 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
The FACTS Grounding Leaderboard: Benchmarking LLMs' Ability to Ground Responses to Long-Form Input
Jan 06, 2025



We introduce FACTS Grounding, an online leaderboard and associated benchmark that evaluates language models' ability to generate text that is factually accurate with respect to given context in the user prompt. In our benchmark, each prompt includes a user request and a full document, with a maximum length of 32k tokens, requiring long-form responses. The long-form responses are required to be fully grounded in the provided context document while fulfilling the user request. Models are evaluated using automated judge models in two phases: (1) responses are disqualified if they do not fulfill the user request; (2) they are judged as accurate if the response is fully grounded in the provided document. The automated judge models were comprehensively evaluated against a held-out test-set to pick the best prompt template, and the final factuality score is an aggregate of multiple judge models to mitigate evaluation bias. The FACTS Grounding leaderboard will be actively maintained over time, and contains both public and private splits to allow for external participation while guarding the integrity of the leaderboard. It can be found at https://www.kaggle.com/facts-leaderboard.
KITTEN: A Knowledge-Intensive Evaluation of Image Generation on Visual Entities
Oct 15, 2024



Recent advancements in text-to-image generation have significantly enhanced the quality of synthesized images. Despite this progress, evaluations predominantly focus on aesthetic appeal or alignment with text prompts. Consequently, there is limited understanding of whether these models can accurately represent a wide variety of realistic visual entities - a task requiring real-world knowledge. To address this gap, we propose a benchmark focused on evaluating Knowledge-InTensive image generaTion on real-world ENtities (i.e., KITTEN). Using KITTEN, we conduct a systematic study on the fidelity of entities in text-to-image generation models, focusing on their ability to generate a wide range of real-world visual entities, such as landmark buildings, aircraft, plants, and animals. We evaluate the latest text-to-image models and retrieval-augmented customization models using both automatic metrics and carefully-designed human evaluations, with an emphasis on the fidelity of entities in the generated images. Our findings reveal that even the most advanced text-to-image models often fail to generate entities with accurate visual details. Although retrieval-augmented models can enhance the fidelity of entity by incorporating reference images during testing, they often over-rely on these references and struggle to produce novel configurations of the entity as requested in creative text prompts.
Investigating Content Planning for Navigating Trade-offs in Knowledge-Grounded Dialogue
Feb 03, 2024

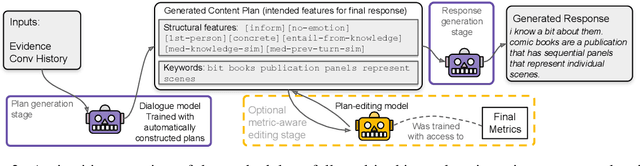

Knowledge-grounded dialogue generation is a challenging task because it requires satisfying two fundamental yet often competing constraints: being responsive in a manner that is specific to what the conversation partner has said while also being attributable to an underlying source document. In this work, we bring this trade-off between these two objectives (specificity and attribution) to light and ask the question: Can explicit content planning before the response generation help the model to address this challenge? To answer this question, we design a framework called PLEDGE, which allows us to experiment with various plan variables explored in prior work, supporting both metric-agnostic and metric-aware approaches. While content planning shows promise, our results on whether it can actually help to navigate this trade-off are mixed -- planning mechanisms that are metric-aware (use automatic metrics during training) are better at automatic evaluations but underperform in human judgment compared to metric-agnostic mechanisms. We discuss how this may be caused by over-fitting to automatic metrics and the need for future work to better calibrate these metrics towards human judgment. We hope the observations from our analysis will inform future work that aims to apply content planning in this context.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Dungeons and Dragons as a Dialog Challenge for Artificial Intelligence
Oct 13, 2022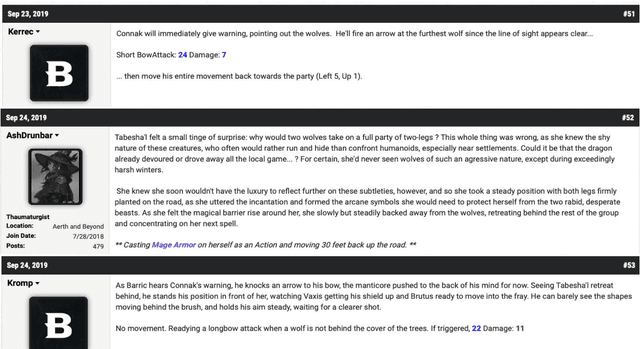


