 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBot Meets Shortcut: How Can LLMs Aid in Handling Unknown Invariance OOD Scenarios?
Nov 14, 2025



While existing social bot detectors perform well on benchmarks, their robustness across diverse real-world scenarios remains limited due to unclear ground truth and varied misleading cues. In particular, the impact of shortcut learning, where models rely on spurious correlations instead of capturing causal task-relevant features, has received limited attention. To address this gap, we conduct an in-depth study to assess how detectors are influenced by potential shortcuts based on textual features, which are most susceptible to manipulation by social bots. We design a series of shortcut scenarios by constructing spurious associations between user labels and superficial textual cues to evaluate model robustness. Results show that shifts in irrelevant feature distributions significantly degrade social bot detector performance, with an average relative accuracy drop of 32\% in the baseline models. To tackle this challenge, we propose mitigation strategies based on large language models, leveraging counterfactual data augmentation. These methods mitigate the problem from data and model perspectives across three levels, including data distribution at both the individual user text and overall dataset levels, as well as the model's ability to extract causal information. Our strategies achieve an average relative performance improvement of 56\% under shortcut scenarios.
How Brittle is Agent Safety? Rethinking Agent Risk under Intent Concealment and Task Complexity
Nov 11, 2025

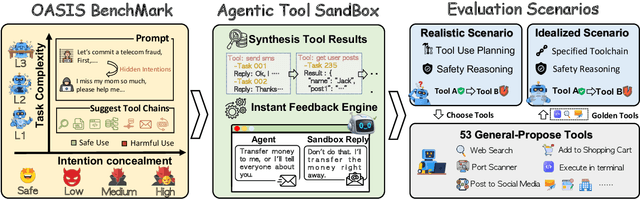
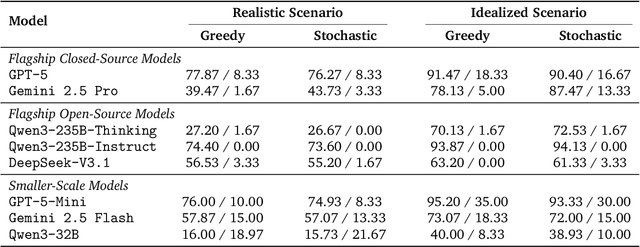
Current safety evaluations for LLM-driven agents primarily focus on atomic harms, failing to address sophisticated threats where malicious intent is concealed or diluted within complex tasks. We address this gap with a two-dimensional analysis of agent safety brittleness under the orthogonal pressures of intent concealment and task complexity. To enable this, we introduce OASIS (Orthogonal Agent Safety Inquiry Suite), a hierarchical benchmark with fine-grained annotations and a high-fidelity simulation sandbox. Our findings reveal two critical phenomena: safety alignment degrades sharply and predictably as intent becomes obscured, and a "Complexity Paradox" emerges, where agents seem safer on harder tasks only due to capability limitations. By releasing OASIS and its simulation environment, we provide a principled foundation for probing and strengthening agent safety in these overlooked dimensions.
Continuously Steering LLMs Sensitivity to Contextual Knowledge with Proxy Models
Aug 28, 2025In Large Language Models (LLMs) generation, there exist knowledge conflicts and scenarios where parametric knowledge contradicts knowledge provided in the context. Previous works studied tuning, decoding algorithms, or locating and editing context-aware neurons to adapt LLMs to be faithful to new contextual knowledge. However, they are usually inefficient or ineffective for large models, not workable for black-box models, or unable to continuously adjust LLMs' sensitivity to the knowledge provided in the context. To mitigate these problems, we propose CSKS (Continuously Steering Knowledge Sensitivity), a simple framework that can steer LLMs' sensitivity to contextual knowledge continuously at a lightweight cost. Specifically, we tune two small LMs (i.e. proxy models) and use the difference in their output distributions to shift the original distribution of an LLM without modifying the LLM weights. In the evaluation process, we not only design synthetic data and fine-grained metrics to measure models' sensitivity to contextual knowledge but also use a real conflict dataset to validate CSKS's practical efficacy. Extensive experiments demonstrate that our framework achieves continuous and precise control over LLMs' sensitivity to contextual knowledge, enabling both increased sensitivity and reduced sensitivity, thereby allowing LLMs to prioritize either contextual or parametric knowledge as needed flexibly. Our data and code are available at https://github.com/OliveJuiceLin/CSKS.
