 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRUDEL: Structured Dialogue Summarization for Dialogue Comprehension
Dec 24, 2022



Abstractive dialogue summarization has long been viewed as an important standalone task in natural language processing, but no previous work has explored the possibility of whether abstractive dialogue summarization can also be used as a means to boost an NLP system's performance on other important dialogue comprehension tasks. In this paper, we propose a novel type of dialogue summarization task - STRUctured DiaLoguE Summarization - that can help pre-trained language models to better understand dialogues and improve their performance on important dialogue comprehension tasks. We further collect human annotations of STRUDEL summaries over 400 dialogues and introduce a new STRUDEL dialogue comprehension modeling framework that integrates STRUDEL into a graph-neural-network-based dialogue reasoning module over transformer encoder language models to improve their dialogue comprehension abilities. In our empirical experiments on two important downstream dialogue comprehension tasks - dialogue question answering and dialogue response prediction - we show that our STRUDEL dialogue comprehension model can significantly improve the dialogue comprehension performance of transformer encoder language models.
CONFIT: Toward Faithful Dialogue Summarization with Linguistically-Informed Contrastive Fine-tuning
Dec 16, 2021
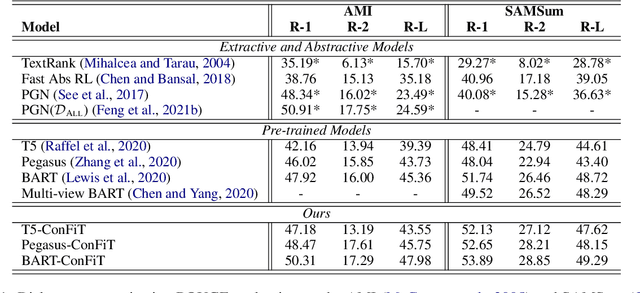
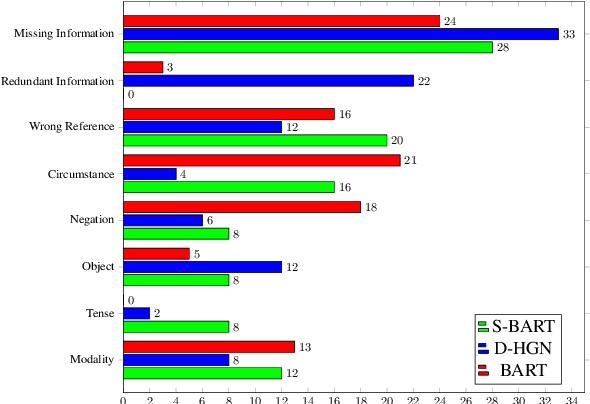
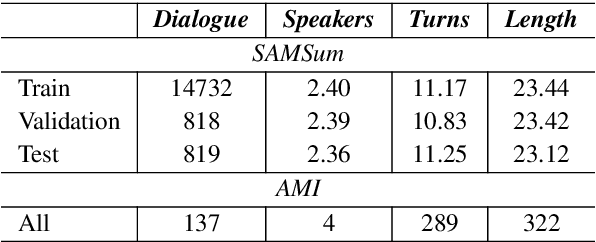
Factual inconsistencies in generated summaries severely limit the practical applications of abstractive dialogue summarization. Although significant progress has been achieved by using pre-trained models, substantial amounts of hallucinated content are found during the human evaluation. Pre-trained models are most commonly fine-tuned with cross-entropy loss for text summarization, which may not be an optimal strategy. In this work, we provide a typology of factual errors with annotation data to highlight the types of errors and move away from a binary understanding of factuality. We further propose a training strategy that improves the factual consistency and overall quality of summaries via a novel contrastive fine-tuning, called ConFiT. Based on our linguistically-informed typology of errors, we design different modular objectives that each target a specific type. Specifically, we utilize hard negative samples with errors to reduce the generation of factual inconsistency. In order to capture the key information between speakers, we also design a dialogue-specific loss. Using human evaluation and automatic faithfulness metrics, we show that our model significantly reduces all kinds of factual errors on the dialogue summarization, SAMSum corpus. Moreover, our model could be generalized to the meeting summarization, AMI corpus, and it produces significantly higher scores than most of the baselines on both datasets regarding word-overlap metrics.