 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoliGS: Holistic Gaussian Splatting for Embodied View Synthesis
Jun 24, 2025We propose HoliGS, a novel deformable Gaussian splatting framework that addresses embodied view synthesis from long monocular RGB videos. Unlike prior 4D Gaussian splatting and dynamic NeRF pipelines, which struggle with training overhead in minute-long captures, our method leverages invertible Gaussian Splatting deformation networks to reconstruct large-scale, dynamic environments accurately. Specifically, we decompose each scene into a static background plus time-varying objects, each represented by learned Gaussian primitives undergoing global rigid transformations, skeleton-driven articulation, and subtle non-rigid deformations via an invertible neural flow. This hierarchical warping strategy enables robust free-viewpoint novel-view rendering from various embodied camera trajectories by attaching Gaussians to a complete canonical foreground shape (\eg, egocentric or third-person follow), which may involve substantial viewpoint changes and interactions between multiple actors. Our experiments demonstrate that \ourmethod~ achieves superior reconstruction quality on challenging datasets while significantly reducing both training and rendering time compared to state-of-the-art monocular deformable NeRFs. These results highlight a practical and scalable solution for EVS in real-world scenarios. The source code will be released.
Consistent Subject Generation via Contrastive Instantiated Concepts
Mar 31, 2025While text-to-image generative models can synthesize diverse and faithful contents, subject variation across multiple creations limits the application in long content generation. Existing approaches require time-consuming tuning, references for all subjects, or access to other creations. We introduce Contrastive Concept Instantiation (CoCoIns) to effectively synthesize consistent subjects across multiple independent creations. The framework consists of a generative model and a mapping network, which transforms input latent codes into pseudo-words associated with certain instances of concepts. Users can generate consistent subjects with the same latent codes. To construct such associations, we propose a contrastive learning approach that trains the network to differentiate the combination of prompts and latent codes. Extensive evaluations of human faces with a single subject show that CoCoIns performs comparably to existing methods while maintaining higher flexibility. We also demonstrate the potential of extending CoCoIns to multiple subjects and other object categories.
HoliSDiP: Image Super-Resolution via Holistic Semantics and Diffusion Prior
Nov 27, 2024Text-to-image diffusion models have emerged as powerful priors for real-world image super-resolution (Real-ISR). However, existing methods may produce unintended results due to noisy text prompts and their lack of spatial information. In this paper, we present HoliSDiP, a framework that leverages semantic segmentation to provide both precise textual and spatial guidance for diffusion-based Real-ISR. Our method employs semantic labels as concise text prompts while introducing dense semantic guidance through segmentation masks and our proposed Segmentation-CLIP Map. Extensive experiments demonstrate that HoliSDiP achieves significant improvement in image quality across various Real-ISR scenarios through reduced prompt noise and enhanced spatial control.
A Simple Approach to Unifying Diffusion-based Conditional Generation
Oct 15, 2024
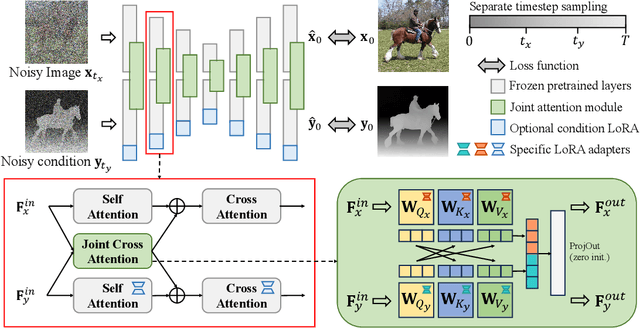
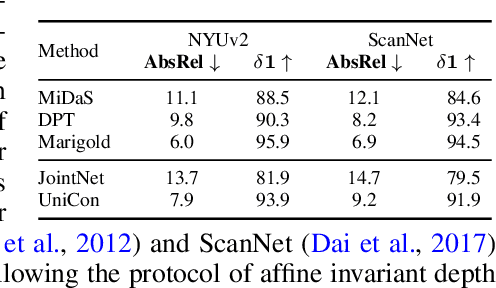

Recent progress in image generation has sparked research into controlling these models through condition signals, with various methods addressing specific challenges in conditional generation. Instead of proposing another specialized technique, we introduce a simple, unified framework to handle diverse conditional generation tasks involving a specific image-condition correlation. By learning a joint distribution over a correlated image pair (e.g. image and depth) with a diffusion model, our approach enables versatile capabilities via different inference-time sampling schemes, including controllable image generation (e.g. depth to image), estimation (e.g. image to depth), signal guidance, joint generation (image & depth), and coarse control. Previous attempts at unification often introduce significant complexity through multi-stage training, architectural modification, or increased parameter counts. In contrast, our simple formulation requires a single, computationally efficient training stage, maintains the standard model input, and adds minimal learned parameters (15% of the base model). Moreover, our model supports additional capabilities like non-spatially aligned and coarse conditioning. Extensive results show that our single model can produce comparable results with specialized methods and better results than prior unified methods. We also demonstrate that multiple models can be effectively combined for multi-signal conditional generation.
