 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDYSTIL: Dynamic Strategy Induction with Large Language Models for Reinforcement Learning
May 06, 2025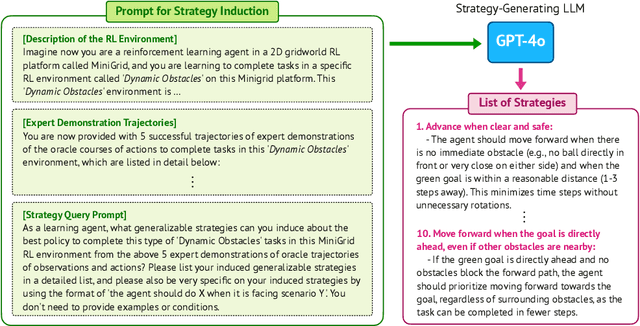
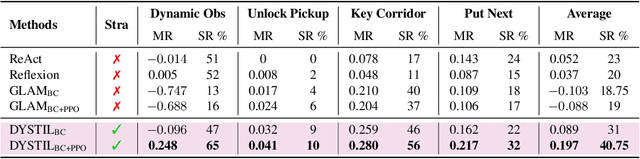
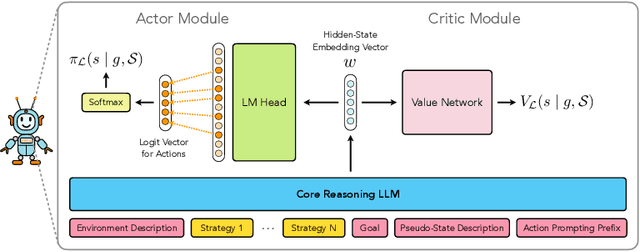

Reinforcement learning from expert demonstrations has long remained a challenging research problem, and existing state-of-the-art methods using behavioral cloning plus further RL training often suffer from poor generalization, low sample efficiency, and poor model interpretability. Inspired by the strong reasoning abilities of large language models (LLMs), we propose a novel strategy-based reinforcement learning framework integrated with LLMs called DYnamic STrategy Induction with Llms for reinforcement learning (DYSTIL) to overcome these limitations. DYSTIL dynamically queries a strategy-generating LLM to induce textual strategies based on advantage estimations and expert demonstrations, and gradually internalizes induced strategies into the RL agent through policy optimization to improve its performance through boosting policy generalization and enhancing sample efficiency. It also provides a direct textual channel to observe and interpret the evolution of the policy's underlying strategies during training. We test DYSTIL over challenging RL environments from Minigrid and BabyAI, and empirically demonstrate that DYSTIL significantly outperforms state-of-the-art baseline methods by 17.75% in average success rate while also enjoying higher sample efficiency during the learning process.
STRUDEL: Structured Dialogue Summarization for Dialogue Comprehension
Dec 24, 2022



Abstractive dialogue summarization has long been viewed as an important standalone task in natural language processing, but no previous work has explored the possibility of whether abstractive dialogue summarization can also be used as a means to boost an NLP system's performance on other important dialogue comprehension tasks. In this paper, we propose a novel type of dialogue summarization task - STRUctured DiaLoguE Summarization - that can help pre-trained language models to better understand dialogues and improve their performance on important dialogue comprehension tasks. We further collect human annotations of STRUDEL summaries over 400 dialogues and introduce a new STRUDEL dialogue comprehension modeling framework that integrates STRUDEL into a graph-neural-network-based dialogue reasoning module over transformer encoder language models to improve their dialogue comprehension abilities. In our empirical experiments on two important downstream dialogue comprehension tasks - dialogue question answering and dialogue response prediction - we show that our STRUDEL dialogue comprehension model can significantly improve the dialogue comprehension performance of transformer encoder language models.
