 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Unreliable Parametric and Contextual Knowledge: Explicit Knowledge Conflict Resolution for LLM Inference
Jun 18, 2026Large language models (LLMs) have achieved strong performance across a wide range of language-based tasks by leveraging both extensive parametric knowledge and in-context learning ability, enabling them to incorporate external information provided in the input prompt. However, the integration of external knowledge can introduce conflicts, not only between the model's internal parametric knowledge and the external information, but also among multiple pieces of external contexts. Existing approaches typically assume that either the model or the provided context is reliable, overlooking the possibility that both sources may contain errors, and avoid conflicts by privileging one source over the other, rather than actively resolving inconsistencies. To address these limitations, we propose a novel framework MACR for LLM knowledge conflict resolution that moves beyond the conventional binary choice paradigm and incorporates an explicit conflict-resolution mechanism based on a multi-agent reasoning approach. Specifically, we first propose an adaptive knowledge assessment and retrieval approach that employs a modified semantic entropy measure to quantify an LLM's confidence in its answer to a given query. Based on this confidence estimation, MACR either externalizes the model's internal knowledge as textual representations or retrieves relevant external knowledge when internal knowledge is insufficient, generating basic contexts for subsequent reasoning. Then we introduce an inductive multi-agent reasoning framework with three specialized agents that, respectively, induce explicit rules, analyze potential conflicts, and resolve inconsistencies across all available contexts. Empirical results demonstrate that MACR significantly outperforms state-of-the-art baselines across benchmarks, while also providing interpretable resolutions of explicit conflicts.
CCrepairBench: A High-Fidelity Benchmark and Reinforcement Learning Framework for C++ Compilation Repair
Sep 19, 2025



The automated repair of C++ compilation errors presents a significant challenge, the resolution of which is critical for developer productivity. Progress in this domain is constrained by two primary factors: the scarcity of large-scale, high-fidelity datasets and the limitations of conventional supervised methods, which often fail to generate semantically correct patches.This paper addresses these gaps by introducing a comprehensive framework with three core contributions. First, we present CCrepair, a novel, large-scale C++ compilation error dataset constructed through a sophisticated generate-and-verify pipeline. Second, we propose a Reinforcement Learning (RL) paradigm guided by a hybrid reward signal, shifting the focus from mere compilability to the semantic quality of the fix. Finally, we establish the robust, two-stage evaluation system providing this signal, centered on an LLM-as-a-Judge whose reliability has been rigorously validated against the collective judgments of a panel of human experts. This integrated approach aligns the training objective with generating high-quality, non-trivial patches that are both syntactically and semantically correct. The effectiveness of our approach was demonstrated experimentally. Our RL-trained Qwen2.5-1.5B-Instruct model achieved performance comparable to a Qwen2.5-14B-Instruct model, validating the efficiency of our training paradigm. Our work provides the research community with a valuable new dataset and a more effective paradigm for training and evaluating robust compilation repair models, paving the way for more practical and reliable automated programming assistants.
Each Fake News is Fake in its Own Way: An Attribution Multi-Granularity Benchmark for Multimodal Fake News Detection
Dec 19, 2024



Social platforms, while facilitating access to information, have also become saturated with a plethora of fake news, resulting in negative consequences. Automatic multimodal fake news detection is a worthwhile pursuit. Existing multimodal fake news datasets only provide binary labels of real or fake. However, real news is alike, while each fake news is fake in its own way. These datasets fail to reflect the mixed nature of various types of multimodal fake news. To bridge the gap, we construct an attributing multi-granularity multimodal fake news detection dataset \amg, revealing the inherent fake pattern. Furthermore, we propose a multi-granularity clue alignment model \our to achieve multimodal fake news detection and attribution. Experimental results demonstrate that \amg is a challenging dataset, and its attribution setting opens up new avenues for future research.
