 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Vision-Language Transformers from Captions Alone
Paper and Code

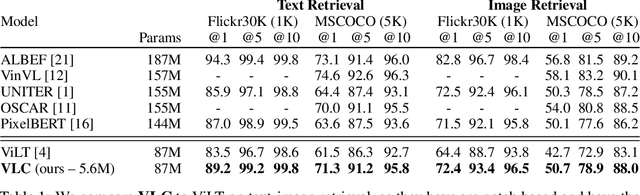
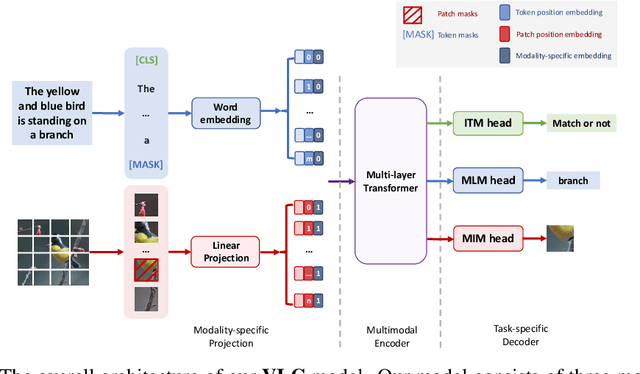
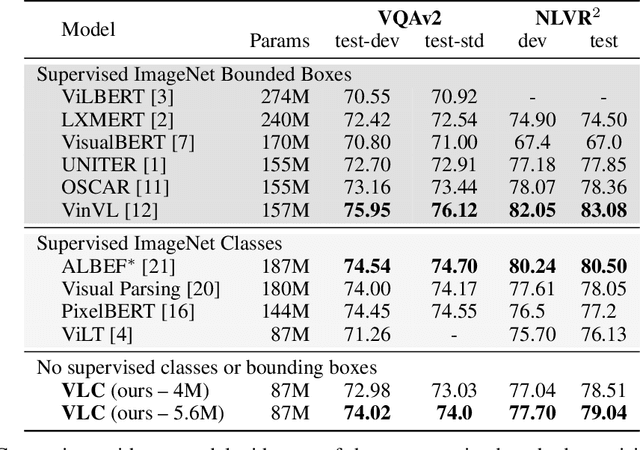
We show that Vision-Language Transformers can be learned without human labels (e.g. class labels, bounding boxes, etc). Existing work, whether explicitly utilizing bounding boxes or patches, assumes that the visual backbone must first be trained on ImageNet class prediction before being integrated into a multimodal linguistic pipeline. We show that this is not necessary and introduce a new model Vision-Language from Captions (VLC) built on top of Masked Auto-Encoders that does not require this supervision. In fact, in a head-to-head comparison between ViLT, the current state-of-the-art patch-based vision-language transformer which is pretrained with supervised object classification, and our model, VLC, we find that our approach 1. outperforms ViLT on standard benchmarks, 2. provides more interpretable and intuitive patch visualizations, and 3. is competitive with many larger models that utilize ROIs trained on annotated bounding-boxes.