 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpacking DPO and PPO: Disentangling Best Practices for Learning from Preference Feedback
Jun 13, 2024Learning from preference feedback has emerged as an essential step for improving the generation quality and performance of modern language models (LMs). Despite its widespread use, the way preference-based learning is applied varies wildly, with differing data, learning algorithms, and evaluations used, making disentangling the impact of each aspect difficult. In this work, we identify four core aspects of preference-based learning: preference data, learning algorithm, reward model, and policy training prompts, systematically investigate the impact of these components on downstream model performance, and suggest a recipe for strong learning for preference feedback. Our findings indicate that all aspects are important for performance, with better preference data leading to the largest improvements, followed by the choice of learning algorithm, the use of improved reward models, and finally the use of additional unlabeled prompts for policy training. Notably, PPO outperforms DPO by up to 2.5% in math and 1.2% in general domains. High-quality preference data leads to improvements of up to 8% in instruction following and truthfulness. Despite significant gains of up to 5% in mathematical evaluation when scaling up reward models, we surprisingly observe marginal improvements in other categories. We publicly release the code used for training (https://github.com/hamishivi/EasyLM) and evaluating (https://github.com/allenai/open-instruct) our models, along with the models and datasets themselves (https://huggingface.co/collections/allenai/tulu-v25-suite-66676520fd578080e126f618).
Training Language Models to Generate Text with Citations via Fine-grained Rewards
Feb 06, 2024



While recent Large Language Models (LLMs) have proven useful in answering user queries, they are prone to hallucination, and their responses often lack credibility due to missing references to reliable sources. An intuitive solution to these issues would be to include in-text citations referring to external documents as evidence. While previous works have directly prompted LLMs to generate in-text citations, their performances are far from satisfactory, especially when it comes to smaller LLMs. In this work, we propose an effective training framework using fine-grained rewards to teach LLMs to generate highly supportive and relevant citations, while ensuring the correctness of their responses. We also conduct a systematic analysis of applying these fine-grained rewards to common LLM training strategies, demonstrating its advantage over conventional practices. We conduct extensive experiments on Question Answering (QA) datasets taken from the ALCE benchmark and validate the model's generalizability using EXPERTQA. On LLaMA-2-7B, the incorporation of fine-grained rewards achieves the best performance among the baselines, even surpassing that of GPT-3.5-turbo.