KITTEN: A Knowledge-Intensive Evaluation of Image Generation on Visual Entities
Oct 15, 2024



Recent advancements in text-to-image generation have significantly enhanced the quality of synthesized images. Despite this progress, evaluations predominantly focus on aesthetic appeal or alignment with text prompts. Consequently, there is limited understanding of whether these models can accurately represent a wide variety of realistic visual entities - a task requiring real-world knowledge. To address this gap, we propose a benchmark focused on evaluating Knowledge-InTensive image generaTion on real-world ENtities (i.e., KITTEN). Using KITTEN, we conduct a systematic study on the fidelity of entities in text-to-image generation models, focusing on their ability to generate a wide range of real-world visual entities, such as landmark buildings, aircraft, plants, and animals. We evaluate the latest text-to-image models and retrieval-augmented customization models using both automatic metrics and carefully-designed human evaluations, with an emphasis on the fidelity of entities in the generated images. Our findings reveal that even the most advanced text-to-image models often fail to generate entities with accurate visual details. Although retrieval-augmented models can enhance the fidelity of entity by incorporating reference images during testing, they often over-rely on these references and struggle to produce novel configurations of the entity as requested in creative text prompts.
Re-boosting Self-Collaboration Parallel Prompt GAN for Unsupervised Image Restoration
Aug 17, 2024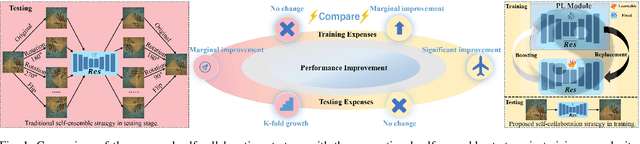
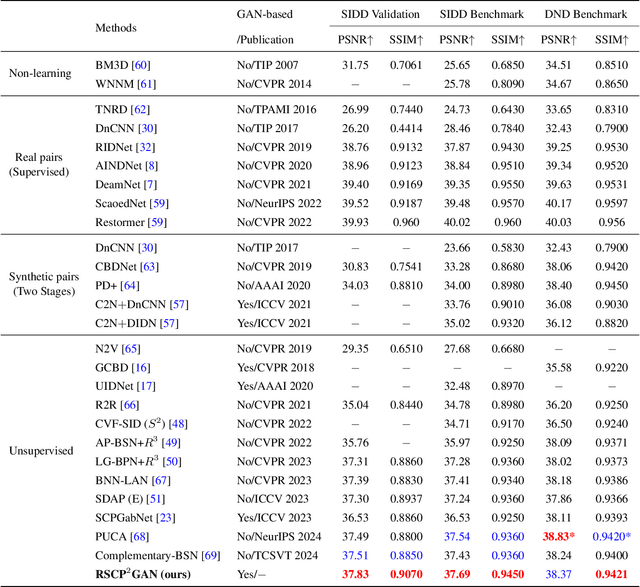
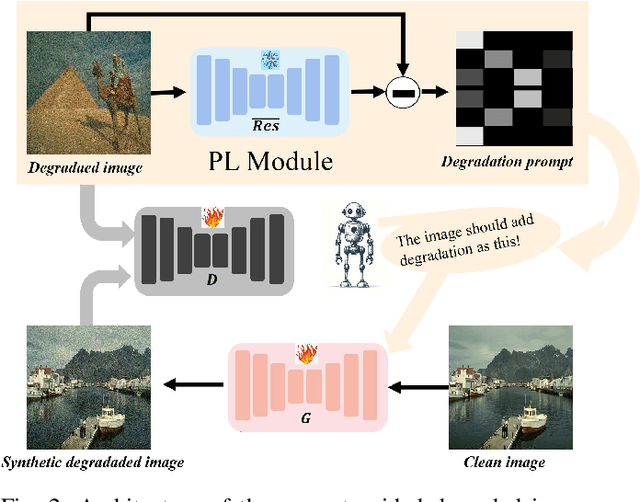
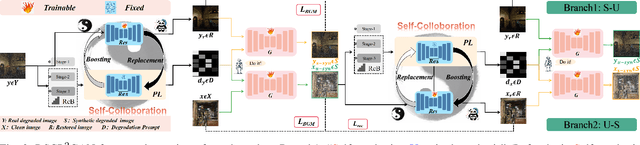
Unsupervised restoration approaches based on generative adversarial networks (GANs) offer a promising solution without requiring paired datasets. Yet, these GAN-based approaches struggle to surpass the performance of conventional unsupervised GAN-based frameworks without significantly modifying model structures or increasing the computational complexity. To address these issues, we propose a self-collaboration (SC) strategy for existing restoration models. This strategy utilizes information from the previous stage as feedback to guide subsequent stages, achieving significant performance improvement without increasing the framework's inference complexity. The SC strategy comprises a prompt learning (PL) module and a restorer ($Res$). It iteratively replaces the previous less powerful fixed restorer $\overline{Res}$ in the PL module with a more powerful $Res$. The enhanced PL module generates better pseudo-degraded/clean image pairs, leading to a more powerful $Res$ for the next iteration. Our SC can significantly improve the $Res$'s performance by over 1.5 dB without adding extra parameters or computational complexity during inference. Meanwhile, existing self-ensemble (SE) and our SC strategies enhance the performance of pre-trained restorers from different perspectives. As SE increases computational complexity during inference, we propose a re-boosting module to the SC (Reb-SC) to improve the SC strategy further by incorporating SE into SC without increasing inference time. This approach further enhances the restorer's performance by approximately 0.3 dB. Extensive experimental results on restoration tasks demonstrate that the proposed model performs favorably against existing state-of-the-art unsupervised restoration methods. Source code and trained models are publicly available at: \url{https://github.com/linxin0/RSCP2GAN}.
