 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Design of Compositional Machines
Oct 16, 2025The design of complex machines stands as both a marker of human intelligence and a foundation of engineering practice. Given recent advances in large language models (LLMs), we ask whether they, too, can learn to create. We approach this question through the lens of compositional machine design: a task in which machines are assembled from standardized components to meet functional demands like locomotion or manipulation in a simulated physical environment. To support this investigation, we introduce BesiegeField, a testbed built on the machine-building game Besiege, which enables part-based construction, physical simulation and reward-driven evaluation. Using BesiegeField, we benchmark state-of-the-art LLMs with agentic workflows and identify key capabilities required for success, including spatial reasoning, strategic assembly, and instruction-following. As current open-source models fall short, we explore reinforcement learning (RL) as a path to improvement: we curate a cold-start dataset, conduct RL finetuning experiments, and highlight open challenges at the intersection of language, machine design, and physical reasoning.
SCOPE: Sign Language Contextual Processing with Embedding from LLMs
Sep 02, 2024
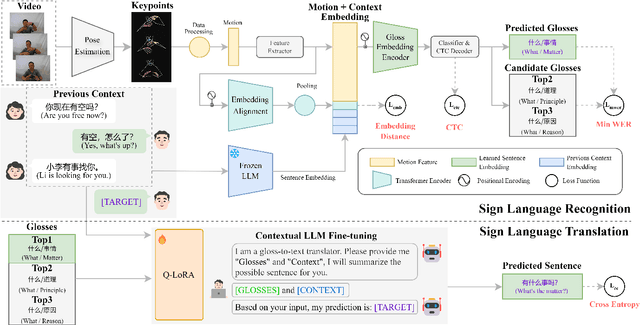


Sign languages, used by around 70 million Deaf individuals globally, are visual languages that convey visual and contextual information. Current methods in vision-based sign language recognition (SLR) and translation (SLT) struggle with dialogue scenes due to limited dataset diversity and the neglect of contextually relevant information. To address these challenges, we introduce SCOPE (Sign language Contextual Processing with Embedding from LLMs), a novel context-aware vision-based SLR and SLT framework. For SLR, we utilize dialogue contexts through a multi-modal encoder to enhance gloss-level recognition. For subsequent SLT, we further fine-tune a Large Language Model (LLM) by incorporating prior conversational context. We also contribute a new sign language dataset that contains 72 hours of Chinese sign language videos in contextual dialogues across various scenarios. Experimental results demonstrate that our SCOPE framework achieves state-of-the-art performance on multiple datasets, including Phoenix-2014T, CSL-Daily, and our SCOPE dataset. Moreover, surveys conducted with participants from the Deaf community further validate the robustness and effectiveness of our approach in real-world applications. Both our dataset and code will be open-sourced to facilitate further research.
BOTH2Hands: Inferring 3D Hands from Both Text Prompts and Body Dynamics
Dec 20, 2023
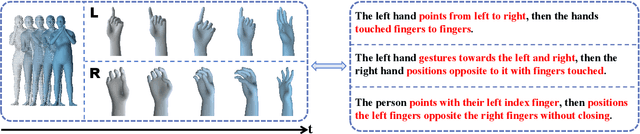
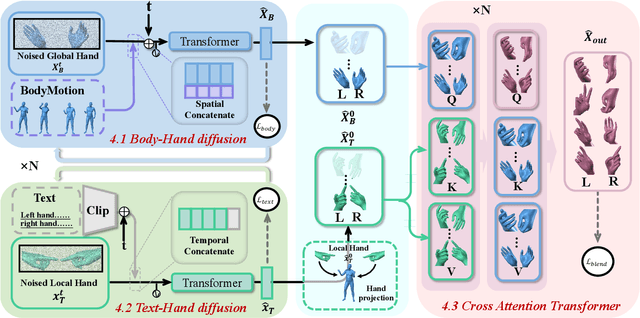

The recently emerging text-to-motion advances have spired numerous attempts for convenient and interactive human motion generation. Yet, existing methods are largely limited to generating body motions only without considering the rich two-hand motions, let alone handling various conditions like body dynamics or texts. To break the data bottleneck, we propose BOTH57M, a novel multi-modal dataset for two-hand motion generation. Our dataset includes accurate motion tracking for the human body and hands and provides pair-wised finger-level hand annotations and body descriptions. We further provide a strong baseline method, BOTH2Hands, for the novel task: generating vivid two-hand motions from both implicit body dynamics and explicit text prompts. We first warm up two parallel body-to-hand and text-to-hand diffusion models and then utilize the cross-attention transformer for motion blending. Extensive experiments and cross-validations demonstrate the effectiveness of our approach and dataset for generating convincing two-hand motions from the hybrid body-and-textual conditions. Our dataset and code will be disseminated to the community for future research.