AI researchers have posited Dungeons and Dragons (D&D) as a challenge problem to test systems on various language-related capabilities. In this paper, we frame D&D specifically as a dialogue system challenge, where the tasks are to both generate the next conversational turn in the game and predict the state of the game given the dialogue history. We create a gameplay dataset consisting of nearly 900 games, with a total of 7,000 players, 800,000 dialogue turns, 500,000 dice rolls, and 58 million words. We automatically annotate the data with partial state information about the game play. We train a large language model (LM) to generate the next game turn, conditioning it on different information. The LM can respond as a particular character or as the player who runs the game--i.e., the Dungeon Master (DM). It is trained to produce dialogue that is either in-character (roleplaying in the fictional world) or out-of-character (discussing rules or strategy). We perform a human evaluation to determine what factors make the generated output plausible and interesting. We further perform an automatic evaluation to determine how well the model can predict the game state given the history and examine how well tracking the game state improves its ability to produce plausible conversational output.
Measuring Attribution in Natural Language Generation Models
Dec 23, 2021

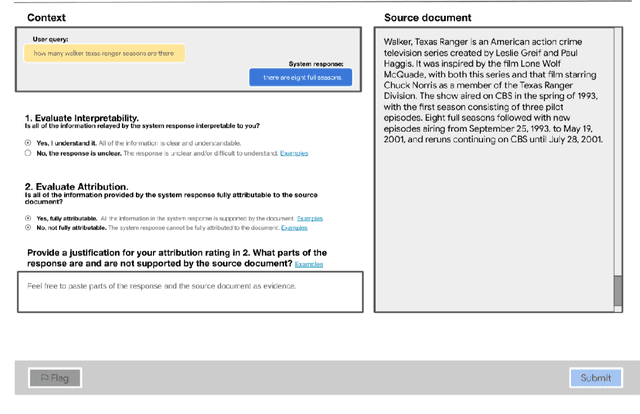
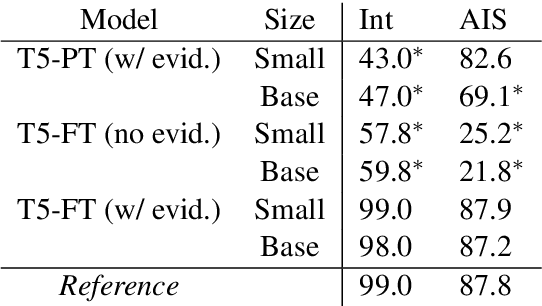
With recent improvements in natural language generation (NLG) models for various applications, it has become imperative to have the means to identify and evaluate whether NLG output is only sharing verifiable information about the external world. In this work, we present a new evaluation framework entitled Attributable to Identified Sources (AIS) for assessing the output of natural language generation models, when such output pertains to the external world. We first define AIS and introduce a two-stage annotation pipeline for allowing annotators to appropriately evaluate model output according to AIS guidelines. We empirically validate this approach on three generation datasets (two in the conversational QA domain and one in summarization) via human evaluation studies that suggest that AIS could serve as a common framework for measuring whether model-generated statements are supported by underlying sources. We release guidelines for the human evaluation studies.
CONQRR: Conversational Query Rewriting for Retrieval with Reinforcement Learning
Dec 16, 2021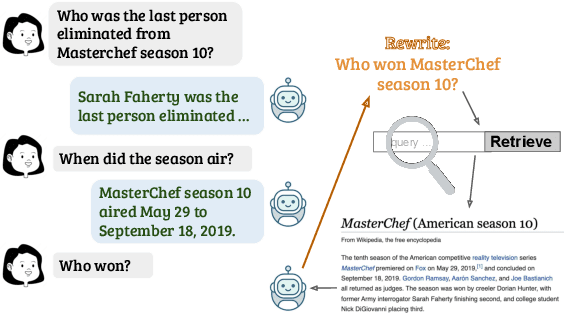
