 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter LLM Reasoning via Dual-Play
Nov 19, 2025Large Language Models (LLMs) have achieved remarkable progress through Reinforcement Learning with Verifiable Rewards (RLVR), yet still rely heavily on external supervision (e.g., curated labels). Adversarial learning, particularly through self-play, offers a promising alternative that enables models to iteratively learn from themselves - thus reducing reliance on external supervision. Dual-play extends adversarial learning by assigning specialized roles to two models and training them against each other, fostering sustained competition and mutual evolution. Despite its promise, adapting dual-play training to LLMs remains limited, largely due to their susceptibility to reward hacking and training instability. In this paper, we introduce PasoDoble, a novel LLM dual-play framework. PasoDoble adversarially trains two models initialized from the same base model: a Proposer, which generates challenging questions with ground-truth answers, and a Solver, which attempts to solve them. We enrich the Proposer with knowledge from a pre-training dataset to ensure the questions' quality and diversity. To avoid reward hacking, the Proposer is rewarded for producing only valid questions that push the Solver's limit, while the Solver is rewarded for solving them correctly, and both are updated jointly. To further enhance training stability, we introduce an optional offline paradigm that decouples Proposer and Solver updates, alternately updating each for several steps while holding the other fixed. Notably, PasoDoble operates without supervision during training. Experimental results show that PasoDoble can improve the reasoning performance of LLMs. Our project page is available at https://hcy123902.github.io/PasoDoble.
DCRM: A Heuristic to Measure Response Pair Quality in Preference Optimization
Jun 17, 2025



Recent research has attempted to associate preference optimization (PO) performance with the underlying preference datasets. In this work, our observation is that the differences between the preferred response $y^+$ and dispreferred response $y^-$ influence what LLMs can learn, which may not match the desirable differences to learn. Therefore, we use distance and reward margin to quantify these differences, and combine them to get Distance Calibrated Reward Margin (DCRM), a metric that measures the quality of a response pair for PO. Intuitively, DCRM encourages minimal noisy differences and maximal desired differences. With this, we study 3 types of commonly used preference datasets, classified along two axes: the source of the responses and the preference labeling function. We establish a general correlation between higher DCRM of the training set and better learning outcome. Inspired by this, we propose a best-of-$N^2$ pairing method that selects response pairs with the highest DCRM. Empirically, in various settings, our method produces training datasets that can further improve models' performance on AlpacaEval, MT-Bench, and Arena-Hard over the existing training sets.
HAPO: Training Language Models to Reason Concisely via History-Aware Policy Optimization
May 16, 2025



While scaling the length of responses at test-time has been shown to markedly improve the reasoning abilities and performance of large language models (LLMs), it often results in verbose outputs and increases inference cost. Prior approaches for efficient test-time scaling, typically using universal budget constraints or query-level length optimization, do not leverage historical information from previous encounters with the same problem during training. We hypothesize that this limits their ability to progressively make solutions more concise over time. To address this, we present History-Aware Policy Optimization (HAPO), which keeps track of a history state (e.g., the minimum length over previously generated correct responses) for each problem. HAPO employs a novel length reward function based on this history state to incentivize the discovery of correct solutions that are more concise than those previously found. Crucially, this reward structure avoids overly penalizing shorter incorrect responses with the goal of facilitating exploration towards more efficient solutions. By combining this length reward with a correctness reward, HAPO jointly optimizes for correctness and efficiency. We use HAPO to train DeepSeek-R1-Distill-Qwen-1.5B, DeepScaleR-1.5B-Preview, and Qwen-2.5-1.5B-Instruct, and evaluate HAPO on several math benchmarks that span various difficulty levels. Experiment results demonstrate that HAPO effectively induces LLMs' concise reasoning abilities, producing length reductions of 33-59% with accuracy drops of only 2-5%.
LLaVA-SLT: Visual Language Tuning for Sign Language Translation
Dec 21, 2024