Detecting Spoilers in Movie Reviews with External Movie Knowledge and User Networks
Apr 22, 2023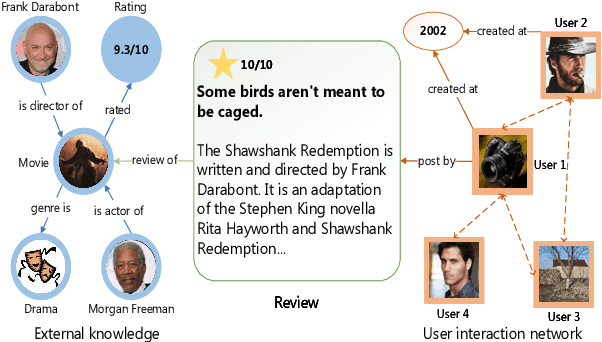
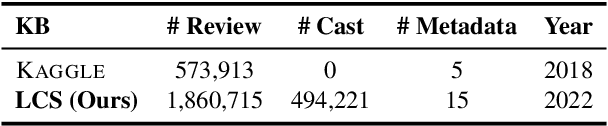

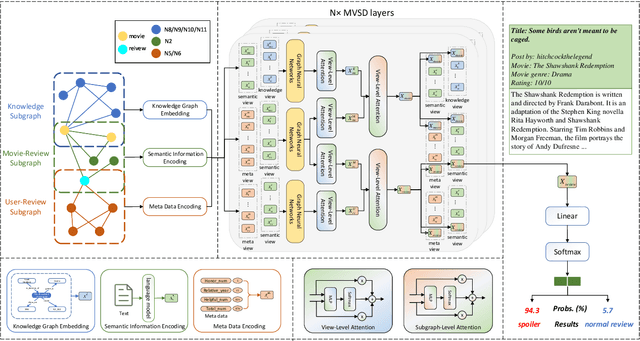
Online movie review platforms are providing crowdsourced feedback for the film industry and the general public, while spoiler reviews greatly compromise user experience. Although preliminary research efforts were made to automatically identify spoilers, they merely focus on the review content itself, while robust spoiler detection requires putting the review into the context of facts and knowledge regarding movies, user behavior on film review platforms, and more. In light of these challenges, we first curate a large-scale network-based spoiler detection dataset LCS and a comprehensive and up-to-date movie knowledge base UKM. We then propose MVSD, a novel Multi-View Spoiler Detection framework that takes into account the external knowledge about movies and user activities on movie review platforms. Specifically, MVSD constructs three interconnecting heterogeneous information networks to model diverse data sources and their multi-view attributes, while we design and employ a novel heterogeneous graph neural network architecture for spoiler detection as node-level classification. Extensive experiments demonstrate that MVSD advances the state-of-the-art on two spoiler detection datasets, while the introduction of external knowledge and user interactions help ground robust spoiler detection. Our data and code are available at https://github.com/Arthur-Heng/Spoiler-Detection
InterGen: Diffusion-based Multi-human Motion Generation under Complex Interactions
Apr 12, 2023We have recently seen tremendous progress in diffusion advances for generating realistic human motions. Yet, they largely disregard the rich multi-human interactions. In this paper, we present InterGen, an effective diffusion-based approach that incorporates human-to-human interactions into the motion diffusion process, which enables layman users to customize high-quality two-person interaction motions, with only text guidance. We first contribute a multimodal dataset, named InterHuman. It consists of about 107M frames for diverse two-person interactions, with accurate skeletal motions and 16,756 natural language descriptions. For the algorithm side, we carefully tailor the motion diffusion model to our two-person interaction setting. To handle the symmetry of human identities during interactions, we propose two cooperative transformer-based denoisers that explicitly share weights, with a mutual attention mechanism to further connect the two denoising processes. Then, we propose a novel representation for motion input in our interaction diffusion model, which explicitly formulates the global relations between the two performers in the world frame. We further introduce two novel regularization terms to encode spatial relations, equipped with a corresponding damping scheme during the training of our interaction diffusion model. Extensive experiments validate the effectiveness and generalizability of InterGen. Notably, it can generate more diverse and compelling two-person motions than previous methods and enables various downstream applications for human interactions.
