 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled Dynamics Attractor Transformer
Jun 13, 2026Transformer architectures have dramatically advanced representation learning and inference in deep models through self-attention mechanisms. In parallel,associative memory (AM) frameworks map representations onto energy landscapes, offering interpretable retrieval mechanisms. However, their continuous-time inference dynamics lack the biological plausibility of classical Continuous Attractor Neural Networks (CANNs). To bridge this gap, we propose Controlled Dynamics Attractor Transformer (CDAT), which couples a mixture von Mises-Fisher (Mo-vMF) attention energy with a Hopfield refinement energy, while augmenting energy descent with a CANN-inspired excitation-inhibition modulation. CDAT instantiates a topology-constrained dynamical system whose couplings encode relational structure among tokens, thereby linking attractor-style dynamics to modern energy-based attention. We further provide a constructive dissipation analysis to formally establish their controlled inference dynamics. Benefiting from these robust and structured dynamics, CDAT achieves state-of-the-art performance across multiple benchmarks in graph anomaly detection and graph classification.
* 20pages,3 figures
TED: Related Party Transaction guided Tax Evasion Detection on Heterogeneous Graph
May 26, 2026Tax evasion causes severe losses of government revenues and disturbs the economic order of fair competition. To help alleviate this problem, the latest tax evasion detection solutions utilize expert knowledge to extract features and then train classifiers to determine whether a company is suspected of tax evasion. However, existing solutions mainly focus on the statistical features of the company, but fail to exploit the rich interactive information in tax scenarios, which affect the detection performance. In this paper, we first model the tax scenario as a heterogeneous graph and study the tax evasion detection problem under the heterogeneous graph model. To improve the performance of tax evasion detection, a novel graph neural network model is proposed to extract the comprehensive information of heterogeneous graphs. Specifically, we use heterogeneous and complex related party transaction groups to filter low-level noise information. Moreover, a hierarchical attention mechanism is designed to capture the deeper structure and semantic information hidden in the related party transaction group. We apply our method to the real risk management system of the tax bureau, and evaluate it on two human-labeled real-world tax datasets. The results demonstrate that our method significantly outperforms the state-of-the-art in the tax evasion detection task.
CLDG: Contrastive Learning on Dynamic Graphs
Dec 19, 2024



The graph with complex annotations is the most potent data type, whose constantly evolving motivates further exploration of the unsupervised dynamic graph representation. One of the representative paradigms is graph contrastive learning. It constructs self-supervised signals by maximizing the mutual information between the statistic graph's augmentation views. However, the semantics and labels may change within the augmentation process, causing a significant performance drop in downstream tasks. This drawback becomes greatly magnified on dynamic graphs. To address this problem, we designed a simple yet effective framework named CLDG. Firstly, we elaborate that dynamic graphs have temporal translation invariance at different levels. Then, we proposed a sampling layer to extract the temporally-persistent signals. It will encourage the node to maintain consistent local and global representations, i.e., temporal translation invariance under the timespan views. The extensive experiments demonstrate the effectiveness and efficiency of the method on seven datasets by outperforming eight unsupervised state-of-the-art baselines and showing competitiveness against four semi-supervised methods. Compared with the existing dynamic graph method, the number of model parameters and training time is reduced by an average of 2,001.86 times and 130.31 times on seven datasets, respectively.
Learning to Rematch Mismatched Pairs for Robust Cross-Modal Retrieval
Mar 08, 2024



Collecting well-matched multimedia datasets is crucial for training cross-modal retrieval models. However, in real-world scenarios, massive multimodal data are harvested from the Internet, which inevitably contains Partially Mismatched Pairs (PMPs). Undoubtedly, such semantical irrelevant data will remarkably harm the cross-modal retrieval performance. Previous efforts tend to mitigate this problem by estimating a soft correspondence to down-weight the contribution of PMPs. In this paper, we aim to address this challenge from a new perspective: the potential semantic similarity among unpaired samples makes it possible to excavate useful knowledge from mismatched pairs. To achieve this, we propose L2RM, a general framework based on Optimal Transport (OT) that learns to rematch mismatched pairs. In detail, L2RM aims to generate refined alignments by seeking a minimal-cost transport plan across different modalities. To formalize the rematching idea in OT, first, we propose a self-supervised cost function that automatically learns from explicit similarity-cost mapping relation. Second, we present to model a partial OT problem while restricting the transport among false positives to further boost refined alignments. Extensive experiments on three benchmarks demonstrate our L2RM significantly improves the robustness against PMPs for existing models. The code is available at https://github.com/hhc1997/L2RM.
