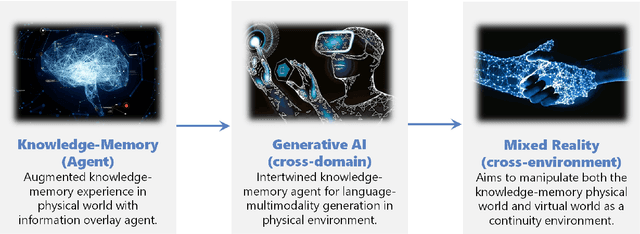
Despite the growing adoption of mixed reality and interactive AI agents, it remains challenging for these systems to generate high quality 2D/3D scenes in unseen environments. The common practice requires deploying an AI agent to collect large amounts of data for model training for every new task. This process is costly, or even impossible, for many domains. In this study, we develop an infinite agent that learns to transfer knowledge memory from general foundation models (e.g. GPT4, DALLE) to novel domains or scenarios for scene understanding and generation in the physical or virtual world. The heart of our approach is an emerging mechanism, dubbed Augmented Reality with Knowledge Inference Interaction (ArK), which leverages knowledge-memory to generate scenes in unseen physical world and virtual reality environments. The knowledge interactive emergent ability (Figure 1) is demonstrated as the observation learns i) micro-action of cross-modality: in multi-modality models to collect a large amount of relevant knowledge memory data for each interaction task (e.g., unseen scene understanding) from the physical reality; and ii) macro-behavior of reality-agnostic: in mix-reality environments to improve interactions that tailor to different characterized roles, target variables, collaborative information, and so on. We validate the effectiveness of ArK on the scene generation and editing tasks. We show that our ArK approach, combined with large foundation models, significantly improves the quality of generated 2D/3D scenes, compared to baselines, demonstrating the potential benefit of incorporating ArK in generative AI for applications such as metaverse and gaming simulation.
Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback
Mar 08, 2023

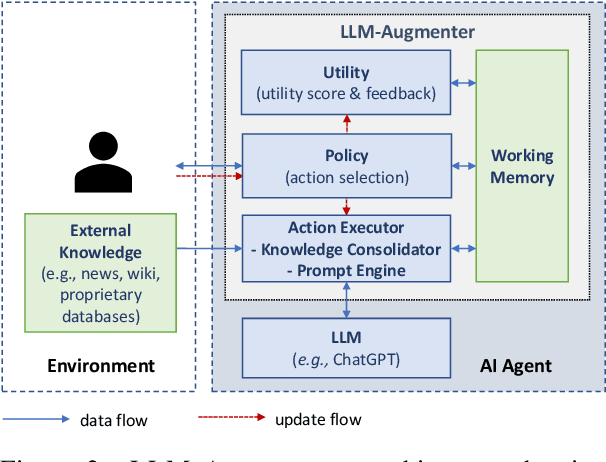

Large language models (LLMs), such as ChatGPT, are able to generate human-like, fluent responses for many downstream tasks, e.g., task-oriented dialog and question answering. However, applying LLMs to real-world, mission-critical applications remains challenging mainly due to their tendency to generate hallucinations and their inability to use external knowledge. This paper proposes a LLM-Augmenter system, which augments a black-box LLM with a set of plug-and-play modules. Our system makes the LLM generate responses grounded in external knowledge, e.g., stored in task-specific databases. It also iteratively revises LLM prompts to improve model responses using feedback generated by utility functions, e.g., the factuality score of a LLM-generated response. The effectiveness of LLM-Augmenter is empirically validated on two types of scenarios, task-oriented dialog and open-domain question answering. LLM-Augmenter significantly reduces ChatGPT's hallucinations without sacrificing the fluency and informativeness of its responses. We make the source code and models publicly available.