KALM: Knowledge-Aware Integration of Local, Document, and Global Contexts for Long Document Understanding
Oct 08, 2022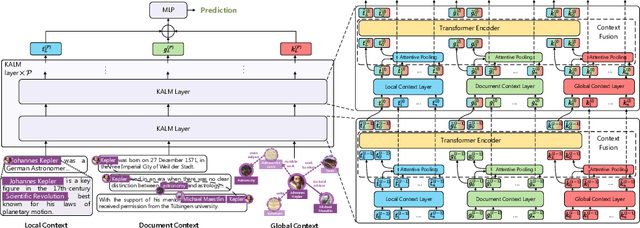
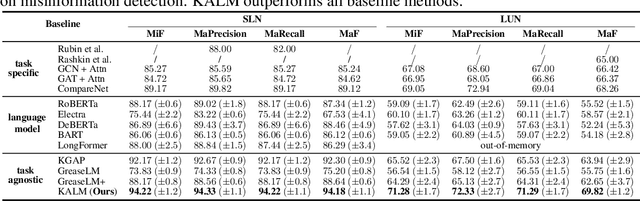
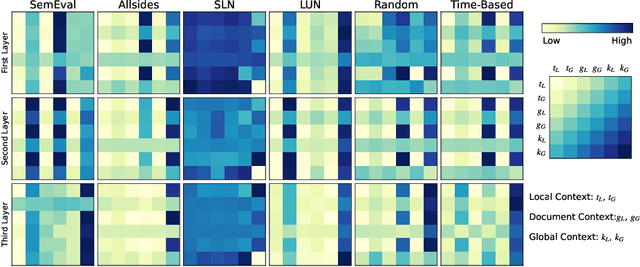
With the advent of pre-trained language models (LMs), increasing research efforts have been focusing on infusing commonsense and domain-specific knowledge to prepare LMs for downstream tasks. These works attempt to leverage knowledge graphs, the de facto standard of symbolic knowledge representation, along with pre-trained LMs. While existing approaches leverage external knowledge, it remains an open question how to jointly incorporate knowledge graphs representing varying contexts, from local (e.g., sentence), to document-level, to global knowledge, to enable knowledge-rich and interpretable exchange across these contexts. Such rich contextualization can be especially beneficial for long document understanding tasks since standard pre-trained LMs are typically bounded by the input sequence length. In light of these challenges, we propose KALM, a Knowledge-Aware Language Model that jointly leverages knowledge in local, document-level, and global contexts for long document understanding. KALM first encodes long documents and knowledge graphs into the three knowledge-aware context representations. It then processes each context with context-specific layers, followed by a context fusion layer that facilitates interpretable knowledge exchange to derive an overarching document representation. Extensive experiments demonstrate that KALM achieves state-of-the-art performance on three long document understanding tasks across 6 datasets/settings. Further analyses reveal that the three knowledge-aware contexts are complementary and they all contribute to model performance, while the importance and information exchange patterns of different contexts vary with respect to different tasks and datasets.