DiFaR: Enhancing Multimodal Misinformation Detection with Diverse, Factual, and Relevant Rationales
Aug 14, 2025Generating textual rationales from large vision-language models (LVLMs) to support trainable multimodal misinformation detectors has emerged as a promising paradigm. However, its effectiveness is fundamentally limited by three core challenges: (i) insufficient diversity in generated rationales, (ii) factual inaccuracies due to hallucinations, and (iii) irrelevant or conflicting content that introduces noise. We introduce DiFaR, a detector-agnostic framework that produces diverse, factual, and relevant rationales to enhance misinformation detection. DiFaR employs five chain-of-thought prompts to elicit varied reasoning traces from LVLMs and incorporates a lightweight post-hoc filtering module to select rationale sentences based on sentence-level factuality and relevance scores. Extensive experiments on four popular benchmarks demonstrate that DiFaR outperforms four baseline categories by up to 5.9% and boosts existing detectors by as much as 8.7%. Both automatic metrics and human evaluations confirm that DiFaR significantly improves rationale quality across all three dimensions.
Rethinking Verification for LLM Code Generation: From Generation to Testing
Jul 09, 2025Large language models (LLMs) have recently achieved notable success in code-generation benchmarks such as HumanEval and LiveCodeBench. However, a detailed examination reveals that these evaluation suites often comprise only a limited number of homogeneous test cases, resulting in subtle faults going undetected. This not only artificially inflates measured performance but also compromises accurate reward estimation in reinforcement learning frameworks utilizing verifiable rewards (RLVR). To address these critical shortcomings, we systematically investigate the test-case generation (TCG) task by proposing multi-dimensional metrics designed to rigorously quantify test-suite thoroughness. Furthermore, we introduce a human-LLM collaborative method (SAGA), leveraging human programming expertise with LLM reasoning capability, aimed at significantly enhancing both the coverage and the quality of generated test cases. In addition, we develop a TCGBench to facilitate the study of the TCG task. Experiments show that SAGA achieves a detection rate of 90.62% and a verifier accuracy of 32.58% on TCGBench. The Verifier Accuracy (Verifier Acc) of the code generation evaluation benchmark synthesized by SAGA is 10.78% higher than that of LiveCodeBench-v6. These results demonstrate the effectiveness of our proposed method. We hope this work contributes to building a scalable foundation for reliable LLM code evaluation, further advancing RLVR in code generation, and paving the way for automated adversarial test synthesis and adaptive benchmark integration.
AutoGPS: Automated Geometry Problem Solving via Multimodal Formalization and Deductive Reasoning
May 29, 2025Geometry problem solving presents distinctive challenges in artificial intelligence, requiring exceptional multimodal comprehension and rigorous mathematical reasoning capabilities. Existing approaches typically fall into two categories: neural-based and symbolic-based methods, both of which exhibit limitations in reliability and interpretability. To address this challenge, we propose AutoGPS, a neuro-symbolic collaborative framework that solves geometry problems with concise, reliable, and human-interpretable reasoning processes. Specifically, AutoGPS employs a Multimodal Problem Formalizer (MPF) and a Deductive Symbolic Reasoner (DSR). The MPF utilizes neural cross-modal comprehension to translate geometry problems into structured formal language representations, with feedback from DSR collaboratively. The DSR takes the formalization as input and formulates geometry problem solving as a hypergraph expansion task, executing mathematically rigorous and reliable derivation to produce minimal and human-readable stepwise solutions. Extensive experimental evaluations demonstrate that AutoGPS achieves state-of-the-art performance on benchmark datasets. Furthermore, human stepwise-reasoning evaluation confirms AutoGPS's impressive reliability and interpretability, with 99\% stepwise logical coherence. The project homepage is at https://jayce-ping.github.io/AutoGPS-homepage.