Teaching MLP More Graph Information: A Three-stage Multitask Knowledge Distillation Framework
Mar 02, 2024We study the challenging problem for inference tasks on large-scale graph datasets of Graph Neural Networks: huge time and memory consumption, and try to overcome it by reducing reliance on graph structure. Even though distilling graph knowledge to student MLP is an excellent idea, it faces two major problems of positional information loss and low generalization. To solve the problems, we propose a new three-stage multitask distillation framework. In detail, we use Positional Encoding to capture positional information. Also, we introduce Neural Heat Kernels responsible for graph data processing in GNN and utilize hidden layer outputs matching for better performance of student MLP's hidden layers. To the best of our knowledge, it is the first work to include hidden layer distillation for student MLP on graphs and to combine graph Positional Encoding with MLP. We test its performance and robustness with several settings and draw the conclusion that our work can outperform well with good stability.
Disentangled Representation Learning with Transmitted Information Bottleneck
Nov 03, 2023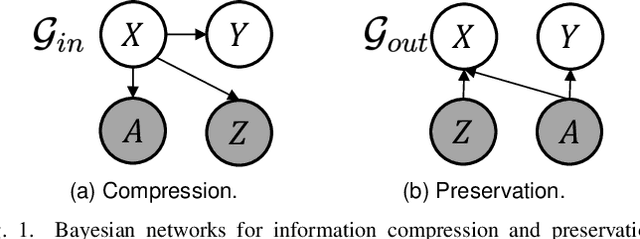



Encoding only the task-related information from the raw data, \ie, disentangled representation learning, can greatly contribute to the robustness and generalizability of models. Although significant advances have been made by regularizing the information in representations with information theory, two major challenges remain: 1) the representation compression inevitably leads to performance drop; 2) the disentanglement constraints on representations are in complicated optimization. To these issues, we introduce Bayesian networks with transmitted information to formulate the interaction among input and representations during disentanglement. Building upon this framework, we propose \textbf{DisTIB} (\textbf{T}ransmitted \textbf{I}nformation \textbf{B}ottleneck for \textbf{Dis}entangled representation learning), a novel objective that navigates the balance between information compression and preservation. We employ variational inference to derive a tractable estimation for DisTIB. This estimation can be simply optimized via standard gradient descent with a reparameterization trick. Moreover, we theoretically prove that DisTIB can achieve optimal disentanglement, underscoring its superior efficacy. To solidify our claims, we conduct extensive experiments on various downstream tasks to demonstrate the appealing efficacy of DisTIB and validate our theoretical analyses.
A Diffusion Weighted Graph Framework for New Intent Discovery
Oct 24, 2023New Intent Discovery (NID) aims to recognize both new and known intents from unlabeled data with the aid of limited labeled data containing only known intents. Without considering structure relationships between samples, previous methods generate noisy supervisory signals which cannot strike a balance between quantity and quality, hindering the formation of new intent clusters and effective transfer of the pre-training knowledge. To mitigate this limitation, we propose a novel Diffusion Weighted Graph Framework (DWGF) to capture both semantic similarities and structure relationships inherent in data, enabling more sufficient and reliable supervisory signals. Specifically, for each sample, we diffuse neighborhood relationships along semantic paths guided by the nearest neighbors for multiple hops to characterize its local structure discriminately. Then, we sample its positive keys and weigh them based on semantic similarities and local structures for contrastive learning. During inference, we further propose Graph Smoothing Filter (GSF) to explicitly utilize the structure relationships to filter high-frequency noise embodied in semantically ambiguous samples on the cluster boundary. Extensive experiments show that our method outperforms state-of-the-art models on all evaluation metrics across multiple benchmark datasets. Code and data are available at https://github.com/yibai-shi/DWGF.