In the realm of Sign Language Translation (SLT), reliance on costly gloss-annotated datasets has posed a significant barrier. Recent advancements in gloss-free SLT methods have shown promise, yet they often largely lag behind gloss-based approaches in terms of translation accuracy. To narrow this performance gap, we introduce LLaVA-SLT, a pioneering Large Multimodal Model (LMM) framework designed to leverage the power of Large Language Models (LLMs) through effectively learned visual language embeddings. Our model is trained through a trilogy. First, we propose linguistic continued pretraining. We scale up the LLM and adapt it to the sign language domain using an extensive corpus dataset, effectively enhancing its textual linguistic knowledge about sign language. Then, we adopt visual contrastive pretraining to align the visual encoder with a large-scale pretrained text encoder. We propose hierarchical visual encoder that learns a robust word-level intermediate representation that is compatible with LLM token embeddings. Finally, we propose visual language tuning. We freeze pretrained models and employ a lightweight trainable MLP connector. It efficiently maps the pretrained visual language embeddings into the LLM token embedding space, enabling downstream SLT task. Our comprehensive experiments demonstrate that LLaVA-SLT outperforms the state-of-the-art methods. By using extra annotation-free data, it even closes to the gloss-based accuracy.
SCOPE: Sign Language Contextual Processing with Embedding from LLMs
Sep 02, 2024
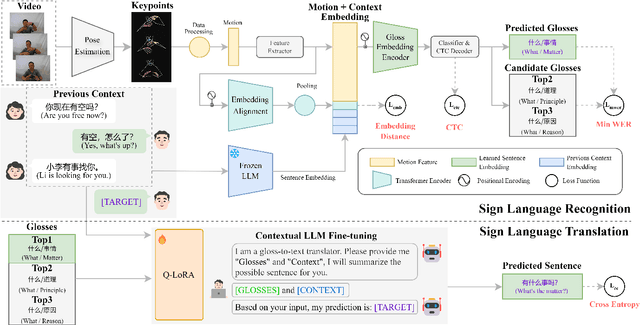


Sign languages, used by around 70 million Deaf individuals globally, are visual languages that convey visual and contextual information. Current methods in vision-based sign language recognition (SLR) and translation (SLT) struggle with dialogue scenes due to limited dataset diversity and the neglect of contextually relevant information. To address these challenges, we introduce SCOPE (Sign language Contextual Processing with Embedding from LLMs), a novel context-aware vision-based SLR and SLT framework. For SLR, we utilize dialogue contexts through a multi-modal encoder to enhance gloss-level recognition. For subsequent SLT, we further fine-tune a Large Language Model (LLM) by incorporating prior conversational context. We also contribute a new sign language dataset that contains 72 hours of Chinese sign language videos in contextual dialogues across various scenarios. Experimental results demonstrate that our SCOPE framework achieves state-of-the-art performance on multiple datasets, including Phoenix-2014T, CSL-Daily, and our SCOPE dataset. Moreover, surveys conducted with participants from the Deaf community further validate the robustness and effectiveness of our approach in real-world applications. Both our dataset and code will be open-sourced to facilitate further research.
Multi-party Response Generation with Relation Disentanglement
Mar 23, 2024



Existing neural response generation models have achieved impressive improvements for two-party conversations, which assume that utterances are sequentially organized. However, many real-world dialogues involve multiple interlocutors and the structure of conversational context is much more complex, e.g. utterances from different interlocutors can occur "in parallel". Facing this challenge, there are works trying to model the relations among utterances or interlocutors to facilitate response generation with clearer context. Nonetheless, these methods rely heavily on such relations and all assume that these are given beforehand, which is impractical and hinders the generality of such methods. In this work, we propose to automatically infer the relations via relational thinking on subtle clues inside the conversation context without any human label, and leverage these relations to guide the neural response generation. Specifically, we first apply a deep graph random process to fully consider all possible relations among utterances in the conversational context. Then the inferred relation graphs are integrated with a variational auto-encoder framework to train a GAN for structure-aware response generation. Experimental results on the Ubuntu Internet Relay Chat (IRC) channel benchmark and the most recent Movie Dialogues show that our method outperforms various baseline models for multi-party response generation.
KnowPhish: Large Language Models Meet Multimodal Knowledge Graphs for Enhancing Reference-Based Phishing Detection
Mar 04, 2024