CONFIT: Toward Faithful Dialogue Summarization with Linguistically-Informed Contrastive Fine-tuning
Dec 16, 2021
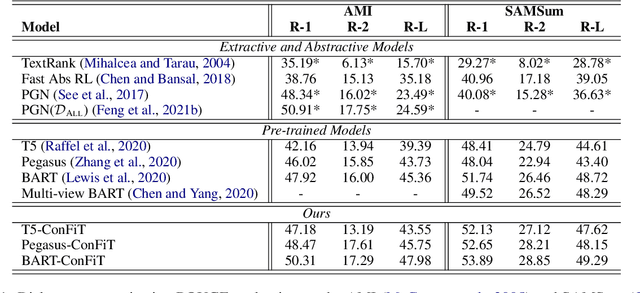
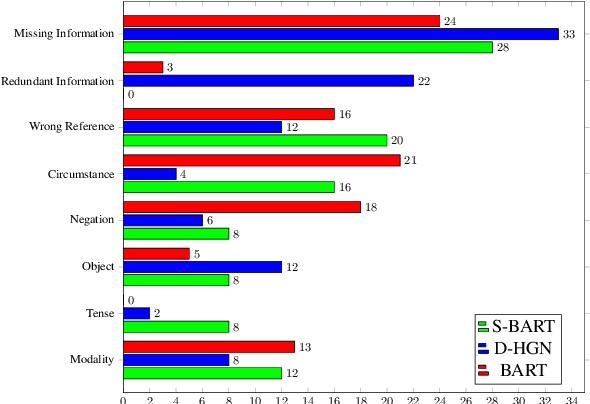
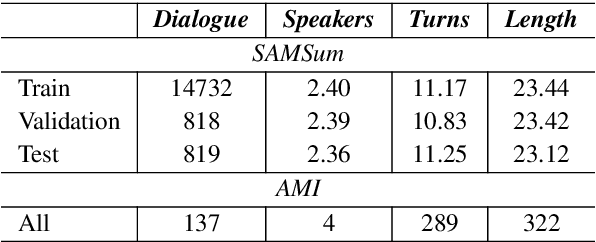
Factual inconsistencies in generated summaries severely limit the practical applications of abstractive dialogue summarization. Although significant progress has been achieved by using pre-trained models, substantial amounts of hallucinated content are found during the human evaluation. Pre-trained models are most commonly fine-tuned with cross-entropy loss for text summarization, which may not be an optimal strategy. In this work, we provide a typology of factual errors with annotation data to highlight the types of errors and move away from a binary understanding of factuality. We further propose a training strategy that improves the factual consistency and overall quality of summaries via a novel contrastive fine-tuning, called ConFiT. Based on our linguistically-informed typology of errors, we design different modular objectives that each target a specific type. Specifically, we utilize hard negative samples with errors to reduce the generation of factual inconsistency. In order to capture the key information between speakers, we also design a dialogue-specific loss. Using human evaluation and automatic faithfulness metrics, we show that our model significantly reduces all kinds of factual errors on the dialogue summarization, SAMSum corpus. Moreover, our model could be generalized to the meeting summarization, AMI corpus, and it produces significantly higher scores than most of the baselines on both datasets regarding word-overlap metrics.
KAT: A Knowledge Augmented Transformer for Vision-and-Language
Dec 16, 2021
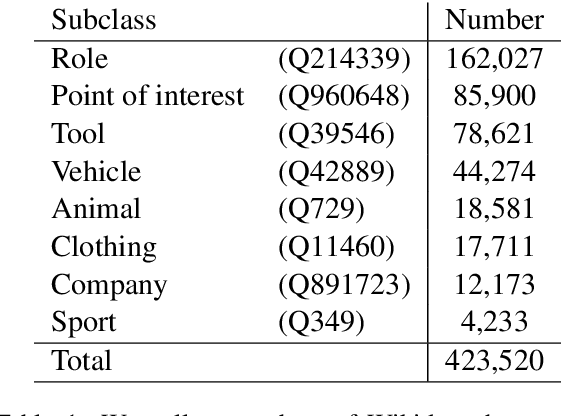
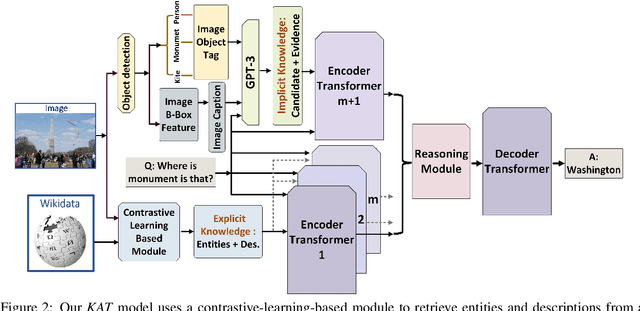
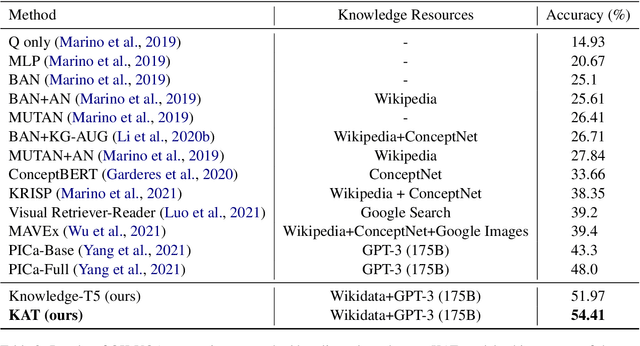
