 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
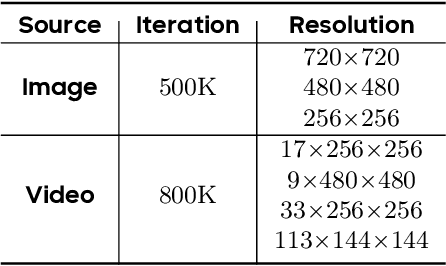
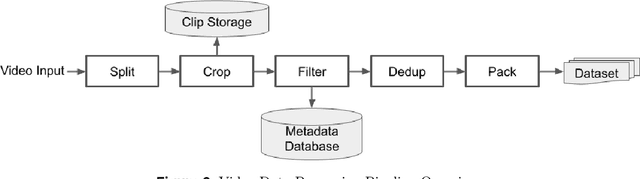

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
CameraCtrl II: Dynamic Scene Exploration via Camera-controlled Video Diffusion Models
Mar 13, 2025This paper introduces CameraCtrl II, a framework that enables large-scale dynamic scene exploration through a camera-controlled video diffusion model. Previous camera-conditioned video generative models suffer from diminished video dynamics and limited range of viewpoints when generating videos with large camera movement. We take an approach that progressively expands the generation of dynamic scenes -- first enhancing dynamic content within individual video clip, then extending this capability to create seamless explorations across broad viewpoint ranges. Specifically, we construct a dataset featuring a large degree of dynamics with camera parameter annotations for training while designing a lightweight camera injection module and training scheme to preserve dynamics of the pretrained models. Building on these improved single-clip techniques, we enable extended scene exploration by allowing users to iteratively specify camera trajectories for generating coherent video sequences. Experiments across diverse scenarios demonstrate that CameraCtrl Ii enables camera-controlled dynamic scene synthesis with substantially wider spatial exploration than previous approaches.
VideoAuteur: Towards Long Narrative Video Generation
Jan 10, 2025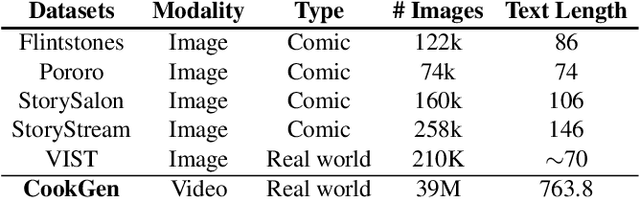



Recent video generation models have shown promising results in producing high-quality video clips lasting several seconds. However, these models face challenges in generating long sequences that convey clear and informative events, limiting their ability to support coherent narrations. In this paper, we present a large-scale cooking video dataset designed to advance long-form narrative generation in the cooking domain. We validate the quality of our proposed dataset in terms of visual fidelity and textual caption accuracy using state-of-the-art Vision-Language Models (VLMs) and video generation models, respectively. We further introduce a Long Narrative Video Director to enhance both visual and semantic coherence in generated videos and emphasize the role of aligning visual embeddings to achieve improved overall video quality. Our method demonstrates substantial improvements in generating visually detailed and semantically aligned keyframes, supported by finetuning techniques that integrate text and image embeddings within the video generation process. Project page: https://videoauteur.github.io/
Is Your Text-to-Image Model Robust to Caption Noise?
Dec 27, 2024In text-to-image (T2I) generation, a prevalent training technique involves utilizing Vision Language Models (VLMs) for image re-captioning. Even though VLMs are known to exhibit hallucination, generating descriptive content that deviates from the visual reality, the ramifications of such caption hallucinations on T2I generation performance remain under-explored. Through our empirical investigation, we first establish a comprehensive dataset comprising VLM-generated captions, and then systematically analyze how caption hallucination influences generation outcomes. Our findings reveal that (1) the disparities in caption quality persistently impact model outputs during fine-tuning. (2) VLMs confidence scores serve as reliable indicators for detecting and characterizing noise-related patterns in the data distribution. (3) even subtle variations in caption fidelity have significant effects on the quality of learned representations. These findings collectively emphasize the profound impact of caption quality on model performance and highlight the need for more sophisticated robust training algorithm in T2I. In response to these observations, we propose a approach leveraging VLM confidence score to mitigate caption noise, thereby enhancing the robustness of T2I models against hallucination in caption.
Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward
Apr 02, 2024



Preference modeling techniques, such as direct preference optimization (DPO), has shown effective in enhancing the generalization abilities of large language model (LLM). However, in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge. Previous studies have explored using large large multimodal models (LMMs) as reward models to guide preference modeling, but their ability to accurately assess the factuality of generated responses compared to corresponding videos has not been conclusively established. This paper introduces a novel framework that utilizes detailed video captions as a proxy of video content, enabling language models to incorporate this information as supporting evidence for scoring video Question Answering (QA) predictions. Our approach demonstrates robust alignment with OpenAI GPT-4V model's reward mechanism, which directly takes video frames as input. Furthermore, we show that applying this tailored reward through DPO significantly improves the performance of video LMMs on video QA tasks.
Mega: Moving Average Equipped Gated Attention
Sep 26, 2022
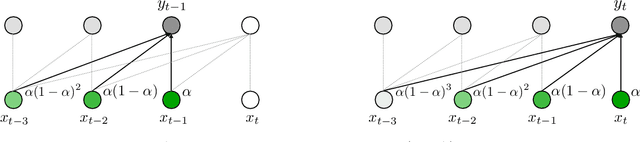
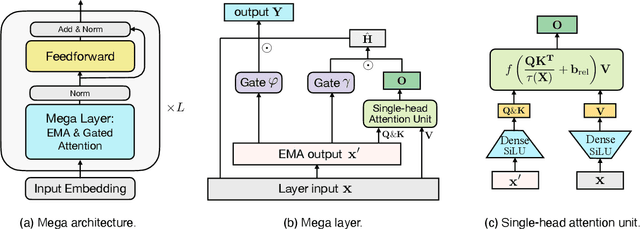
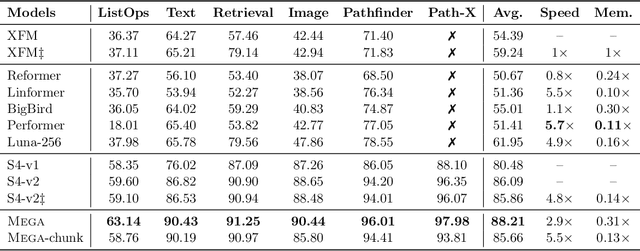
The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. In this paper, we introduce Mega, a simple, theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. We further propose a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length. Extensive experiments on a wide range of sequence modeling benchmarks, including the Long Range Arena, neural machine translation, auto-regressive language modeling, and image and speech classification, show that Mega achieves significant improvements over other sequence models, including variants of Transformers and recent state space models.
Training Vision-Language Transformers from Captions Alone
May 19, 2022
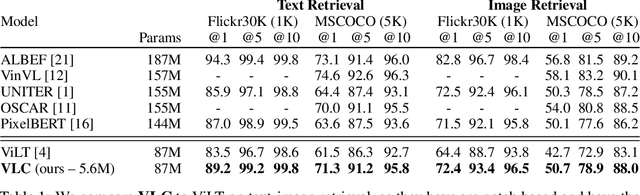
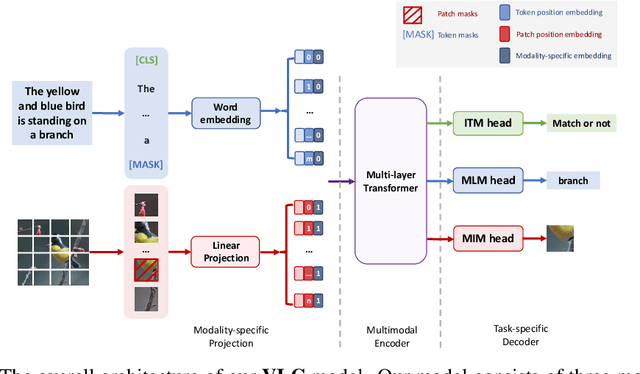
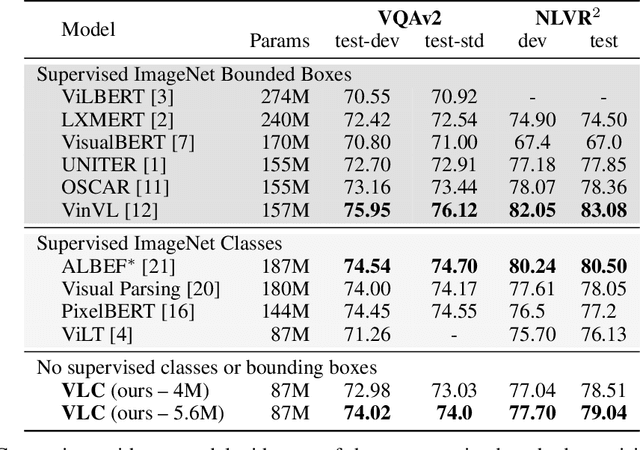