Phishing attacks have inflicted substantial losses on individuals and businesses alike, necessitating the development of robust and efficient automated phishing detection approaches. Reference-based phishing detectors (RBPDs), which compare the logos on a target webpage to a known set of logos, have emerged as the state-of-the-art approach. However, a major limitation of existing RBPDs is that they rely on a manually constructed brand knowledge base, making it infeasible to scale to a large number of brands, which results in false negative errors due to the insufficient brand coverage of the knowledge base. To address this issue, we propose an automated knowledge collection pipeline, using which we collect and release a large-scale multimodal brand knowledge base, KnowPhish, containing 20k brands with rich information about each brand. KnowPhish can be used to boost the performance of existing RBPDs in a plug-and-play manner. A second limitation of existing RBPDs is that they solely rely on the image modality, ignoring useful textual information present in the webpage HTML. To utilize this textual information, we propose a Large Language Model (LLM)-based approach to extract brand information of webpages from text. Our resulting multimodal phishing detection approach, KnowPhish Detector (KPD), can detect phishing webpages with or without logos. We evaluate KnowPhish and KPD on a manually validated dataset, and on a field study under Singapore's local context, showing substantial improvements in effectiveness and efficiency compared to state-of-the-art baselines.
Training Language Models to Generate Text with Citations via Fine-grained Rewards
Feb 06, 2024



While recent Large Language Models (LLMs) have proven useful in answering user queries, they are prone to hallucination, and their responses often lack credibility due to missing references to reliable sources. An intuitive solution to these issues would be to include in-text citations referring to external documents as evidence. While previous works have directly prompted LLMs to generate in-text citations, their performances are far from satisfactory, especially when it comes to smaller LLMs. In this work, we propose an effective training framework using fine-grained rewards to teach LLMs to generate highly supportive and relevant citations, while ensuring the correctness of their responses. We also conduct a systematic analysis of applying these fine-grained rewards to common LLM training strategies, demonstrating its advantage over conventional practices. We conduct extensive experiments on Question Answering (QA) datasets taken from the ALCE benchmark and validate the model's generalizability using EXPERTQA. On LLaMA-2-7B, the incorporation of fine-grained rewards achieves the best performance among the baselines, even surpassing that of GPT-3.5-turbo.
Inherent limitations of LLMs regarding spatial information
Dec 05, 2023



Despite the significant advancements in natural language processing capabilities demonstrated by large language models such as ChatGPT, their proficiency in comprehending and processing spatial information, especially within the domains of 2D and 3D route planning, remains notably underdeveloped. This paper investigates the inherent limitations of ChatGPT and similar models in spatial reasoning and navigation-related tasks, an area critical for applications ranging from autonomous vehicle guidance to assistive technologies for the visually impaired. In this paper, we introduce a novel evaluation framework complemented by a baseline dataset, meticulously crafted for this study. This dataset is structured around three key tasks: plotting spatial points, planning routes in two-dimensional (2D) spaces, and devising pathways in three-dimensional (3D) environments. We specifically developed this dataset to assess the spatial reasoning abilities of ChatGPT. Our evaluation reveals key insights into the model's capabilities and limitations in spatial understanding.
Conversation Disentanglement with Bi-Level Contrastive Learning
Oct 27, 2022



Conversation disentanglement aims to group utterances into detached sessions, which is a fundamental task in processing multi-party conversations. Existing methods have two main drawbacks. First, they overemphasize pairwise utterance relations but pay inadequate attention to the utterance-to-context relation modeling. Second, huge amount of human annotated data is required for training, which is expensive to obtain in practice. To address these issues, we propose a general disentangle model based on bi-level contrastive learning. It brings closer utterances in the same session while encourages each utterance to be near its clustered session prototypes in the representation space. Unlike existing approaches, our disentangle model works in both supervised setting with labeled data and unsupervised setting when no such data is available. The proposed method achieves new state-of-the-art performance on both settings across several public datasets.