Multi-modal Entity Alignment in Hyperbolic Space
Jun 07, 2021
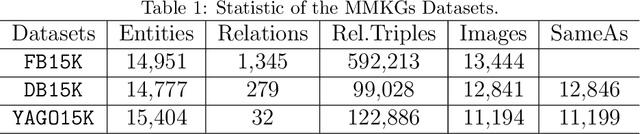

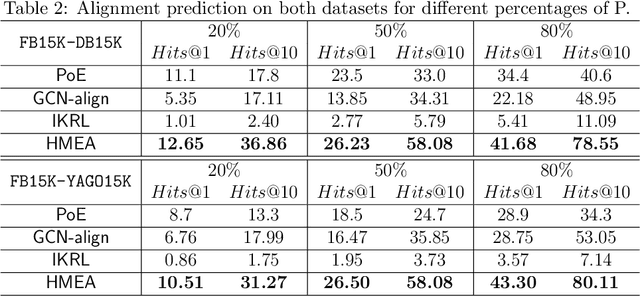
Many AI-related tasks involve the interactions of data in multiple modalities. It has been a new trend to merge multi-modal information into knowledge graph(KG), resulting in multi-modal knowledge graphs (MMKG). However, MMKGs usually suffer from low coverage and incompleteness. To mitigate this problem, a viable approach is to integrate complementary knowledge from other MMKGs. To this end, although existing entity alignment approaches could be adopted, they operate in the Euclidean space, and the resulting Euclidean entity representations can lead to large distortion of KG's hierarchical structure. Besides, the visual information has yet not been well exploited. In response to these issues, in this work, we propose a novel multi-modal entity alignment approach, Hyperbolic multi-modal entity alignment(HMEA), which extends the Euclidean representation to hyperboloid manifold. We first adopt the Hyperbolic Graph Convolutional Networks (HGCNs) to learn structural representations of entities. Regarding the visual information, we generate image embeddings using the densenet model, which are also projected into the hyperbolic space using HGCNs. Finally, we combine the structure and visual representations in the hyperbolic space and use the aggregated embeddings to predict potential alignment results. Extensive experiments and ablation studies demonstrate the effectiveness of our proposed model and its components.
Towards Entity Alignment in the Open World: An Unsupervised Approach
Jan 26, 2021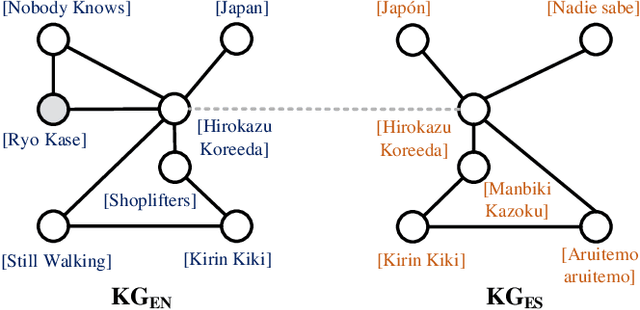
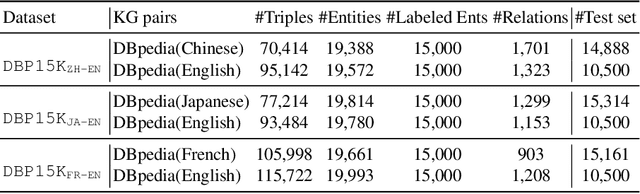
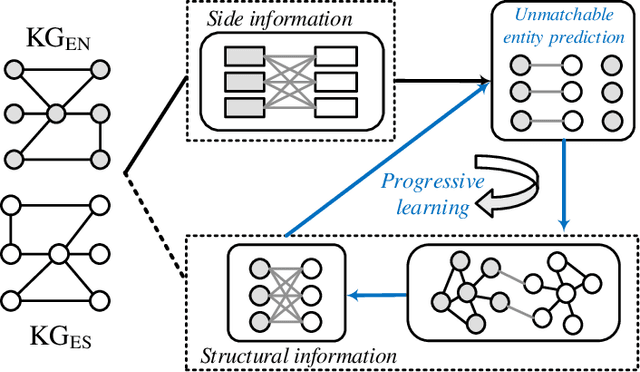
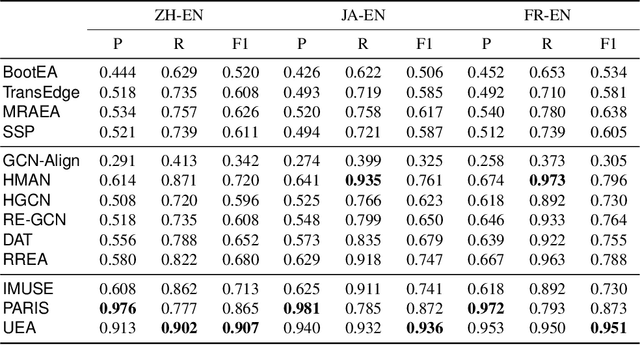
Entity alignment (EA) aims to discover the equivalent entities in different knowledge graphs (KGs). It is a pivotal step for integrating KGs to increase knowledge coverage and quality. Recent years have witnessed a rapid increase of EA frameworks. However, state-of-the-art solutions tend to rely on labeled data for model training. Additionally, they work under the closed-domain setting and cannot deal with entities that are unmatchable. To address these deficiencies, we offer an unsupervised framework that performs entity alignment in the open world. Specifically, we first