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Oct 17, 2023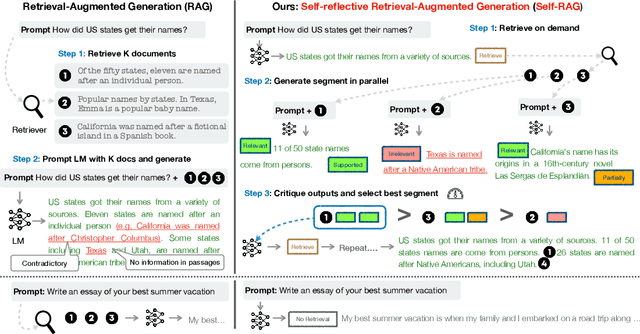

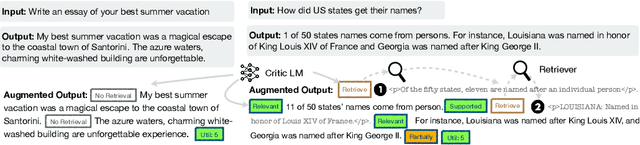
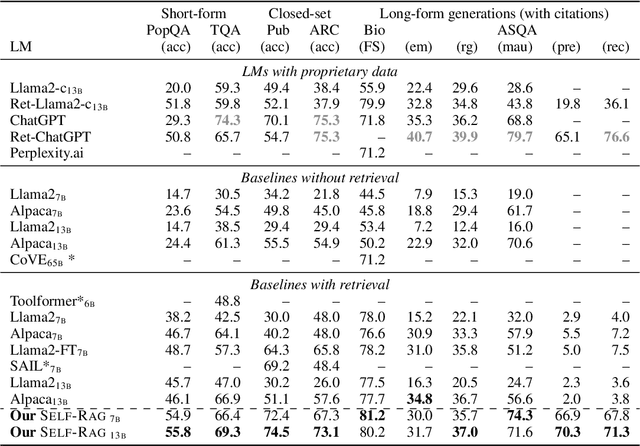
Despite their remarkable capabilities, large language models (LLMs) often produce responses containing factual inaccuracies due to their sole reliance on the parametric knowledge they encapsulate. Retrieval-Augmented Generation (RAG), an ad hoc approach that augments LMs with retrieval of relevant knowledge, decreases such issues. However, indiscriminately retrieving and incorporating a fixed number of retrieved passages, regardless of whether retrieval is necessary, or passages are relevant, diminishes LM versatility or can lead to unhelpful response generation. We introduce a new framework called Self-Reflective Retrieval-Augmented Generation (Self-RAG) that enhances an LM's quality and factuality through retrieval and self-reflection. Our framework trains a single arbitrary LM that adaptively retrieves passages on-demand, and generates and reflects on retrieved passages and its own generations using special tokens, called reflection tokens. Generating reflection tokens makes the LM controllable during the inference phase, enabling it to tailor its behavior to diverse task requirements. Experiments show that Self-RAG (7B and 13B parameters) significantly outperforms state-of-the-art LLMs and retrieval-augmented models on a diverse set of tasks. Specifically, Self-RAG outperforms ChatGPT and retrieval-augmented Llama2-chat on Open-domain QA, reasoning and fact verification tasks, and it shows significant gains in improving factuality and citation accuracy for long-form generations relative to these models.
DIALGEN: Collaborative Human-LM Generated Dialogues for Improved Understanding of Human-Human Conversations
Jul 13, 2023



Applications that could benefit from automatic understanding of human-human conversations often come with challenges associated with private information in real-world data such as call center or clinical conversations. Working with protected data also increases costs of annotation, which limits technology development. To address these challenges, we propose DIALGEN, a human-in-the-loop semi-automated dialogue generation framework. DIALGEN uses a language model (ChatGPT) that can follow schema and style specifications to produce fluent conversational text, generating a complex conversation through iteratively generating subdialogues and using human feedback to correct inconsistencies or redirect the flow. In experiments on structured summarization of agent-client information gathering calls, framed as dialogue state tracking, we show that DIALGEN data enables significant improvement in model performance.
Fine-Grained Human Feedback Gives Better Rewards for Language Model Training
Jun 02, 2023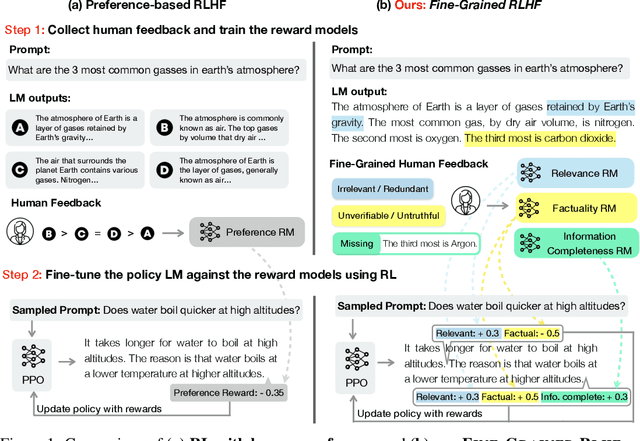
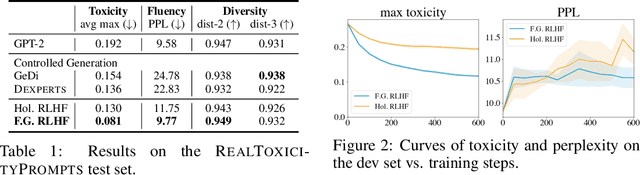

