 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoom-IQA: Image Quality Assessment with Reliable Region-Aware Reasoning
Jan 06, 2026Image Quality Assessment (IQA) is a long-standing problem in computer vision. Previous methods typically focus on predicting numerical scores without explanation or provide low-level descriptions lacking precise scores. Recent reasoning-based vision language models (VLMs) have shown strong potential for IQA, enabling joint generation of quality descriptions and scores. However, we notice that existing VLM-based IQA methods tend to exhibit unreliable reasoning due to their limited capability of integrating visual and textual cues. In this work, we introduce Zoom-IQA, a VLM-based IQA model to explicitly emulate key cognitive behaviors: uncertainty awareness, region reasoning, and iterative refinement. Specifically, we present a two-stage training pipeline: 1) supervised fine-tuning (SFT) on our Grounded-Rationale-IQA (GR-IQA) dataset to teach the model to ground its assessments in key regions; and 2) reinforcement learning (RL) for dynamic policy exploration, primarily stabilized by our KL-Coverage regularizer to prevent reasoning and scoring diversity collapse, and supported by a Progressive Re-sampling Strategy to mitigate annotation bias. Extensive experiments show that Zoom-IQA achieves improved robustness, explainability, and generalization. The application to downstream tasks, such as image restoration, further demonstrates the effectiveness of Zoom-IQA.
SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training
Jun 05, 2025



Recent advances in diffusion-based video restoration (VR) demonstrate significant improvement in visual quality, yet yield a prohibitive computational cost during inference. While several distillation-based approaches have exhibited the potential of one-step image restoration, extending existing approaches to VR remains challenging and underexplored, particularly when dealing with high-resolution video in real-world settings. In this work, we propose a one-step diffusion-based VR model, termed as SeedVR2, which performs adversarial VR training against real data. To handle the challenging high-resolution VR within a single step, we introduce several enhancements to both model architecture and training procedures. Specifically, an adaptive window attention mechanism is proposed, where the window size is dynamically adjusted to fit the output resolutions, avoiding window inconsistency observed under high-resolution VR using window attention with a predefined window size. To stabilize and improve the adversarial post-training towards VR, we further verify the effectiveness of a series of losses, including a proposed feature matching loss without significantly sacrificing training efficiency. Extensive experiments show that SeedVR2 can achieve comparable or even better performance compared with existing VR approaches in a single step.
SeedVR: Seeding Infinity in Diffusion Transformer Towards Generic Video Restoration
Jan 04, 2025
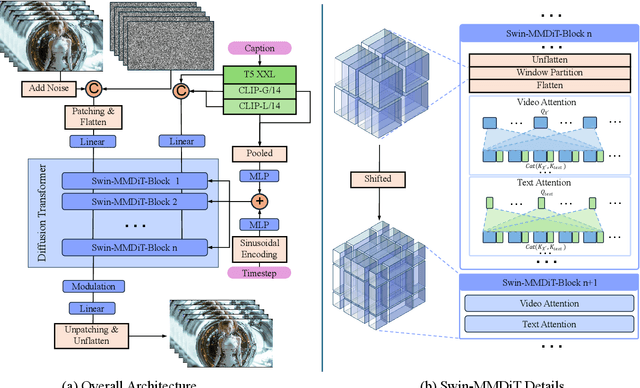


Video restoration poses non-trivial challenges in maintaining fidelity while recovering temporally consistent details from unknown degradations in the wild. Despite recent advances in diffusion-based restoration, these methods often face limitations in generation capability and sampling efficiency. In this work, we present SeedVR, a diffusion transformer designed to handle real-world video restoration with arbitrary length and resolution. The core design of SeedVR lies in the shifted window attention that facilitates effective restoration on long video sequences. SeedVR further supports variable-sized windows near the boundary of both spatial and temporal dimensions, overcoming the resolution constraints of traditional window attention. Equipped with contemporary practices, including causal video autoencoder, mixed image and video training, and progressive training, SeedVR achieves highly-competitive performance on both synthetic and real-world benchmarks, as well as AI-generated videos. Extensive experiments demonstrate SeedVR's superiority over existing methods for generic video restoration.
Is Your Text-to-Image Model Robust to Caption Noise?
Dec 27, 2024In text-to-image (T2I) generation, a prevalent training technique involves utilizing Vision Language Models (VLMs) for image re-captioning. Even though VLMs are known to exhibit hallucination, generating descriptive content that deviates from the visual reality, the ramifications of such caption hallucinations on T2I generation performance remain under-explored. Through our empirical investigation, we first establish a comprehensive dataset comprising VLM-generated captions, and then systematically analyze how caption hallucination influences generation outcomes. Our findings reveal that (1) the disparities in caption quality persistently impact model outputs during fine-tuning. (2) VLMs confidence scores serve as reliable indicators for detecting and characterizing noise-related patterns in the data distribution. (3) even subtle variations in caption fidelity have significant effects on the quality of learned representations. These findings collectively emphasize the profound impact of caption quality on model performance and highlight the need for more sophisticated robust training algorithm in T2I. In response to these observations, we propose a approach leveraging VLM confidence score to mitigate caption noise, thereby enhancing the robustness of T2I models against hallucination in caption.