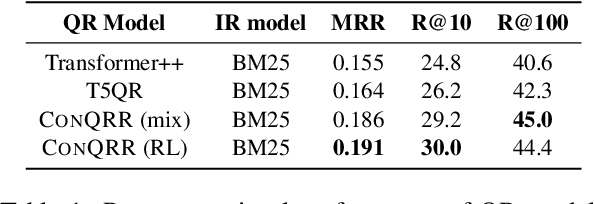
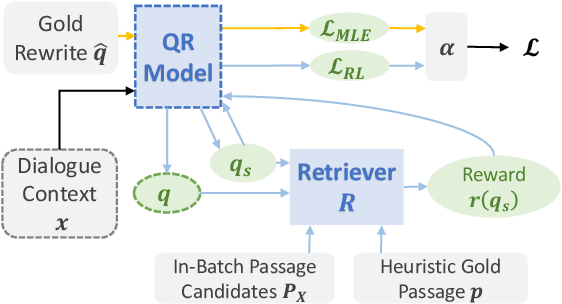
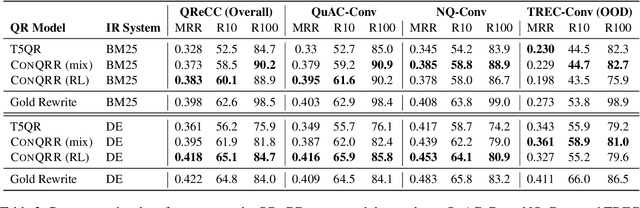
For open-domain conversational question answering (CQA), it is important to retrieve the most relevant passages to answer a question, but this is challenging compared with standard passage retrieval because it requires understanding the full dialogue context rather than a single query. Moreover, it can be expensive to re-train well-established retrievers such as search engines that are originally developed for non-conversational queries. To facilitate their use, we develop a query rewriting model CONQRR that rewrites a conversational question in context into a standalone question. It is trained with a novel reward function to directly optimize towards retrieval and can be adapted to any fixed blackbox retriever using reinforcement learning. We show that CONQRR achieves state-of-the-art results on a recent open-domain CQA dataset, a combination of conversations from three different sources. We also conduct extensive experiments to show the effectiveness of CONQRR for any given fixed retriever.
Increasing Faithfulness in Knowledge-Grounded Dialogue with Controllable Features
Jul 14, 2021
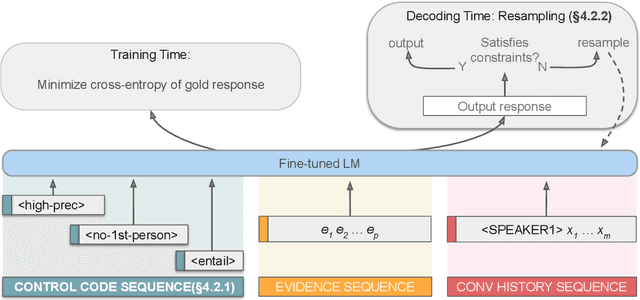
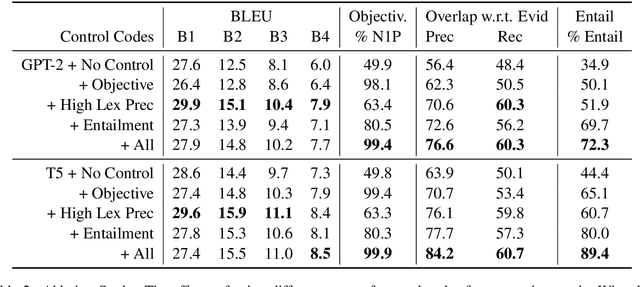
Knowledge-grounded dialogue systems are intended to convey information that is based on evidence provided in a given source text. We discuss the challenges of training a generative neural dialogue model for such systems that is controlled to stay faithful to the evidence. Existing datasets contain a mix of conversational responses that are faithful to selected evidence as well as more subjective or chit-chat style responses. We propose different evaluation measures to disentangle these different styles of responses by quantifying the informativeness and objectivity. At training time, additional inputs based on these evaluation measures are given to the dialogue model. At generation time, these additional inputs act as stylistic controls that encourage the model to generate responses that are faithful to the provided evidence. We also investigate the usage of additional controls at decoding time using resampling techniques. In addition to automatic metrics, we perform a human evaluation study where raters judge the output of these controlled generation models to be generally more objective and faithful to the evidence compared to baseline dialogue systems.
Thieves on Sesame Street! Model Extraction of BERT-based APIs
Oct 27, 2019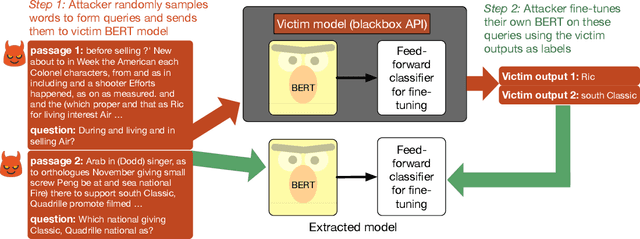