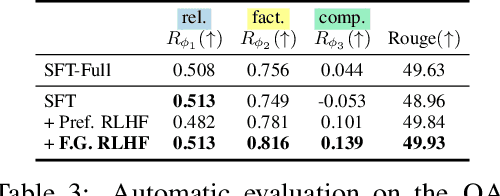
Language models (LMs) often exhibit undesirable text generation behaviors, including generating false, toxic, or irrelevant outputs. Reinforcement learning from human feedback (RLHF) - where human preference judgments on LM outputs are transformed into a learning signal - has recently shown promise in addressing these issues. However, such holistic feedback conveys limited information on long text outputs; it does not indicate which aspects of the outputs influenced user preference; e.g., which parts contain what type(s) of errors. In this paper, we use fine-grained human feedback (e.g., which sentence is false, which sub-sentence is irrelevant) as an explicit training signal. We introduce Fine-Grained RLHF, a framework that enables training and learning from reward functions that are fine-grained in two respects: (1) density, providing a reward after every segment (e.g., a sentence) is generated; and (2) incorporating multiple reward models associated with different feedback types (e.g., factual incorrectness, irrelevance, and information incompleteness). We conduct experiments on detoxification and long-form question answering to illustrate how learning with such reward functions leads to improved performance, supported by both automatic and human evaluation. Additionally, we show that LM behaviors can be customized using different combinations of fine-grained reward models. We release all data, collected human feedback, and codes at https://FineGrainedRLHF.github.io.
INSCIT: Information-Seeking Conversations with Mixed-Initiative Interactions
Jul 02, 2022

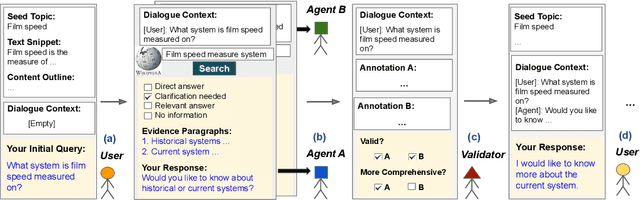
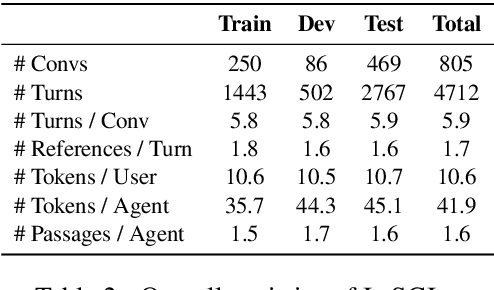
In an information-seeking conversation, a user converses with an agent to ask a series of questions that can often be under- or over-specified. An ideal agent would first identify that they were in such a situation by searching through their underlying knowledge source and then appropriately interacting with a user to resolve it. However, most existing studies either fail to or artificially incorporate such agent-side initiatives. In this work, we present INSCIT (pronounced Insight), a dataset for information-seeking conversations with mixed-initiative interactions. It contains a total of 4.7K user-agent turns from 805 human-human conversations where the agent searches over Wikipedia and either asks for clarification or provides relevant information to address user queries. We define two subtasks, namely evidence passage identification and response generation, as well as a new human evaluation protocol to assess the model performance. We report results of two strong baselines based on state-of-the-art models of conversational knowledge identification and open-domain question answering. Both models significantly underperform humans and fail to generate coherent and informative responses, suggesting ample room for improvement in future studies.