Efficient Diffusion Model for Image Restoration by Residual Shifting
Mar 12, 2024While diffusion-based image restoration (IR) methods have achieved remarkable success, they are still limited by the low inference speed attributed to the necessity of executing hundreds or even thousands of sampling steps. Existing acceleration sampling techniques, though seeking to expedite the process, inevitably sacrifice performance to some extent, resulting in over-blurry restored outcomes. To address this issue, this study proposes a novel and efficient diffusion model for IR that significantly reduces the required number of diffusion steps. Our method avoids the need for post-acceleration during inference, thereby avoiding the associated performance deterioration. Specifically, our proposed method establishes a Markov chain that facilitates the transitions between the high-quality and low-quality images by shifting their residuals, substantially improving the transition efficiency. A carefully formulated noise schedule is devised to flexibly control the shifting speed and the noise strength during the diffusion process. Extensive experimental evaluations demonstrate that the proposed method achieves superior or comparable performance to current state-of-the-art methods on three classical IR tasks, namely image super-resolution, image inpainting, and blind face restoration, \textit{\textbf{even only with four sampling steps}}. Our code and model are publicly available at \url{https://github.com/zsyOAOA/ResShift}.
Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution
Dec 11, 2023Text-based diffusion models have exhibited remarkable success in generation and editing, showing great promise for enhancing visual content with their generative prior. However, applying these models to video super-resolution remains challenging due to the high demands for output fidelity and temporal consistency, which is complicated by the inherent randomness in diffusion models. Our study introduces Upscale-A-Video, a text-guided latent diffusion framework for video upscaling. This framework ensures temporal coherence through two key mechanisms: locally, it integrates temporal layers into U-Net and VAE-Decoder, maintaining consistency within short sequences; globally, without training, a flow-guided recurrent latent propagation module is introduced to enhance overall video stability by propagating and fusing latent across the entire sequences. Thanks to the diffusion paradigm, our model also offers greater flexibility by allowing text prompts to guide texture creation and adjustable noise levels to balance restoration and generation, enabling a trade-off between fidelity and quality. Extensive experiments show that Upscale-A-Video surpasses existing methods in both synthetic and real-world benchmarks, as well as in AI-generated videos, showcasing impressive visual realism and temporal consistency.
ResShift: Efficient Diffusion Model for Image Super-resolution by Residual Shifting
Jul 25, 2023



Diffusion-based image super-resolution (SR) methods are mainly limited by the low inference speed due to the requirements of hundreds or even thousands of sampling steps. Existing acceleration sampling techniques inevitably sacrifice performance to some extent, leading to over-blurry SR results. To address this issue, we propose a novel and efficient diffusion model for SR that significantly reduces the number of diffusion steps, thereby eliminating the need for post-acceleration during inference and its associated performance deterioration. Our method constructs a Markov chain that transfers between the high-resolution image and the low-resolution image by shifting the residual between them, substantially improving the transition efficiency. Additionally, an elaborate noise schedule is developed to flexibly control the shifting speed and the noise strength during the diffusion process. Extensive experiments demonstrate that the proposed method obtains superior or at least comparable performance to current state-of-the-art methods on both synthetic and real-world datasets, even only with 15 sampling steps. Our code and model are available at https://github.com/zsyOAOA/ResShift.
Exploiting Diffusion Prior for Real-World Image Super-Resolution
May 11, 2023We present a novel approach to leverage prior knowledge encapsulated in pre-trained text-to-image diffusion models for blind super-resolution (SR). Specifically, by employing our time-aware encoder, we can achieve promising restoration results without altering the pre-trained synthesis model, thereby preserving the generative prior and minimizing training cost. To remedy the loss of fidelity caused by the inherent stochasticity of diffusion models, we introduce a controllable feature wrapping module that allows users to balance quality and fidelity by simply adjusting a scalar value during the inference process. Moreover, we develop a progressive aggregation sampling strategy to overcome the fixed-size constraints of pre-trained diffusion models, enabling adaptation to resolutions of any size. A comprehensive evaluation of our method using both synthetic and real-world benchmarks demonstrates its superiority over current state-of-the-art approaches.