BIC: Twitter Bot Detection with Text-Graph Interaction and Semantic Consistency
Aug 17, 2022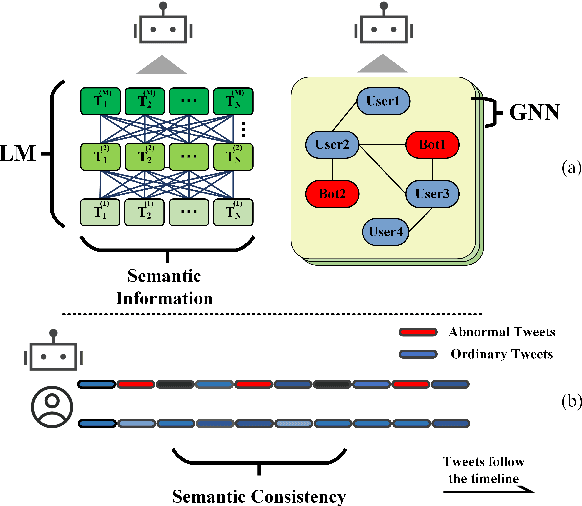
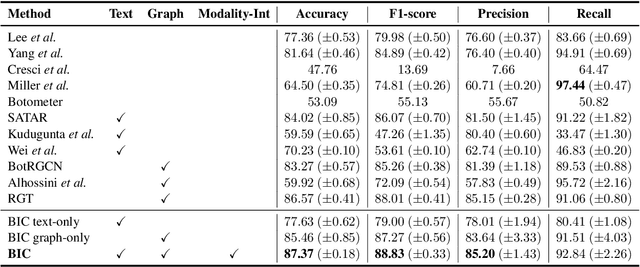
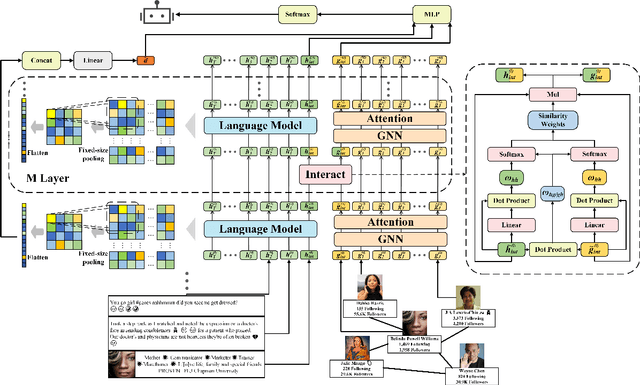
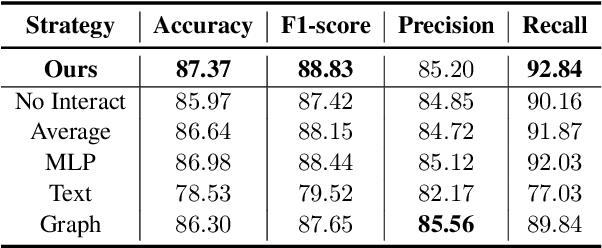
Twitter bot detection is an important and meaningful task. Existing text-based methods can deeply analyze user tweet content, achieving high performance. However, novel Twitter bots evade these detections by stealing genuine users' tweets and diluting malicious content with benign tweets. These novel bots are proposed to be characterized by semantic inconsistency. In addition, methods leveraging Twitter graph structure are recently emerging, showing great competitiveness. However, hardly a method has made text and graph modality deeply fused and interacted to leverage both advantages and learn the relative importance of the two modalities. In this paper, we propose a novel model named BIC that makes the text and graph modalities deeply interactive and detects tweet semantic inconsistency. Specifically, BIC contains a text propagation module, a graph propagation module to conduct bot detection respectively on text and graph structure, and a proven effective text-graph interactive module to make the two interact. Besides, BIC contains a semantic consistency detection module to learn semantic consistency information from tweets. Extensive experiments demonstrate that our framework outperforms competitive baselines on a comprehensive Twitter bot benchmark. We also prove the effectiveness of the proposed interaction and semantic consistency detection.