DNA: Denoised Neighborhood Aggregation for Fine-grained Category Discovery
Oct 16, 2023Discovering fine-grained categories from coarsely labeled data is a practical and challenging task, which can bridge the gap between the demand for fine-grained analysis and the high annotation cost. Previous works mainly focus on instance-level discrimination to learn low-level features, but ignore semantic similarities between data, which may prevent these models learning compact cluster representations. In this paper, we propose Denoised Neighborhood Aggregation (DNA), a self-supervised framework that encodes semantic structures of data into the embedding space. Specifically, we retrieve k-nearest neighbors of a query as its positive keys to capture semantic similarities between data and then aggregate information from the neighbors to learn compact cluster representations, which can make fine-grained categories more separatable. However, the retrieved neighbors can be noisy and contain many false-positive keys, which can degrade the quality of learned embeddings. To cope with this challenge, we propose three principles to filter out these false neighbors for better representation learning. Furthermore, we theoretically justify that the learning objective of our framework is equivalent to a clustering loss, which can capture semantic similarities between data to form compact fine-grained clusters. Extensive experiments on three benchmark datasets show that our method can retrieve more accurate neighbors (21.31% accuracy improvement) and outperform state-of-the-art models by a large margin (average 9.96% improvement on three metrics). Our code and data are available at https://github.com/Lackel/DNA.
Tile Classification Based Viewport Prediction with Multi-modal Fusion Transformer
Sep 28, 2023Viewport prediction is a crucial aspect of tile-based 360 video streaming system. However, existing trajectory based methods lack of robustness, also oversimplify the process of information construction and fusion between different modality inputs, leading to the error accumulation problem. In this paper, we propose a tile classification based viewport prediction method with Multi-modal Fusion Transformer, namely MFTR. Specifically, MFTR utilizes transformer-based networks to extract the long-range dependencies within each modality, then mine intra- and inter-modality relations to capture the combined impact of user historical inputs and video contents on future viewport selection. In addition, MFTR categorizes future tiles into two categories: user interested or not, and selects future viewport as the region that contains most user interested tiles. Comparing with predicting head trajectories, choosing future viewport based on tile's binary classification results exhibits better robustness and interpretability. To evaluate our proposed MFTR, we conduct extensive experiments on two widely used PVS-HM and Xu-Gaze dataset. MFTR shows superior performance over state-of-the-art methods in terms of average prediction accuracy and overlap ratio, also presents competitive computation efficiency.
PSDiff: Diffusion Model for Person Search with Iterative and Collaborative Refinement
Sep 20, 2023



Dominant Person Search methods aim to localize and recognize query persons in a unified network, which jointly optimizes two sub-tasks, \ie, detection and Re-IDentification (ReID). Despite significant progress, two major challenges remain: 1) Detection-prior modules in previous methods are suboptimal for the ReID task. 2) The collaboration between two sub-tasks is ignored. To alleviate these issues, we present a novel Person Search framework based on the Diffusion model, PSDiff. PSDiff formulates the person search as a dual denoising process from noisy boxes and ReID embeddings to ground truths. Unlike existing methods that follow the Detection-to-ReID paradigm, our denoising paradigm eliminates detection-prior modules to avoid the local-optimum of the ReID task. Following the new paradigm, we further design a new Collaborative Denoising Layer (CDL) to optimize detection and ReID sub-tasks in an iterative and collaborative way, which makes two sub-tasks mutually beneficial. Extensive experiments on the standard benchmarks show that PSDiff achieves state-of-the-art performance with fewer parameters and elastic computing overhead.