Improving Subject-Driven Image Synthesis with Subject-Agnostic Guidance
May 02, 2024



In subject-driven text-to-image synthesis, the synthesis process tends to be heavily influenced by the reference images provided by users, often overlooking crucial attributes detailed in the text prompt. In this work, we propose Subject-Agnostic Guidance (SAG), a simple yet effective solution to remedy the problem. We show that through constructing a subject-agnostic condition and applying our proposed dual classifier-free guidance, one could obtain outputs consistent with both the given subject and input text prompts. We validate the efficacy of our approach through both optimization-based and encoder-based methods. Additionally, we demonstrate its applicability in second-order customization methods, where an encoder-based model is fine-tuned with DreamBooth. Our approach is conceptually simple and requires only minimal code modifications, but leads to substantial quality improvements, as evidenced by our evaluations and user studies.
AdaIR: Exploiting Underlying Similarities of Image Restoration Tasks with Adapters
Apr 17, 2024Existing image restoration approaches typically employ extensive networks specifically trained for designated degradations. Despite being effective, such methods inevitably entail considerable storage costs and computational overheads due to the reliance on task-specific networks. In this work, we go beyond this well-established framework and exploit the inherent commonalities among image restoration tasks. The primary objective is to identify components that are shareable across restoration tasks and augment the shared components with modules specifically trained for individual tasks. Towards this goal, we propose AdaIR, a novel framework that enables low storage cost and efficient training without sacrificing performance. Specifically, a generic restoration network is first constructed through self-supervised pre-training using synthetic degradations. Subsequent to the pre-training phase, adapters are trained to adapt the pre-trained network to specific degradations. AdaIR requires solely the training of lightweight, task-specific modules, ensuring a more efficient storage and training regimen. We have conducted extensive experiments to validate the effectiveness of AdaIR and analyze the influence of the pre-training strategy on discovering shareable components. Extensive experimental results show that AdaIR achieves outstanding results on multi-task restoration while utilizing significantly fewer parameters (1.9 MB) and less training time (7 hours) for each restoration task. The source codes and trained models will be released.