CONQRR: Conversational Query Rewriting for Retrieval with Reinforcement Learning
Dec 16, 2021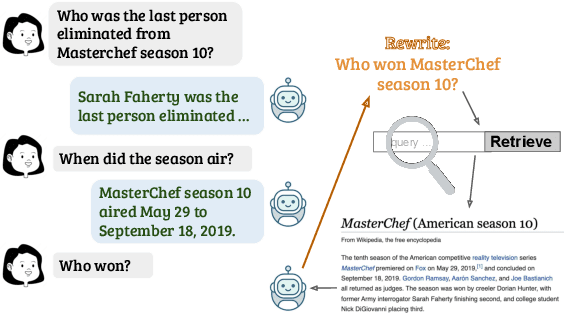
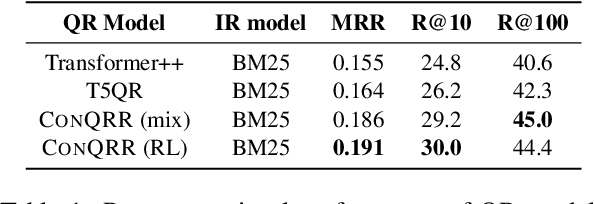
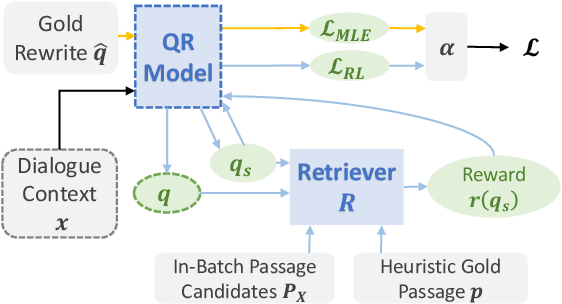
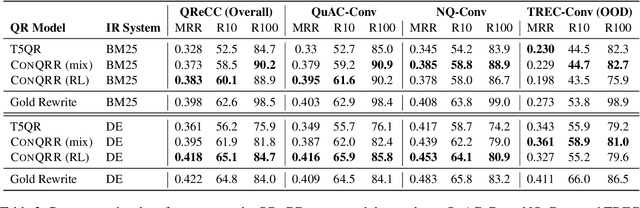
For open-domain conversational question answering (CQA), it is important to retrieve the most relevant passages to answer a question, but this is challenging compared with standard passage retrieval because it requires understanding the full dialogue context rather than a single query. Moreover, it can be expensive to re-train well-established retrievers such as search engines that are originally developed for non-conversational queries. To facilitate their use, we develop a query rewriting model CONQRR that rewrites a conversational question in context into a standalone question. It is trained with a novel reward function to directly optimize towards retrieval and can be adapted to any fixed blackbox retriever using reinforcement learning. We show that CONQRR achieves state-of-the-art results on a recent open-domain CQA dataset, a combination of conversations from three different sources. We also conduct extensive experiments to show the effectiveness of CONQRR for any given fixed retriever.
DIALKI: Knowledge Identification in Conversational Systems through Dialogue-Document Contextualization
Sep 10, 2021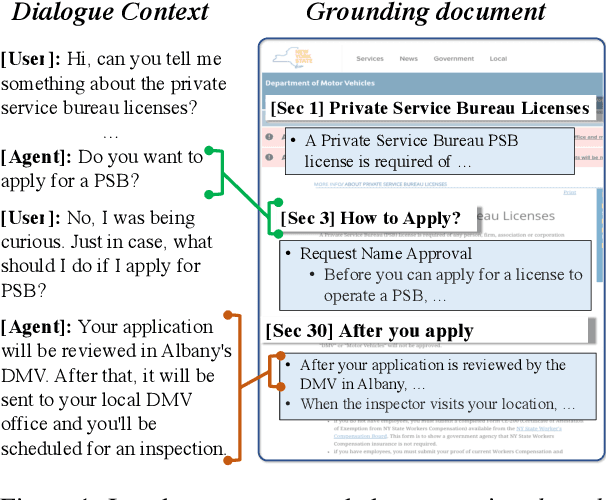

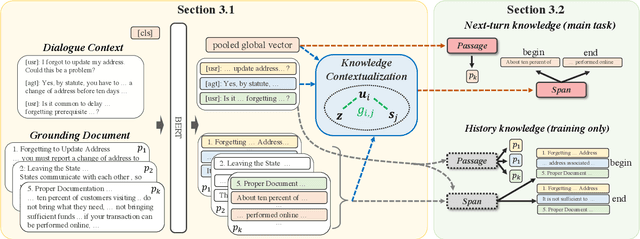
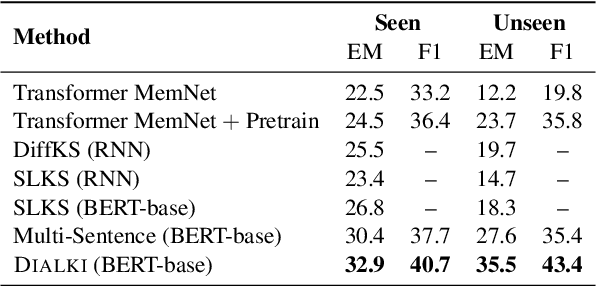
Identifying relevant knowledge to be used in conversational systems that are grounded in long documents is critical to effective response generation. We introduce a knowledge identification model that leverages the document structure to provide dialogue-contextualized passage encodings and better locate knowledge relevant to the conversation. An auxiliary loss captures the history of dialogue-document connections. We demonstrate the effectiveness of our model on two document-grounded conversational datasets and provide analyses showing generalization to unseen documents and long dialogue contexts.