mine useful features from the side information of KGs. Then, we devise an unmatchable entity prediction module to filter out unmatchable entities and produce preliminary alignment results. These preliminary results are regarded as the pseudo-labeled data and forwarded to the progressive learning framework to generate structural representations, which are integrated with the side information to provide a more comprehensive view for alignment. Finally, the progressive learning framework gradually improves the quality of structural embeddings and enhances the alignment performance by enriching the pseudo-labeled data with alignment results from the previous round. Our solution does not require labeled data and can effectively filter out unmatchable entities. Comprehensive experimental evaluations validate its superiority.
Reinforcement Learning based Collective Entity Alignment with Adaptive Features
Jan 05, 2021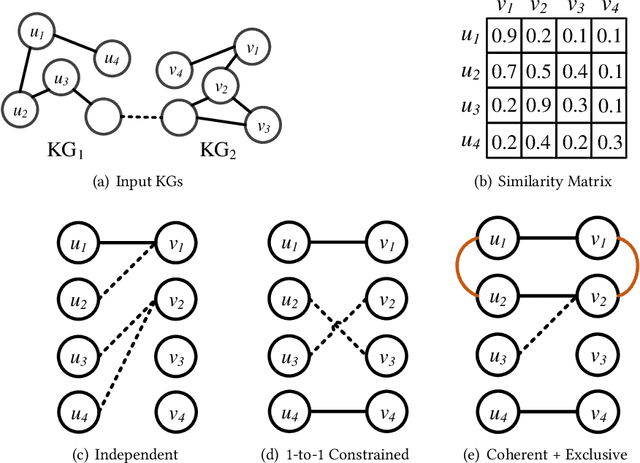
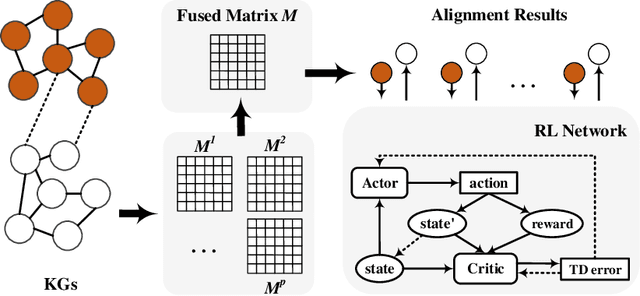

Entity alignment (EA) is the task of identifying the entities that refer to the same real-world object but are located in different knowledge graphs (KGs). For entities to be aligned, existing EA solutions treat them separately and generate alignment results as ranked lists of entities on the other side. Nevertheless, this decision-making paradigm fails to take into account the interdependence among entities. Although some recent efforts mitigate this issue by imposing the 1-to-1 constraint on the alignment process, they still cannot adequately model the underlying interdependence and the results tend to be sub-optimal. To fill in this gap, in this work, we delve into the dynamics of the decision-making process, and offer a reinforcement learning (RL) based model to align entities collectively. Under the RL framework, we devise the coherence and exclusiveness constraints to characterize the interdependence and restrict collective alignment. Additionally, to generate more precise inputs to the RL framework, we employ representative features to capture different aspects of the similarity between entities in heterogeneous KGs, which are integrated by an adaptive feature fusion strategy. Our proposal is evaluated on both cross-lingual and mono-lingual EA benchmarks and compared against state-of-the-art solutions. The empirical results verify its effectiveness and superiority.