The primary focus of recent work with largescale transformers has been on optimizing the amount of information packed into the model's parameters. In this work, we ask a different question: Can multimodal transformers leverage explicit knowledge in their reasoning? Existing, primarily unimodal, methods have explored approaches under the paradigm of knowledge retrieval followed by answer prediction, but leave open questions about the quality and relevance of the retrieved knowledge used, and how the reasoning processes over implicit and explicit knowledge should be integrated. To address these challenges, we propose a novel model - Knowledge Augmented Transformer (KAT) - which achieves a strong state-of-the-art result (+6 points absolute) on the open-domain multimodal task of OK-VQA. Our approach integrates implicit and explicit knowledge in an end to end encoder-decoder architecture, while still jointly reasoning over both knowledge sources during answer generation. An additional benefit of explicit knowledge integration is seen in improved interpretability of model predictions in our analysis.
Investigating Crowdsourcing Protocols for Evaluating the Factual Consistency of Summaries
Sep 21, 2021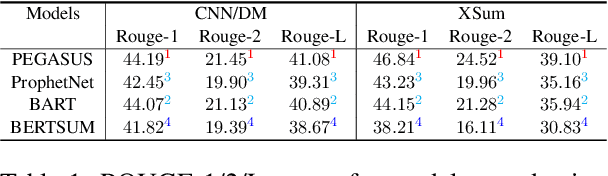
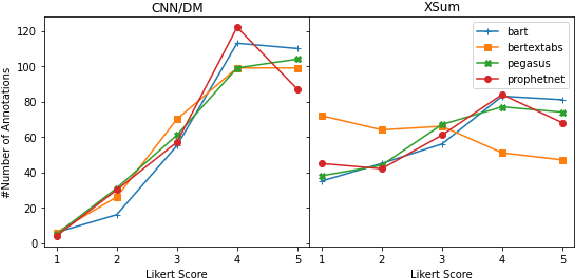
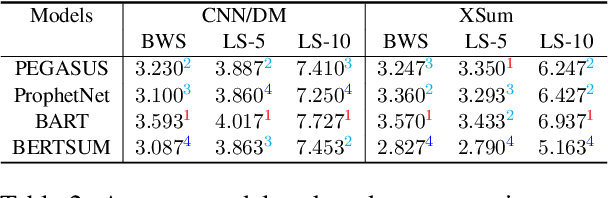
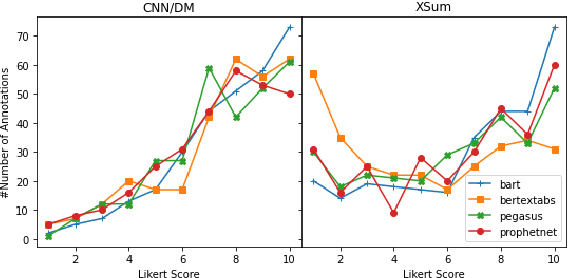
Current pre-trained models applied to summarization are prone to factual inconsistencies which either misrepresent the source text or introduce extraneous information. Thus, comparing the factual consistency of summaries is necessary as we develop improved models. However, the optimal human evaluation setup for factual consistency has not been standardized. To address this issue, we crowdsourced evaluations for factual consistency using the rating-based Likert scale and ranking-based Best-Worst Scaling protocols, on 100 articles from each of the CNN-Daily Mail and XSum datasets over four state-of-the-art models, to determine the most reliable evaluation framework. We find that ranking-based protocols offer a more reliable measure of summary quality across datasets, while the reliability of Likert ratings depends on the target dataset and the evaluation design. Our crowdsourcing templates and summary evaluations will be publicly available to facilitate future research on factual consistency in summarization.
