 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Entity Alignment in Hyperbolic Space
Paper and Code
Jun 07, 2021
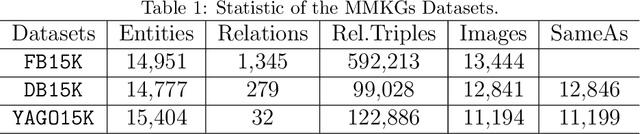

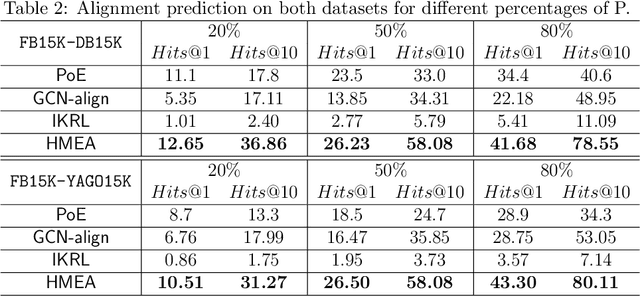
Many AI-related tasks involve the interactions of data in multiple modalities. It has been a new trend to merge multi-modal information into knowledge graph(KG), resulting in multi-modal knowledge graphs (MMKG). However, MMKGs usually suffer from low coverage and incompleteness. To mitigate this problem, a viable approach is to integrate complementary knowledge from other MMKGs. To this end, although existing entity alignment approaches could be adopted, they operate in the Euclidean space, and the resulting Euclidean entity representations can lead to large distortion of KG's hierarchical structure. Besides, the visual information has yet not been well exploited. In response to these issues, in this work, we propose a novel multi-modal entity alignment approach, Hyperbolic multi-modal entity alignment(HMEA), which extends the Euclidean representation to hyperboloid manifold. We first adopt the Hyperbolic Graph Convolutional Networks (HGCNs) to learn structural representations of entities. Regarding the visual information, we generate image embeddings using the densenet model, which are also projected into the hyperbolic space using HGCNs. Finally, we combine the structure and visual representations in the hyperbolic space and use the aggregated embeddings to predict potential alignment results. Extensive experiments and ablation studies demonstrate the effectiveness of our proposed model and its components.