 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Masked Video Consistency for Unsupervised Domain Adaptation
Mar 24, 2024



We study the problem of unsupervised domain adaptation for egocentric videos. We propose a transformer-based model to learn class-discriminative and domain-invariant feature representations. It consists of two novel designs. The first module is called Generative Adversarial Domain Alignment Network with the aim of learning domain-invariant representations. It simultaneously learns a mask generator and a domain-invariant encoder in an adversarial way. The domain-invariant encoder is trained to minimize the distance between the source and target domain. The masking generator, conversely, aims at producing challenging masks by maximizing the domain distance. The second is a Masked Consistency Learning module to learn class-discriminative representations. It enforces the prediction consistency between the masked target videos and their full forms. To better evaluate the effectiveness of domain adaptation methods, we construct a more challenging benchmark for egocentric videos, U-Ego4D. Our method achieves state-of-the-art performance on the Epic-Kitchen and the proposed U-Ego4D benchmark.
Training Vision-Language Transformers from Captions Alone
May 19, 2022
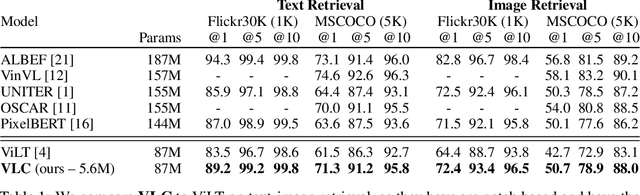
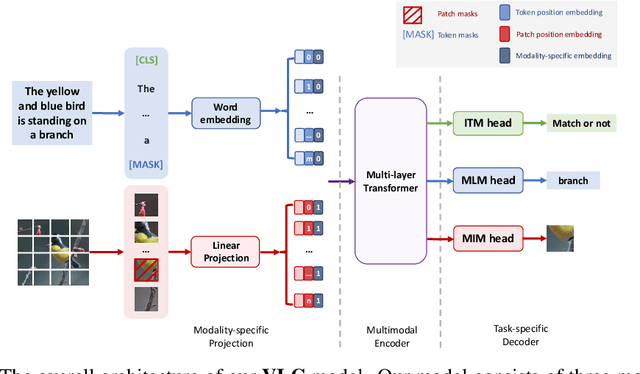
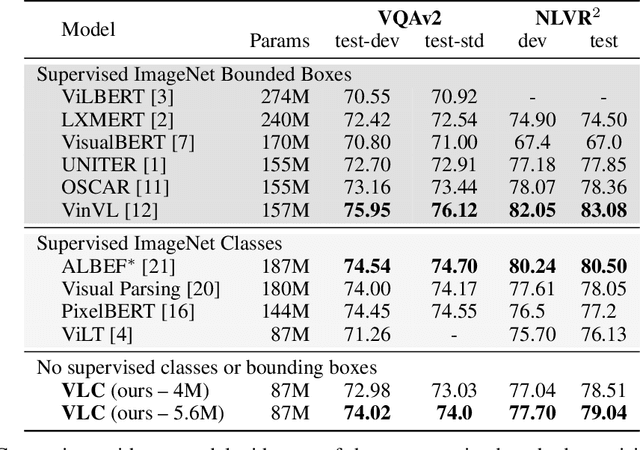
We show that Vision-Language Transformers can be learned without human labels (e.g. class labels, bounding boxes, etc). Existing work, whether explicitly utilizing bounding boxes or patches, assumes that the visual backbone must first be trained on ImageNet class prediction before being integrated into a multimodal linguistic pipeline. We show that this is not necessary and introduce a new model Vision-Language from Captions (VLC) built on top of Masked Auto-Encoders that does not require this supervision. In fact, in a head-to-head comparison between ViLT, the current state-of-the-art patch-based vision-language transformer which is pretrained with supervised object classification, and our model, VLC, we find that our approach 1. outperforms ViLT on standard benchmarks, 2. provides more interpretable and intuitive patch visualizations, and 3. is competitive with many larger models that utilize ROIs trained on annotated bounding-boxes.