Instruct-Imagen: Image Generation with Multi-modal Instruction
Jan 03, 2024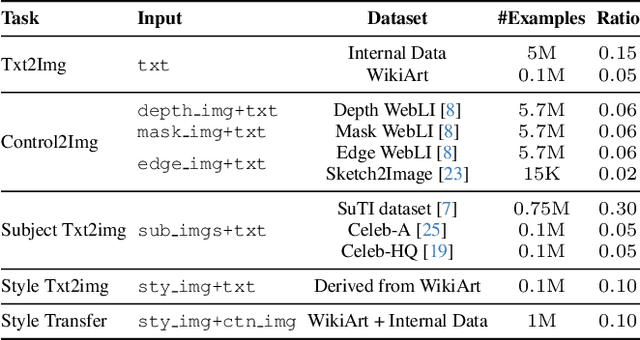

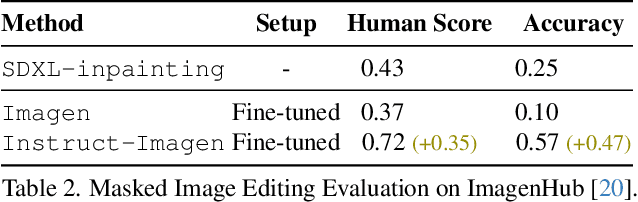
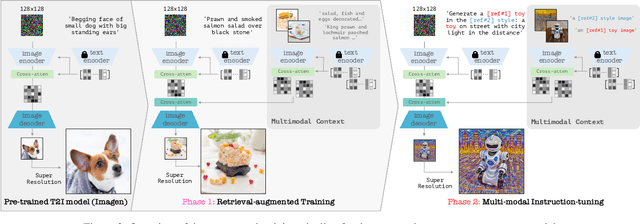
This paper presents instruct-imagen, a model that tackles heterogeneous image generation tasks and generalizes across unseen tasks. We introduce *multi-modal instruction* for image generation, a task representation articulating a range of generation intents with precision. It uses natural language to amalgamate disparate modalities (e.g., text, edge, style, subject, etc.), such that abundant generation intents can be standardized in a uniform format. We then build instruct-imagen by fine-tuning a pre-trained text-to-image diffusion model with a two-stage framework. First, we adapt the model using the retrieval-augmented training, to enhance model's capabilities to ground its generation on external multimodal context. Subsequently, we fine-tune the adapted model on diverse image generation tasks that requires vision-language understanding (e.g., subject-driven generation, etc.), each paired with a multi-modal instruction encapsulating the task's essence. Human evaluation on various image generation datasets reveals that instruct-imagen matches or surpasses prior task-specific models in-domain and demonstrates promising generalization to unseen and more complex tasks.
Multi-task Image Restoration Guided By Robust DINO Features
Dec 05, 2023Multi-task image restoration has gained significant interest due to its inherent versatility and efficiency compared to its single-task counterpart. Despite its potential, performance degradation is observed with an increase in the number of tasks, primarily attributed to the distinct nature of each restoration task. Addressing this challenge, we introduce \mbox{\textbf{DINO-IR}}, a novel multi-task image restoration approach leveraging robust features extracted from DINOv2. Our empirical analysis shows that while shallow features of DINOv2 capture rich low-level image characteristics, the deep features ensure a robust semantic representation insensitive to degradations while preserving high-frequency contour details. Building on these features, we devise specialized components, including multi-layer semantic fusion module, DINO-Restore adaption and fusion module, and DINO perception contrastive loss, to integrate DINOv2 features into the restoration paradigm. Equipped with the aforementioned components, our DINO-IR performs favorably against existing multi-task image restoration approaches in various tasks by a large margin, indicating the superiority and necessity of reinforcing the robust features for multi-task image restoration.