Degree-Aware Alignment for Entities in Tail
May 25, 2020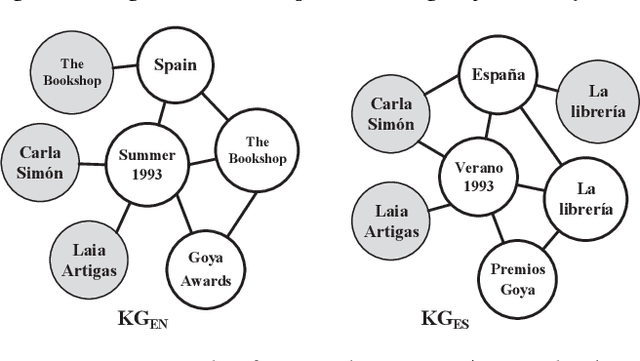
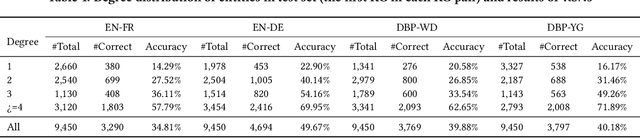
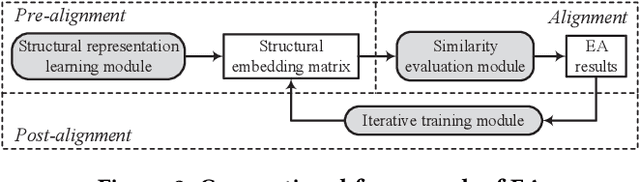
Entity alignment (EA) is to discover equivalent entities in knowledge graphs (KGs), which bridges heterogeneous sources of information and facilitates the integration of knowledge. Existing EA solutions mainly rely on structural information to align entities, typically through KG embedding. Nonetheless, in real-life KGs, only a few entities are densely connected to others, and the rest majority possess rather sparse neighborhood structure. We refer to the latter as long-tail entities, and observe that such phenomenon arguably limits the use of structural information for EA. To mitigate the issue, we revisit and investigate into the conventional EA pipeline in pursuit of elegant performance. For pre-alignment, we propose to amplify long-tail entities, which are of relatively weak structural information, with entity name information that is generally available (but overlooked) in the form of concatenated power mean word embeddings. For alignment, under a novel complementary framework of consolidating structural and name signals, we identify entity's degree as important guidance to effectively fuse two different sources of information. To this end, a degree-aware co-attention network is conceived, which dynamically adjusts the significance of features in a degree-aware manner. For post-alignment, we propose to complement original KGs with facts from their counterparts by using confident EA results as anchors via iterative training. Comprehensive experimental evaluations validate the superiority of our proposed techniques.