ConvoSumm: Conversation Summarization Benchmark and Improved Abstractive Summarization with Argument Mining
Jun 01, 2021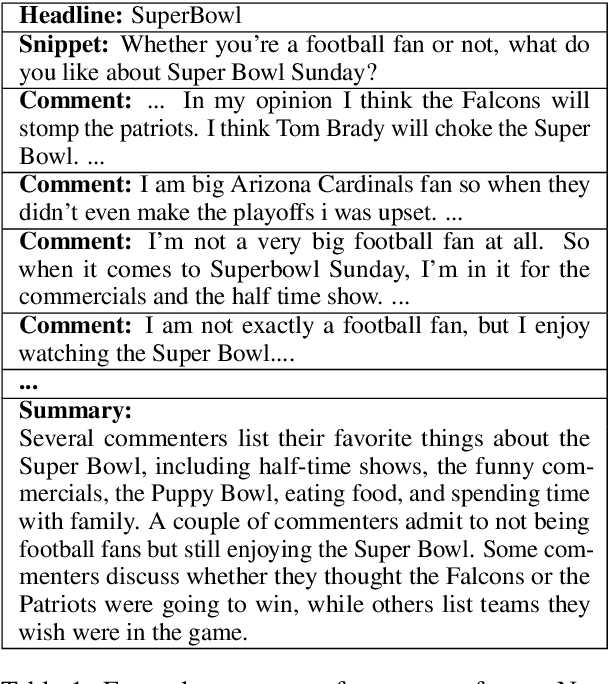
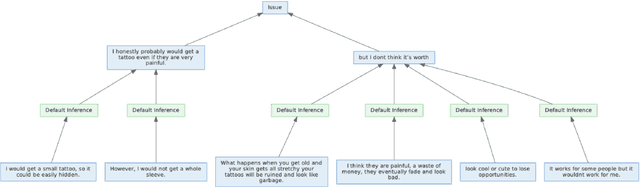


While online conversations can cover a vast amount of information in many different formats, abstractive text summarization has primarily focused on modeling solely news articles. This research gap is due, in part, to the lack of standardized datasets for summarizing online discussions. To address this gap, we design annotation protocols motivated by an issues--viewpoints--assertions framework to crowdsource four new datasets on diverse online conversation forms of news comments, discussion forums, community question answering forums, and email threads. We benchmark state-of-the-art models on our datasets and analyze characteristics associated with the data. To create a comprehensive benchmark, we also evaluate these models on widely-used conversation summarization datasets to establish strong baselines in this domain. Furthermore, we incorporate argument mining through graph construction to directly model the issues, viewpoints, and assertions present in a conversation and filter noisy input, showing comparable or improved results according to automatic and human evaluations.
