 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Entity Linking with Efficient Long Range Sequence Modeling
Oct 12, 2020

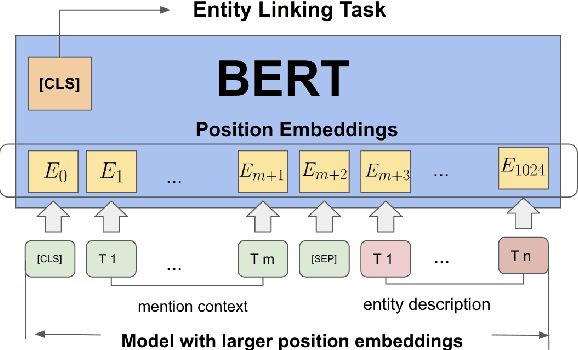
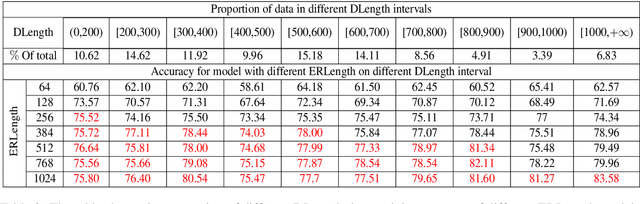
This paper considers the problem of zero-shot entity linking, in which a link in the test time may not present in training. Following the prevailing BERT-based research efforts, we find a simple yet effective way is to expand the long-range sequence modeling. Unlike many previous methods, our method does not require expensive pre-training of BERT with long position embedding. Instead, we propose an efficient position embeddings initialization method called Embedding-repeat, which initializes larger position embeddings based on BERT-Base. On Wikia's zero-shot EL dataset, our method improves the SOTA from 76.06% to 79.08%, and for its long data, the corresponding improvement is from 74.57% to 82.14%. Our experiments suggest the effectiveness of long-range sequence modeling without retraining the BERT model.
Improving Semantic Parsing with Neural Generator-Reranker Architecture
Sep 27, 2019
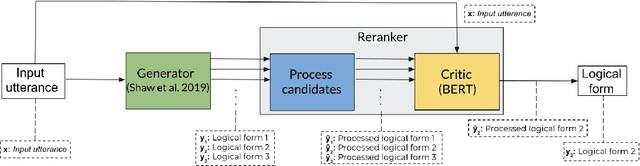


Semantic parsing is the problem of deriving machine interpretable meaning representations from natural language utterances. Neural models with encoder-decoder architectures have recently achieved substantial improvements over traditional methods. Although neural semantic parsers appear to have relatively high recall using large beam sizes, there is room for improvement with respect to one-best precision. In this work, we propose a generator-reranker architecture for semantic parsing. The generator produces a list of potential candidates and the reranker, which consists of a pre-processing step for the candidates followed by a novel critic network, reranks these candidates based on the similarity between each candidate and the input sentence. We show the advantages of this approach along with how it improves the parsing performance through extensive analysis. We experiment our model on three semantic parsing datasets (GEO, ATIS, and OVERNIGHT). The overall architecture achieves the state-of-the-art results in all three datasets.