Training Vision-Language Transformers from Captions Alone
May 19, 2022
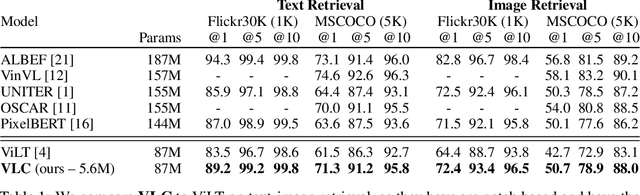
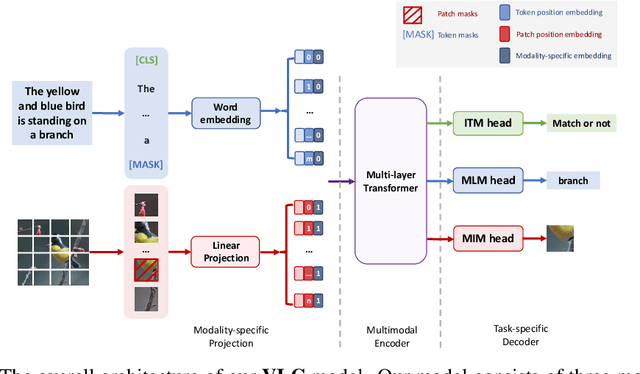
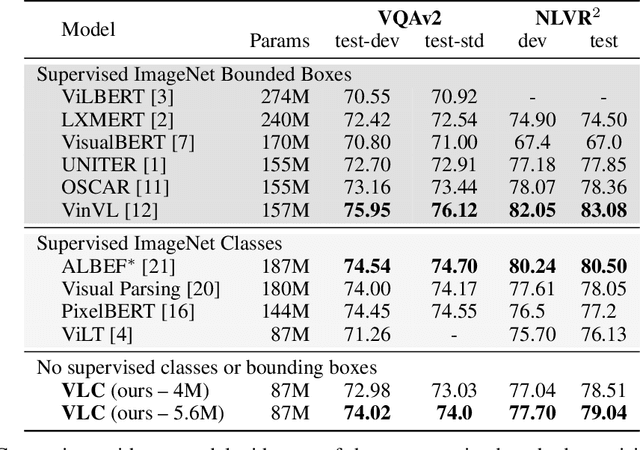
We show that Vision-Language Transformers can be learned without human labels (e.g. class labels, bounding boxes, etc). Existing work, whether explicitly utilizing bounding boxes or patches, assumes that the visual backbone must first be trained on ImageNet class prediction before being integrated into a multimodal linguistic pipeline. We show that this is not necessary and introduce a new model Vision-Language from Captions (VLC) built on top of Masked Auto-Encoders that does not require this supervision. In fact, in a head-to-head comparison between ViLT, the current state-of-the-art patch-based vision-language transformer which is pretrained with supervised object classification, and our model, VLC, we find that our approach 1. outperforms ViLT on standard benchmarks, 2. provides more interpretable and intuitive patch visualizations, and 3. is competitive with many larger models that utilize ROIs trained on annotated bounding-boxes.