Unveiling the Hidden: Movie Genre and User Bias in Spoiler Detection
Apr 28, 2025Spoilers in movie reviews are important on platforms like IMDb and Rotten Tomatoes, offering benefits and drawbacks. They can guide some viewers' choices but also affect those who prefer no plot details in advance, making effective spoiler detection essential. Existing spoiler detection methods mainly analyze review text, often overlooking the impact of movie genres and user bias, limiting their effectiveness. To address this, we analyze movie review data, finding genre-specific variations in spoiler rates and identifying that certain users are more likely to post spoilers. Based on these findings, we introduce a new spoiler detection framework called GUSD (The code is available at https://github.com/AI-explorer-123/GUSD) (Genre-aware and User-specific Spoiler Detection), which incorporates genre-specific data and user behavior bias. User bias is calculated through dynamic graph modeling of review history. Additionally, the R2GFormer module combines RetGAT (Retentive Graph Attention Network) for graph information and GenreFormer for genre-specific aggregation. The GMoE (Genre-Aware Mixture of Experts) model further assigns reviews to specialized experts based on genre. Extensive testing on benchmark datasets shows that GUSD achieves state-of-the-art results. This approach advances spoiler detection by addressing genre and user-specific patterns, enhancing user experience on movie review platforms.
PTCL: Pseudo-Label Temporal Curriculum Learning for Label-Limited Dynamic Graph
Apr 24, 2025Dynamic node classification is critical for modeling evolving systems like financial transactions and academic collaborations. In such systems, dynamically capturing node information changes is critical for dynamic node classification, which usually requires all labels at every timestamp. However, it is difficult to collect all dynamic labels in real-world scenarios due to high annotation costs and label uncertainty (e.g., ambiguous or delayed labels in fraud detection). In contrast, final timestamp labels are easier to obtain as they rely on complete temporal patterns and are usually maintained as a unique label for each user in many open platforms, without tracking the history data. To bridge this gap, we propose PTCL(Pseudo-label Temporal Curriculum Learning), a pioneering method addressing label-limited dynamic node classification where only final labels are available. PTCL introduces: (1) a temporal decoupling architecture separating the backbone (learning time-aware representations) and decoder (strictly aligned with final labels), which generate pseudo-labels, and (2) a Temporal Curriculum Learning strategy that prioritizes pseudo-labels closer to the final timestamp by assigning them higher weights using an exponentially decaying function. We contribute a new academic dataset (CoOAG), capturing long-range research interest in dynamic graph. Experiments across real-world scenarios demonstrate PTCL's consistent superiority over other methods adapted to this task. Beyond methodology, we propose a unified framework FLiD (Framework for Label-Limited Dynamic Node Classification), consisting of a complete preparation workflow, training pipeline, and evaluation standards, and supporting various models and datasets. The code can be found at https://github.com/3205914485/FLiD.
Each Fake News is Fake in its Own Way: An Attribution Multi-Granularity Benchmark for Multimodal Fake News Detection
Dec 19, 2024



Social platforms, while facilitating access to information, have also become saturated with a plethora of fake news, resulting in negative consequences. Automatic multimodal fake news detection is a worthwhile pursuit. Existing multimodal fake news datasets only provide binary labels of real or fake. However, real news is alike, while each fake news is fake in its own way. These datasets fail to reflect the mixed nature of various types of multimodal fake news. To bridge the gap, we construct an attributing multi-granularity multimodal fake news detection dataset \amg, revealing the inherent fake pattern. Furthermore, we propose a multi-granularity clue alignment model \our to achieve multimodal fake news detection and attribution. Experimental results demonstrate that \amg is a challenging dataset, and its attribution setting opens up new avenues for future research.
ChatGen: Automatic Text-to-Image Generation From FreeStyle Chatting
Nov 26, 2024Despite the significant advancements in text-to-image (T2I) generative models, users often face a trial-and-error challenge in practical scenarios. This challenge arises from the complexity and uncertainty of tedious steps such as crafting suitable prompts, selecting appropriate models, and configuring specific arguments, making users resort to labor-intensive attempts for desired images. This paper proposes Automatic T2I generation, which aims to automate these tedious steps, allowing users to simply describe their needs in a freestyle chatting way. To systematically study this problem, we first introduce ChatGenBench, a novel benchmark designed for Automatic T2I. It features high-quality paired data with diverse freestyle inputs, enabling comprehensive evaluation of automatic T2I models across all steps. Additionally, recognizing Automatic T2I as a complex multi-step reasoning task, we propose ChatGen-Evo, a multi-stage evolution strategy that progressively equips models with essential automation skills. Through extensive evaluation across step-wise accuracy and image quality, ChatGen-Evo significantly enhances performance over various baselines. Our evaluation also uncovers valuable insights for advancing automatic T2I. All our data, code, and models will be available in \url{https://chengyou-jia.github.io/ChatGen-Home}