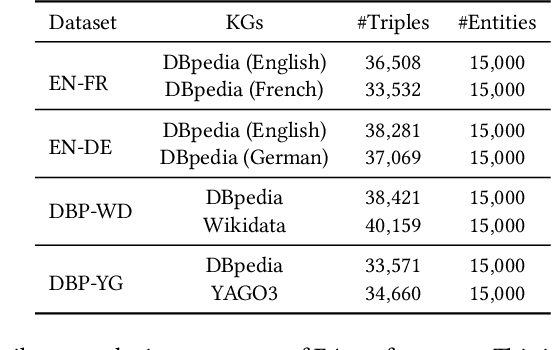
Collective Embedding-based Entity Alignment via Adaptive Features
Dec 18, 2019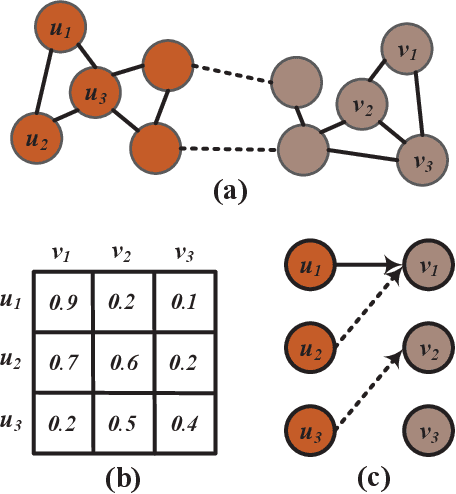
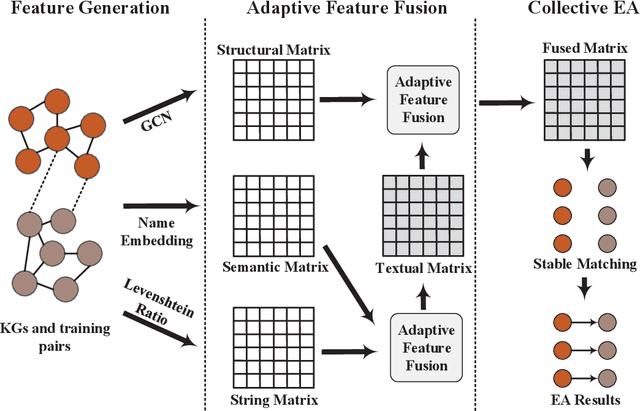
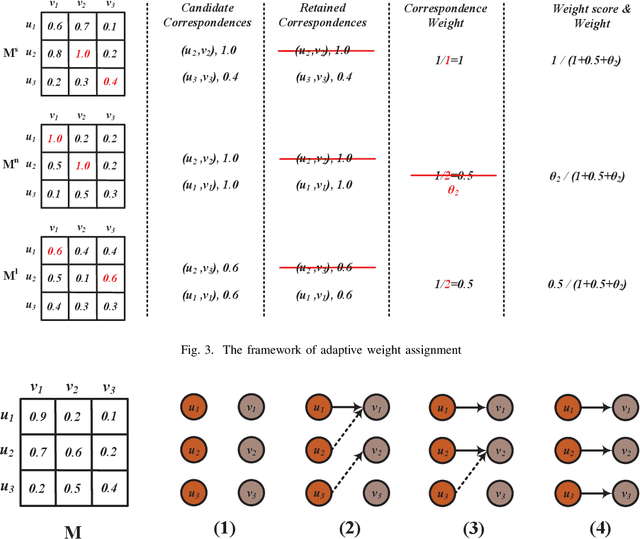

Entity alignment (EA) identifies entities that refer to the same real-world object but locate in different knowledge graphs (KGs), and has been harnessed for KG construction and integration. When generating EA results, current embedding-based solutions treat entities independently and fail to take into account the interdependence between entities. In addition, most of embedding-based EA methods either fuse different features on representation-level and generate unified entity embedding for alignment, which potentially causes information loss, or aggregate features on outcome-level with hand-tuned weights, which is not practical with increasing numbers of features. To tackle these deficiencies, we propose a collective embedding-based EA framework with adaptive feature fusion mechanism. We first employ three representative features, i.e., structural, semantic and string signals, for capturing different aspects of the similarity between entities in heterogeneous KGs. These features are then integrated at outcome-level, with dynamically assigned weights generated by our carefully devised adaptive feature fusion strategy. Eventually, in order to make collective EA decisions, we formulate EA as the classical stable matching problem between entities to be aligned, with preference lists constructed using fused feature matrix. It is further effectively solved by deferred acceptance algorithm. Our proposal is evaluated on both cross-lingual and mono-lingual EA benchmarks against state-of-the-art solutions, and the empirical results verify its effectiveness and superiority. We also perform ablation study to gain insights into framework modules.