TwiBot-22: Towards Graph-Based Twitter Bot Detection
Jun 12, 2022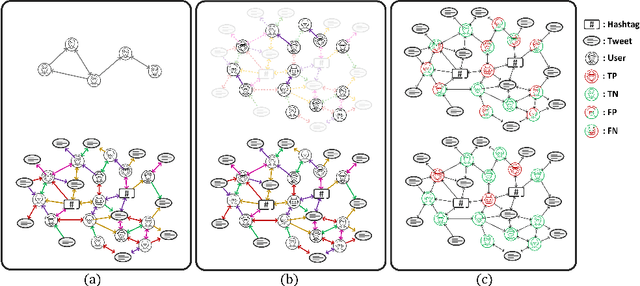
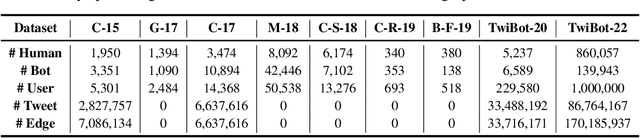
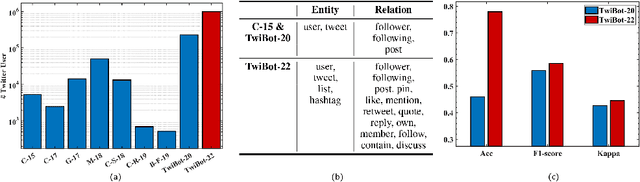
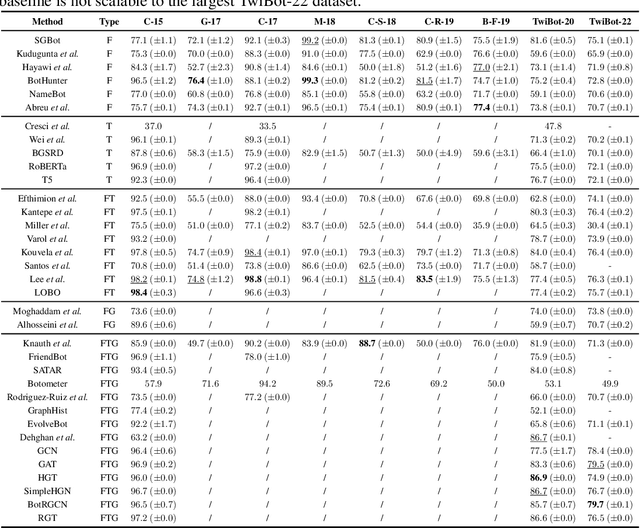
Twitter bot detection has become an increasingly important task to combat misinformation, facilitate social media moderation, and preserve the integrity of the online discourse. State-of-the-art bot detection methods generally leverage the graph structure of the Twitter network, and they exhibit promising performance when confronting novel Twitter bots that traditional methods fail to detect. However, very few of the existing Twitter bot detection datasets are graph-based, and even these few graph-based datasets suffer from limited dataset scale, incomplete graph structure, as well as low annotation quality. In fact, the lack of a large-scale graph-based Twitter bot detection benchmark that addresses these issues has seriously hindered the development and evaluation of novel graph-based bot detection approaches. In this paper, we propose TwiBot-22, a comprehensive graph-based Twitter bot detection benchmark that presents the largest dataset to date, provides diversified entities and relations on the Twitter network, and has considerably better annotation quality than existing datasets. In addition, we re-implement 35 representative Twitter bot detection baselines and evaluate them on 9 datasets, including TwiBot-22, to promote a fair comparison of model performance and a holistic understanding of research progress. To facilitate further research, we consolidate all implemented codes and datasets into the TwiBot-22 evaluation framework, where researchers could consistently evaluate new models and datasets. The TwiBot-22 Twitter bot detection benchmark and evaluation framework are publicly available at https://twibot22.github.io/