Imitation Learning for Human Pose Prediction
Sep 08, 2019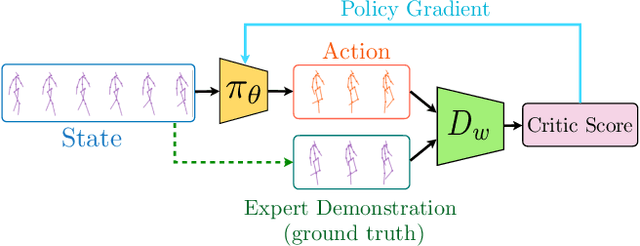
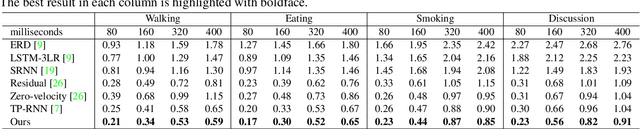
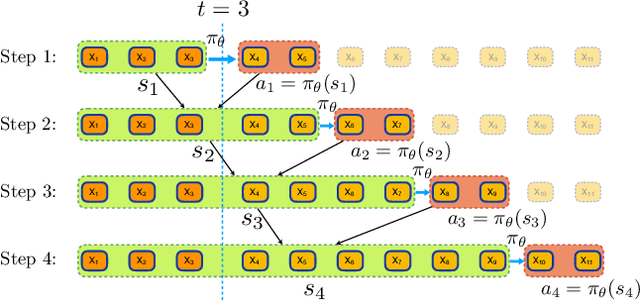
Modeling and prediction of human motion dynamics has long been a challenging problem in computer vision, and most existing methods rely on the end-to-end supervised training of various architectures of recurrent neural networks. Inspired by the recent success of deep reinforcement learning methods, in this paper we propose a new reinforcement learning formulation for the problem of human pose prediction, and develop an imitation learning algorithm for predicting future poses under this formulation through a combination of behavioral cloning and generative adversarial imitation learning. Our experiments show that our proposed method outperforms all existing state-of-the-art baseline models by large margins on the task of human pose prediction in both short-term predictions and long-term predictions, while also enjoying huge advantage in training speed.
Action-Agnostic Human Pose Forecasting
Oct 23, 2018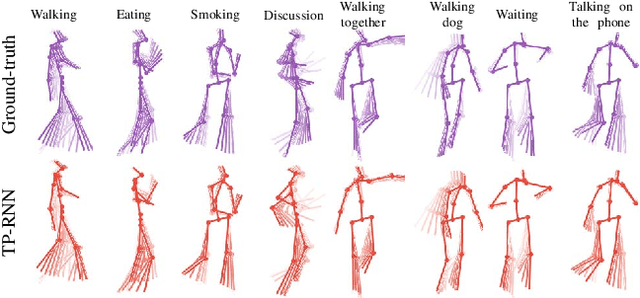
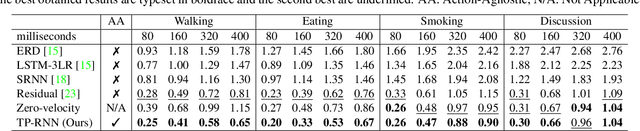
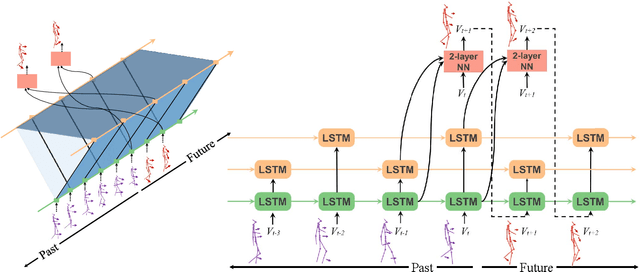
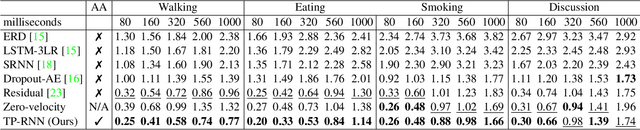
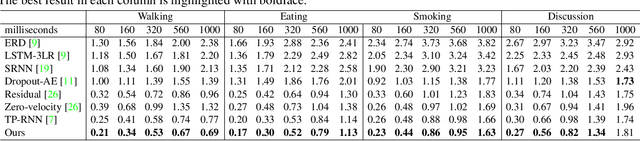
Predicting and forecasting human dynamics is a very interesting but challenging task with several prospective applications in robotics, health-care, etc. Recently, several methods have been developed for human pose forecasting; however, they often introduce a number of limitations in their settings. For instance, previous work either focused only on short-term or long-term predictions, while sacrificing one or the other. Furthermore, they included the activity labels as part of the training process, and require them at testing time. These limitations confine the usage of pose forecasting models for real-world applications, as often there are no activity-related