Automatic Document Sketching: Generating Drafts from Analogous Texts
Jun 14, 2021
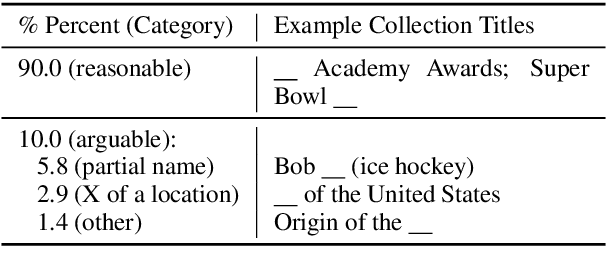
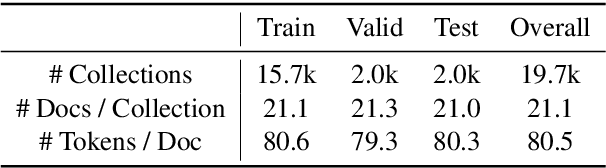
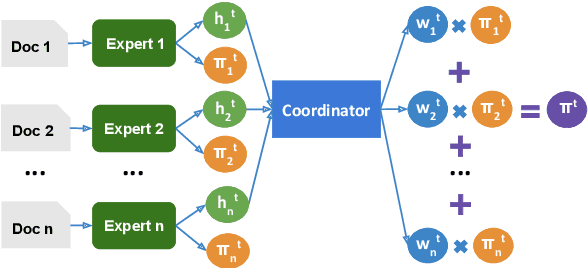
The advent of large pre-trained language models has made it possible to make high-quality predictions on how to add or change a sentence in a document. However, the high branching factor inherent to text generation impedes the ability of even the strongest language models to offer useful editing suggestions at a more global or document level. We introduce a new task, document sketching, which involves generating entire draft documents for the writer to review and revise. These drafts are built from sets of documents that overlap in form - sharing large segments of potentially reusable text - while diverging in content. To support this task, we introduce a Wikipedia-based dataset of analogous documents and investigate the application of weakly supervised methods, including use of a transformer-based mixture of experts, together with reinforcement learning. We report experiments using automated and human evaluation methods and discuss relative merits of these models.
Extracting Summary Knowledge Graphs from Long Documents
Sep 19, 2020



Knowledge graphs capture entities and relations from long documents and can facilitate reasoning in many downstream applications. Extracting compact knowledge graphs containing only salient entities and relations is important but challenging for understanding and summarizing long documents. We introduce a new text-to-graph task of predicting summarized knowledge graphs from long documents. We develop a dataset of 200k document/graph pairs using automatic and human annotations. We also develop strong baselines for this task based on graph learning and text summarization, and provide quantitative and qualitative studies of their effect.