We show that Vision-Language Transformers can be learned without human labels (e.g. class labels, bounding boxes, etc). Existing work, whether explicitly utilizing bounding boxes or patches, assumes that the visual backbone must first be trained on ImageNet class prediction before being integrated into a multimodal linguistic pipeline. We show that this is not necessary and introduce a new model Vision-Language from Captions (VLC) built on top of Masked Auto-Encoders that does not require this supervision. In fact, in a head-to-head comparison between ViLT, the current state-of-the-art patch-based vision-language transformer which is pretrained with supervised object classification, and our model, VLC, we find that our approach 1. outperforms ViLT on standard benchmarks, 2. provides more interpretable and intuitive patch visualizations, and 3. is competitive with many larger models that utilize ROIs trained on annotated bounding-boxes.
KAT: A Knowledge Augmented Transformer for Vision-and-Language
Dec 16, 2021
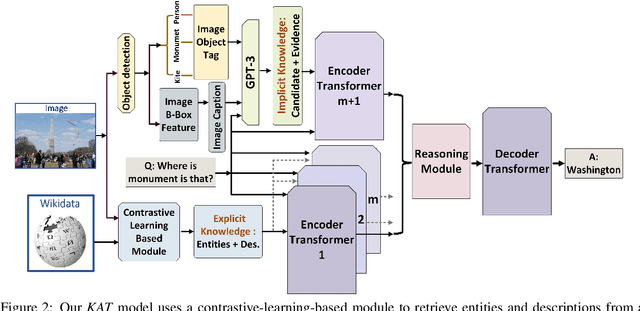
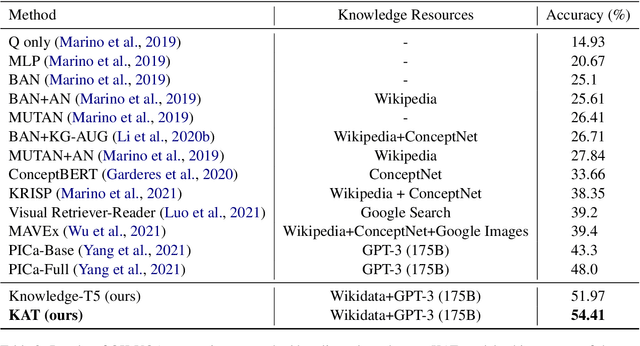
The primary focus of recent work with largescale transformers has been on optimizing the amount of information packed into the model's parameters. In this work, we ask a different question: Can multimodal transformers leverage explicit knowledge in their reasoning? Existing, primarily unimodal, methods have explored approaches under the paradigm of knowledge retrieval followed by answer prediction, but leave open questions about the quality and relevance of the retrieved knowledge used, and how the reasoning processes over implicit and explicit knowledge should be integrated. To address these challenges, we propose a novel model - Knowledge Augmented Transformer (KAT) - which achieves a strong state-of-the-art result (+6 points absolute) on the open-domain multimodal task of OK-VQA. Our approach integrates implicit and explicit knowledge in an end to end encoder-decoder architecture, while still jointly reasoning over both knowledge sources during answer generation. An additional benefit of explicit knowledge integration is seen in improved interpretability of model predictions in our analysis.