annotations for testing scenarios. In this paper, we propose a new action-agnostic method for short- and long-term human pose forecasting. To this end, we propose a new recurrent neural network for modeling the hierarchical and multi-scale characteristics of the human dynamics, denoted by triangular-prism RNN (TP-RNN). Our model captures the latent hierarchical structure embedded in temporal human pose sequences by encoding the temporal dependencies with different time-scales. For evaluation, we run an extensive set of experiments on Human 3.6M and Penn Action datasets and show that our method outperforms baseline and state-of-the-art methods quantitatively and qualitatively. Codes are available at https://github.com/eddyhkchiu/pose_forecast_wacv/
Learning General Latent-Variable Graphical Models with Predictive Belief Propagation and Hilbert Space Embeddings
Dec 06, 2017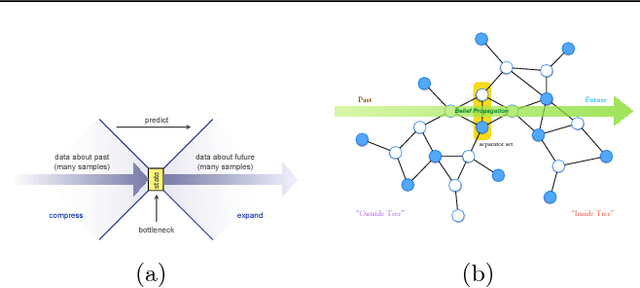
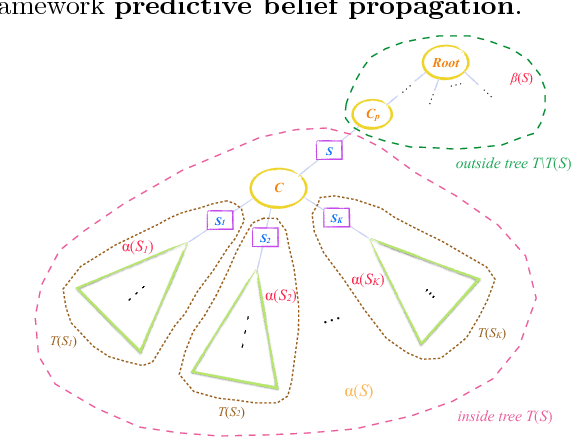
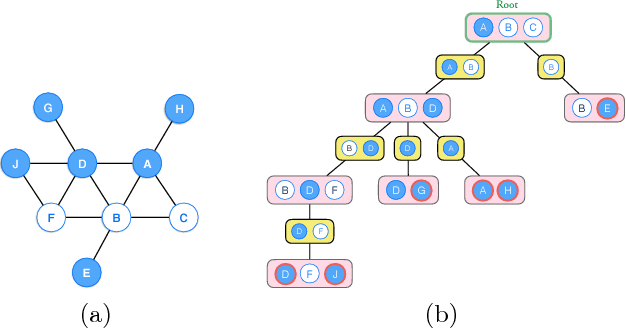
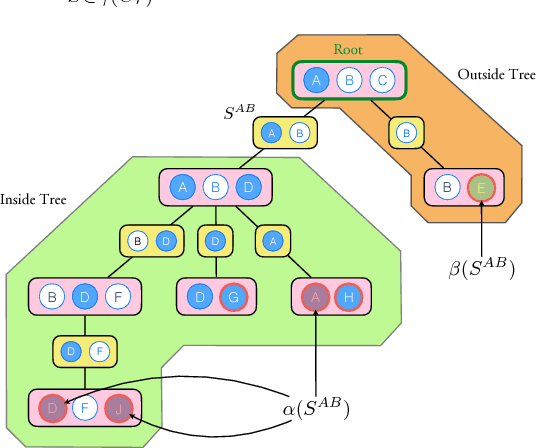
In this paper, we propose a new algorithm for learning general latent-variable probabilistic graphical models using the techniques of predictive state representation, instrumental variable regression, and reproducing-kernel Hilbert space embeddings of distributions. Under this new learning framework, we first convert latent-variable graphical models into corresponding latent-variable junction trees, and then reduce the hard parameter learning problem into a pipeline of supervised learning problems, whose results will then be used to perform predictive belief propagation over the latent junction tree during the actual inference procedure. We then give proofs of our algorithm's correctness, and demonstrate its good performance in experiments on one synthetic dataset and two real-world tasks from computational biology and computer vision - classifying DNA splice junctions and recognizing human actions in videos.