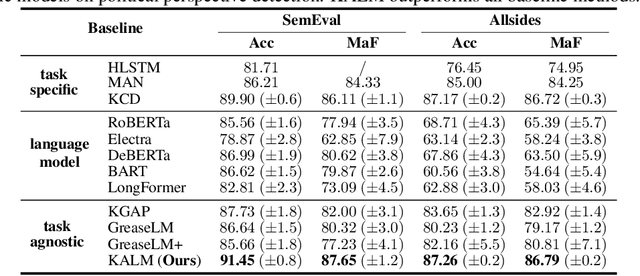
KCD: Knowledge Walks and Textual Cues Enhanced Political Perspective Detection in News Media
Apr 08, 2022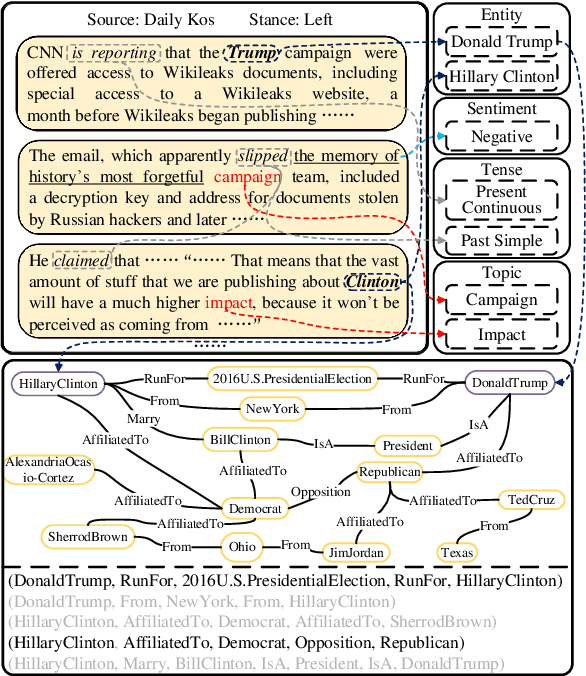
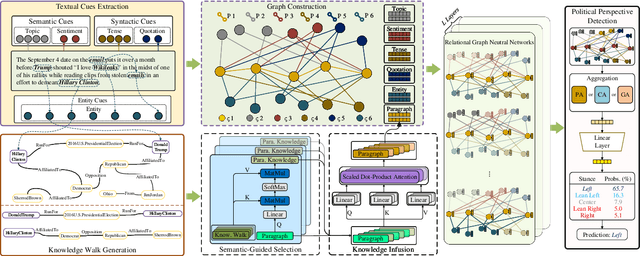
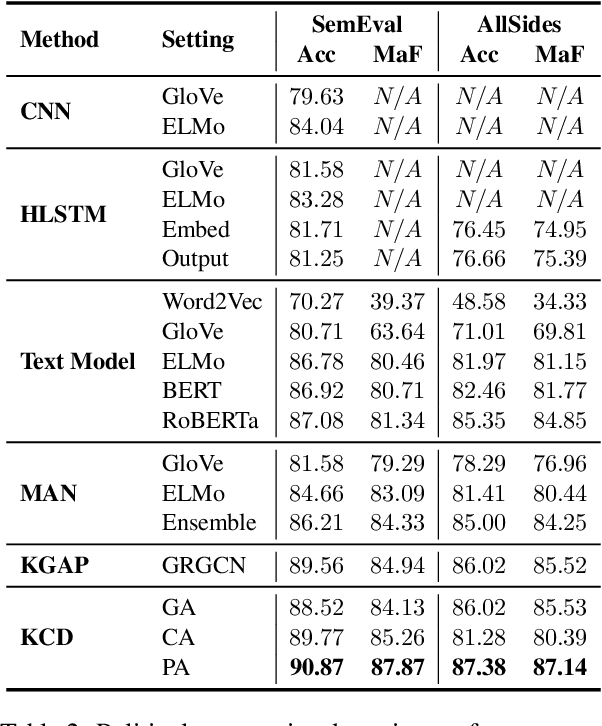
Political perspective detection has become an increasingly important task that can help combat echo chambers and political polarization. Previous approaches generally focus on leveraging textual content to identify stances, while they fail to reason with background knowledge or leverage the rich semantic and syntactic textual labels in news articles. In light of these limitations, we propose KCD, a political perspective detection approach to enable multi-hop knowledge reasoning and incorporate textual cues as paragraph-level labels. Specifically, we firstly generate random walks on external knowledge graphs and infuse them with news text representations. We then construct a heterogeneous information network to jointly model news content as well as semantic, syntactic and entity cues in news articles. Finally, we adopt relational graph neural networks for graph-level representation learning and conduct political perspective detection. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods on two benchmark datasets. We further examine the effect of knowledge walks and textual cues and how they contribute to our approach's data efficiency.