KAT: A Knowledge Augmented Transformer for Vision-and-Language
Dec 16, 2021
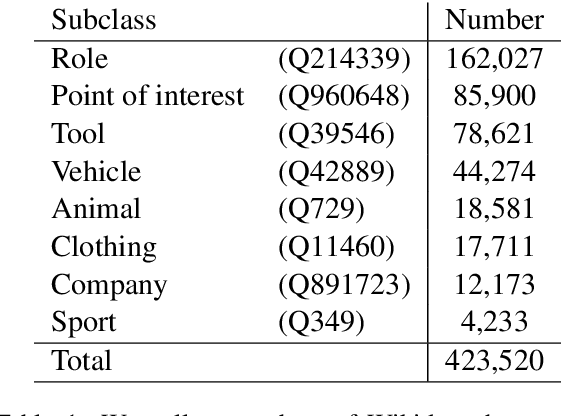
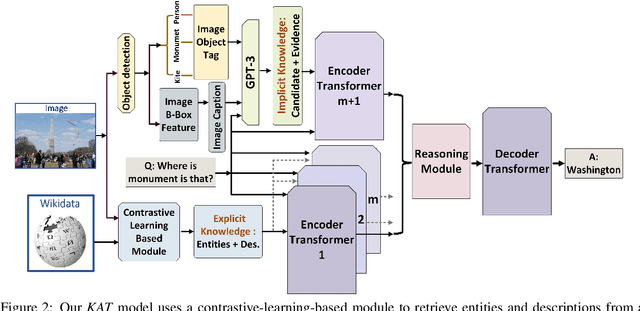
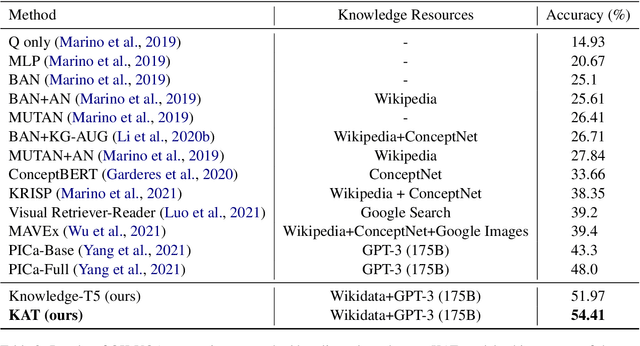
The primary focus of recent work with largescale transformers has been on optimizing the amount of information packed into the model's parameters. In this work, we ask a different question: Can multimodal transformers leverage explicit knowledge in their reasoning? Existing, primarily unimodal, methods have explored approaches under the paradigm of knowledge retrieval followed by answer prediction, but leave open questions about the quality and relevance of the retrieved knowledge used, and how the reasoning processes over implicit and explicit knowledge should be integrated. To address these challenges, we propose a novel model - Knowledge Augmented Transformer (KAT) - which achieves a strong state-of-the-art result (+6 points absolute) on the open-domain multimodal task of OK-VQA. Our approach integrates implicit and explicit knowledge in an end to end encoder-decoder architecture, while still jointly reasoning over both knowledge sources during answer generation. An additional benefit of explicit knowledge integration is seen in improved interpretability of model predictions in our analysis.
Natural- to formal-language generation using Tensor Product Representations
Oct 05, 2019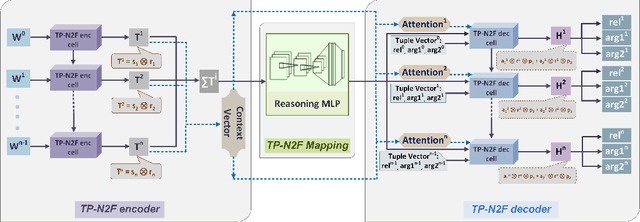


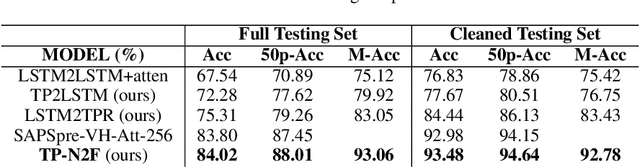
Generating formal-language represented by relational tuples, such as Lisp programs or mathematical expressions, from a natural-language input is an extremely challenging task because it requires to explicitly capture discrete symbolic structural information from the input to generate the output. Most state-of-the-art neural sequence models do not explicitly capture such structure information, and thus do not perform well on these tasks. In this paper, we propose a new encoder-decoder model based on Tensor Product Representations (TPRs) for Natural- to Formal-language generation, called TP-N2F. The encoder of TP-N2F employs TPR 'binding' to encode natural-language symbolic structure in vector space and the decoder uses TPR 'unbinding' to generate a sequence of relational tuples, each consisting of a relation (or operation) and a number of arguments, in symbolic space. TP-N2F considerably outperforms LSTM-based Seq2Seq models, creating a new state of the art results on two benchmarks: the MathQA dataset for math problem solving, and the AlgoList dataset for program synthesis. Ablation studies show that improvements are mainly attributed to the use of TPRs in both the encoder and decoder to explicitly capture relational structure information for symbolic reasoning.