KAT: A Knowledge Augmented Transformer for Vision-and-Language
Dec 16, 2021
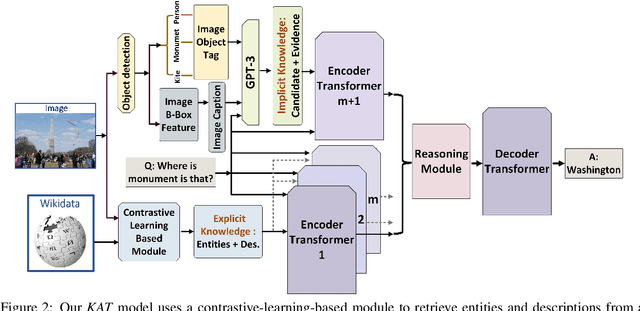
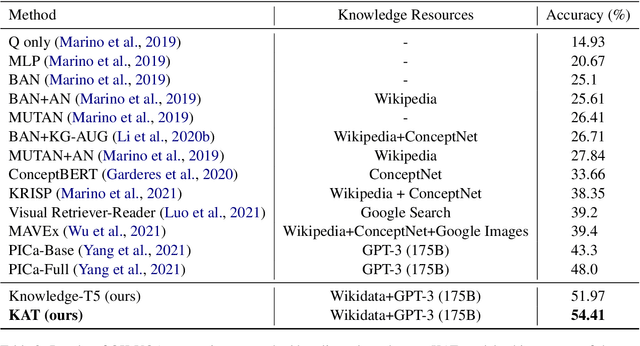
The primary focus of recent work with largescale transformers has been on optimizing the amount of information packed into the model's parameters. In this work, we ask a different question: Can multimodal transformers leverage explicit knowledge in their reasoning? Existing, primarily unimodal, methods have explored approaches under the paradigm of knowledge retrieval followed by answer prediction, but leave open questions about the quality and relevance of the retrieved knowledge used, and how the reasoning processes over implicit and explicit knowledge should be integrated. To address these challenges, we propose a novel model - Knowledge Augmented Transformer (KAT) - which achieves a strong state-of-the-art result (+6 points absolute) on the open-domain multimodal task of OK-VQA. Our approach integrates implicit and explicit knowledge in an end to end encoder-decoder architecture, while still jointly reasoning over both knowledge sources during answer generation. An additional benefit of explicit knowledge integration is seen in improved interpretability of model predictions in our analysis.
Person Search Challenges and Solutions: A Survey
May 01, 2021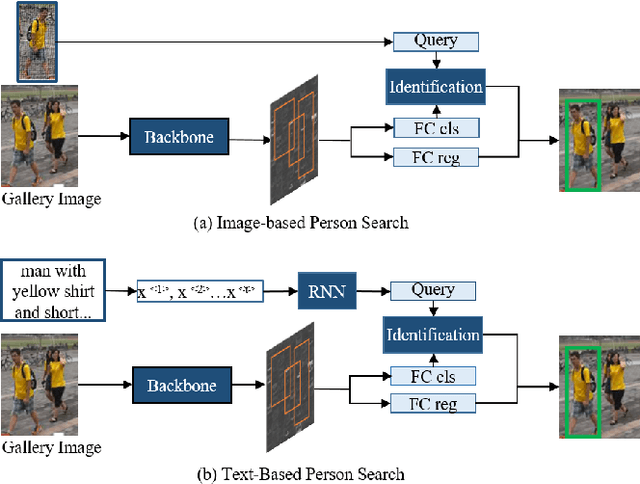
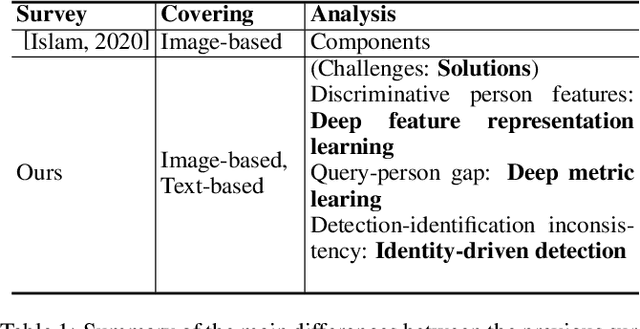

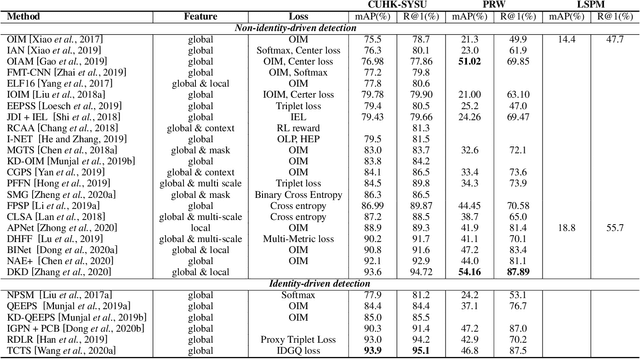
Person search has drawn increasing attention due to its real-world applications and research significance. Person search aims to find a probe person in a gallery of scene images with a wide range of applications, such as criminals search, multicamera tracking, missing person search, etc. Early person search works focused on image-based person search, which uses person image as the search query. Text-based person search is another major person search category that uses free-form natural language as the search query. Person search is challenging, and corresponding solutions are diverse and complex. Therefore, systematic surveys on this topic are essential. This paper surveyed the recent works on image-based and text-based person search from the perspective of challenges and solutions. Specifically, we provide a brief analysis of highly influential person search methods considering the three significant challenges: the discriminative person features, the query-person gap, and the detection-identification inconsistency. We summarise and compare evaluation results. Finally, we discuss open issues and some promising future research directions.