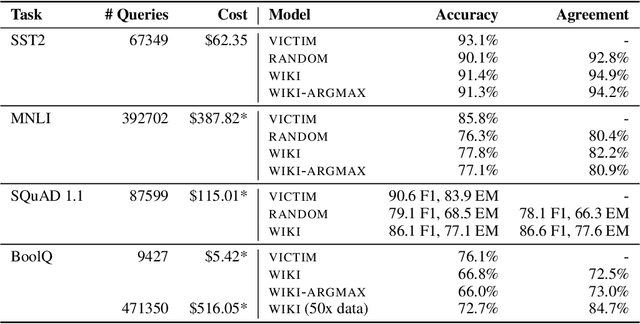
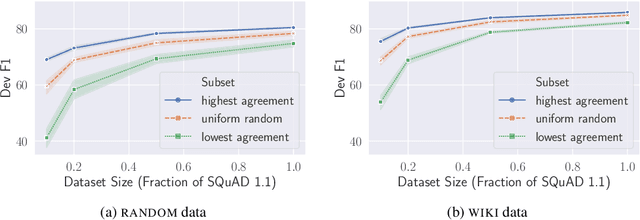
We study the problem of model extraction in natural language processing, in which an adversary with only query access to a victim model attempts to reconstruct a local copy of that model. Assuming that both the adversary and victim model fine-tune a large pretrained language model such as BERT (Devlin et al. 2019), we show that the adversary does not need any real training data to successfully mount the attack. In fact, the attacker need not even use grammatical or semantically meaningful queries: we show that random sequences of words coupled with task-specific heuristics form effective queries for model extraction on a diverse set of NLP tasks including natural language inference and question answering. Our work thus highlights an exploit only made feasible by the shift towards transfer learning methods within the NLP community: for a query budget of a few hundred dollars, an attacker can extract a model that performs only slightly worse than the victim model. Finally, we study two defense strategies against model extraction---membership classification and API watermarking---which while successful against naive adversaries, are ineffective against more sophisticated ones.