Exploring CLIP for Assessing the Look and Feel of Images
Jul 25, 2022
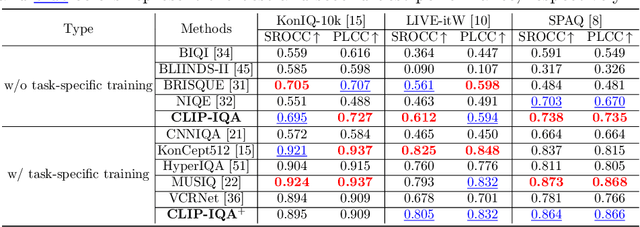
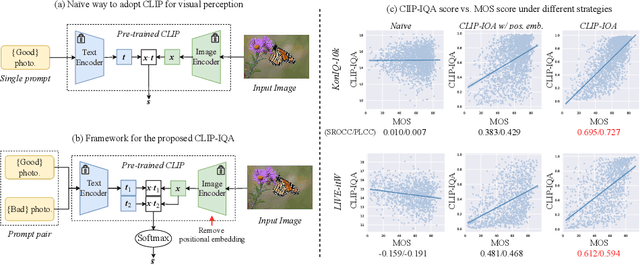
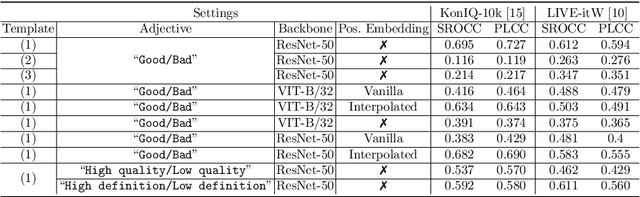
Measuring the perception of visual content is a long-standing problem in computer vision. Many mathematical models have been developed to evaluate the look or quality of an image. Despite the effectiveness of such tools in quantifying degradations such as noise and blurriness levels, such quantification is loosely coupled with human language. When it comes to more abstract perception about the feel of visual content, existing methods can only rely on supervised models that are explicitly trained with labeled data collected via laborious user study. In this paper, we go beyond the conventional paradigms by exploring the rich visual language prior encapsulated in Contrastive Language-Image Pre-training (CLIP) models for assessing both the quality perception (look) and abstract perception (feel) of images in a zero-shot manner. In particular, we discuss effective prompt designs and show an effective prompt pairing strategy to harness the prior. We also provide extensive experiments on controlled datasets and Image Quality Assessment (IQA) benchmarks. Our results show that CLIP captures meaningful priors that generalize well to different perceptual assessments. Code will be avaliable at https://github.com/IceClear/CLIP-IQA.
SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos
Dec 27, 2021

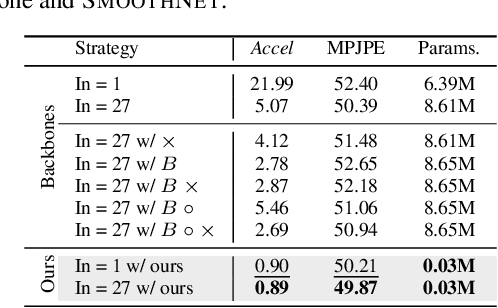
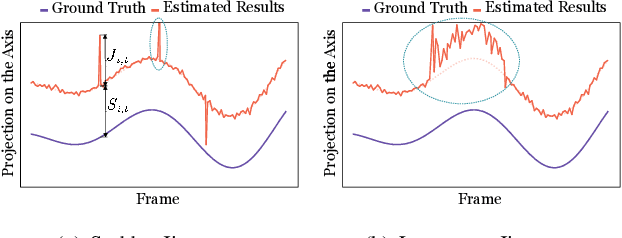
When analyzing human motion videos, the output jitters from existing pose estimators are highly-unbalanced. Most frames only suffer from slight jitters, while significant jitters occur in those frames with occlusion or poor image quality. Such complex poses often persist in videos, leading to consecutive frames with poor estimation results and large jitters. Existing pose smoothing solutions based on temporal convolutional networks, recurrent neural networks, or low-pass filters cannot deal with such a long-term jitter problem without considering the significant and persistent errors within the jittering video segment. Motivated by the above observation, we propose a novel plug-and-play refinement network, namely SMOOTHNET, which can be attached to any existing pose estimators to improve its temporal smoothness and enhance its per-frame precision simultaneously. Especially, SMOOTHNET is a simple yet effective data-driven fully-connected network with large receptive fields, effectively mitigating the impact of long-term jitters with unreliable estimation results. We conduct extensive experiments on twelve backbone networks with seven datasets across 2D and 3D pose estimation, body recovery, and downstream tasks. Our results demonstrate that the proposed SMOOTHNET consistently outperforms existing solutions, especially on those clips with high errors and long-term jitters.