Scene Graphs: A Survey of Generations and Applications
Mar 17, 2021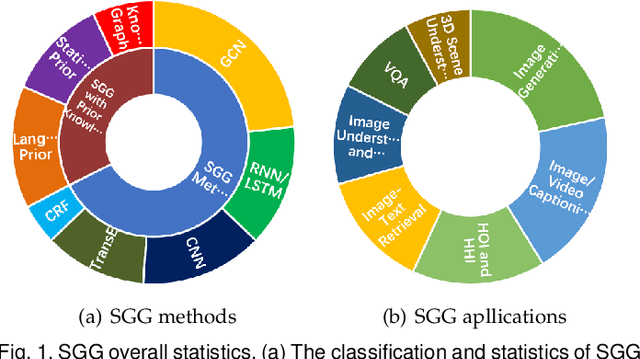

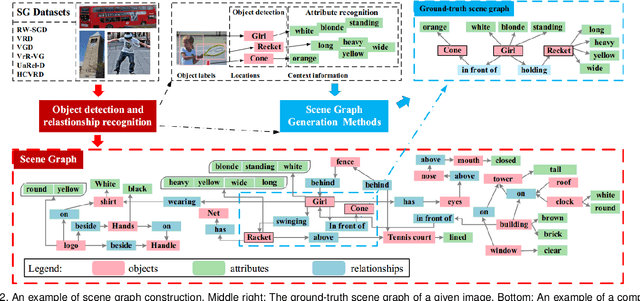
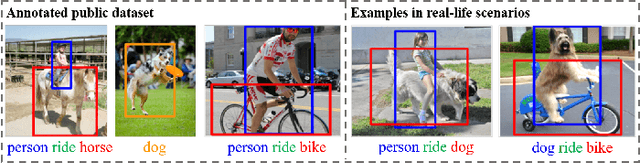
Scene graph is a structured representation of a scene that can clearly express the objects, attributes, and relationships between objects in the scene. As computer vision technology continues to develop, people are no longer satisfied with simply detecting and recognizing objects in images; instead, people look forward to a higher level of understanding and reasoning about visual scenes. For example, given an image, we want to not only detect and recognize objects in the image, but also know the relationship between objects (visual relationship detection), and generate a text description (image captioning) based on the image content. Alternatively, we might want the machine to tell us what the little girl in the image is doing (Visual Question Answering (VQA)), or even remove the dog from the image and find similar images (image editing and retrieval), etc. These tasks require a higher level of understanding and reasoning for image vision tasks. The scene graph is just such a powerful tool for scene understanding. Therefore, scene graphs have attracted the attention of a large number of researchers, and related research is often cross-modal, complex, and rapidly developing. However, no relatively systematic survey of scene graphs exists at present. To this end, this survey conducts a comprehensive investigation of the current scene graph research. More specifically, we first summarized the general definition of the scene graph, then conducted a comprehensive and systematic discussion on the generation method of the scene graph (SGG) and the SGG with the aid of prior knowledge. We then investigated the main applications of scene graphs and summarized the most commonly used datasets. Finally, we provide some insights into the future development of scene graphs. We believe this will be a very helpful foundation for future research on scene graphs.