Plug and Play! A Simple, Universal Model for Energy Disaggregation
Apr 07, 2014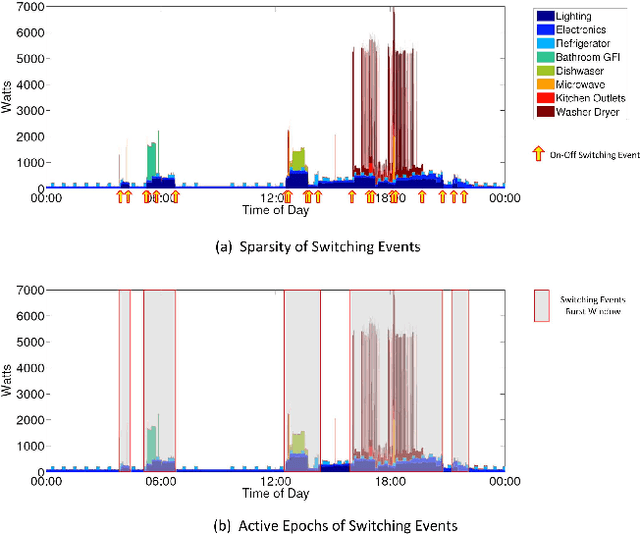


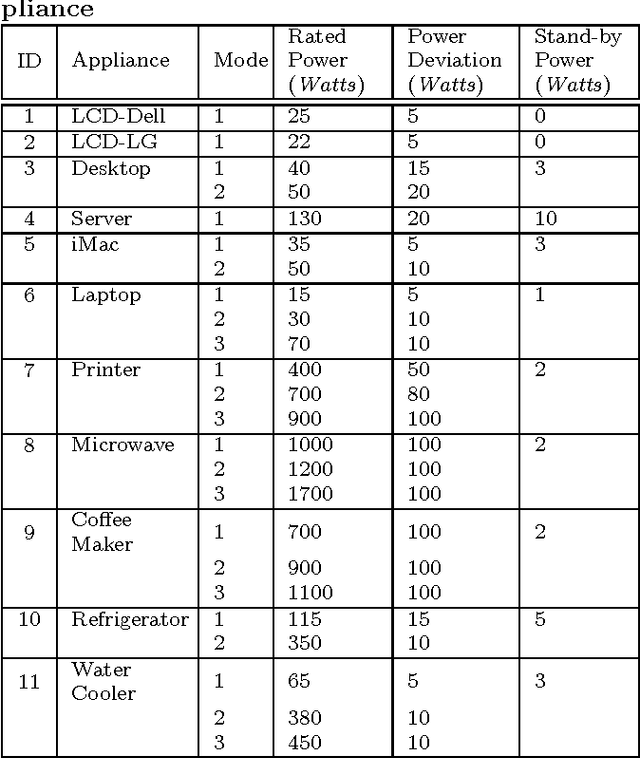
Energy disaggregation is to discover the energy consumption of individual appliances from their aggregated energy values. To solve the problem, most existing approaches rely on either appliances' signatures or their state transition patterns, both hard to obtain in practice. Aiming at developing a simple, universal model that works without depending on sophisticated machine learning techniques or auxiliary equipments, we make use of easily accessible knowledge of appliances and the sparsity of the switching events to design a Sparse Switching Event Recovering (SSER) method. By minimizing the total variation (TV) of the (sparse) event matrix, SSER can effectively recover the individual energy consumption values from the aggregated ones. To speed up the process, a Parallel Local Optimization Algorithm (PLOA) is proposed to solve the problem in active epochs of appliance activities in parallel. Using real-world trace data, we compare the performance of our method with that of the state-of-the-art solutions, including Least Square Estimation (LSE) and iterative Hidden Markov Model (HMM). The results show that our approach has an overall higher detection accuracy and a smaller overhead.