 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyID: Ultra-Fidelity Universal Identity-Preserving Video Generation from Any Visual References
Mar 26, 2026Identity-preserving video generation offers powerful tools for creative expression, allowing users to customize videos featuring their beloved characters. However, prevailing methods are typically designed and optimized for a single identity reference. This underlying assumption restricts creative flexibility by inadequately accommodating diverse real-world input formats. Relying on a single source also constitutes an ill-posed scenario, causing an inherently ambiguous setting that makes it difficult for the model to faithfully reproduce an identity across novel contexts. To address these issues, we present AnyID, an ultra-fidelity identity-preservation video generation framework that features two core contributions. First, we introduce a scalable omni-referenced architecture that effectively unifies heterogeneous identity inputs (e.g., faces, portraits, and videos) into a cohesive representation. Second, we propose a primary-referenced generation paradigm, which designates one reference as a canonical anchor and uses a novel differential prompt to enable precise, attribute-level controllability. We conduct training on a large-scale, meticulously curated dataset to ensure robustness and high fidelity, and then perform a final fine-tuning stage using reinforcement learning. This process leverages a preference dataset constructed from human evaluations, where annotators performed pairwise comparisons of videos based on two key criteria: identity fidelity and prompt controllability. Extensive evaluations validate that AnyID achieves ultra-high identity fidelity as well as superior attribute-level controllability across different task settings.
DepthArb: Training-Free Depth-Arbitrated Generation for Occlusion-Robust Image Synthesis
Mar 25, 2026Text-to-image diffusion models frequently exhibit deficiencies in synthesizing accurate occlusion relationships of multiple objects, particularly within dense overlapping regions. Existing training-free layout-guided methods predominantly rely on rigid spatial priors that remain agnostic to depth order, often resulting in concept mixing or illogical occlusion. To address these limitations, we propose DepthArb, a training-free framework that resolves occlusion ambiguities by arbitrating attention competition between interacting objects. Specifically, DepthArb employs two core mechanisms: Attention Arbitration Modulation (AAM), which enforces depth-ordered visibility by suppressing background activations in overlapping regions, and Spatial Compactness Control (SCC), which preserves structural integrity by curbing attention divergence. These mechanisms enable robust occlusion generation without model retraining. To systematically evaluate this capability, we propose OcclBench, a comprehensive benchmark designed to evaluate diverse occlusion scenarios. Extensive evaluations demonstrate that DepthArb consistently outperforms state-of-the-art baselines in both occlusion accuracy and visual fidelity. As a plug-and-play method, DepthArb seamlessly enhances the compositional capabilities of diffusion backbones, offering a novel perspective on spatial layering within generative models.
Memory-guided Prototypical Co-occurrence Learning for Mixed Emotion Recognition
Feb 24, 2026Emotion recognition from multi-modal physiological and behavioral signals plays a pivotal role in affective computing, yet most existing models remain constrained to the prediction of singular emotions in controlled laboratory settings. Real-world human emotional experiences, by contrast, are often characterized by the simultaneous presence of multiple affective states, spurring recent interest in mixed emotion recognition as an emotion distribution learning problem. Current approaches, however, often neglect the valence consistency and structured correlations inherent among coexisting emotions. To address this limitation, we propose a Memory-guided Prototypical Co-occurrence Learning (MPCL) framework that explicitly models emotion co-occurrence patterns. Specifically, we first fuse multi-modal signals via a multi-scale associative memory mechanism. To capture cross-modal semantic relationships, we construct emotion-specific prototype memory banks, yielding rich physiological and behavioral representations, and employ prototype relation distillation to ensure cross-modal alignment in the latent prototype space. Furthermore, inspired by human cognitive memory systems, we introduce a memory retrieval strategy to extract semantic-level co-occurrence associations across emotion categories. Through this bottom-up hierarchical abstraction process, our model learns affectively informative representations for accurate emotion distribution prediction. Comprehensive experiments on two public datasets demonstrate that MPCL consistently outperforms state-of-the-art methods in mixed emotion recognition, both quantitatively and qualitatively.
MotionWeaver: Holistic 4D-Anchored Framework for Multi-Humanoid Image Animation
Feb 11, 2026Character image animation, which synthesizes videos of reference characters driven by pose sequences, has advanced rapidly but remains largely limited to single-human settings. Existing methods struggle to generalize to multi-humanoid scenarios, which involve diverse humanoid forms, complex interactions, and frequent occlusions. We address this gap with two key innovations. First, we introduce unified motion representations that extract identity-agnostic motions and explicitly bind them to corresponding characters, enabling generalization across diverse humanoid forms and seamless extension to multi-humanoid scenarios. Second, we propose a holistic 4D-anchored paradigm that constructs a shared 4D space to fuse motion representations with video latents, and further reinforces this process with hierarchical 4D-level supervision to better handle interactions and occlusions. We instantiate these ideas in MotionWeaver, an end-to-end framework for multi-humanoid image animation. To support this setting, we curate a 46-hour dataset of multi-human videos with rich interactions, and construct a 300-video benchmark featuring paired humanoid characters. Quantitative and qualitative experiments demonstrate that MotionWeaver not only achieves state-of-the-art results on our benchmark but also generalizes effectively across diverse humanoid forms, complex interactions, and challenging multi-humanoid scenarios.
SegEarth-R2: Towards Comprehensive Language-guided Segmentation for Remote Sensing Images
Dec 23, 2025Effectively grounding complex language to pixels in remote sensing (RS) images is a critical challenge for applications like disaster response and environmental monitoring. Current models can parse simple, single-target commands but fail when presented with complex geospatial scenarios, e.g., segmenting objects at various granularities, executing multi-target instructions, and interpreting implicit user intent. To drive progress against these failures, we present LaSeRS, the first large-scale dataset built for comprehensive training and evaluation across four critical dimensions of language-guided segmentation: hierarchical granularity, target multiplicity, reasoning requirements, and linguistic variability. By capturing these dimensions, LaSeRS moves beyond simple commands, providing a benchmark for complex geospatial reasoning. This addresses a critical gap: existing datasets oversimplify, leading to sensitivity-prone real-world models. We also propose SegEarth-R2, an MLLM architecture designed for comprehensive language-guided segmentation in RS, which directly confronts these challenges. The model's effectiveness stems from two key improvements: (1) a spatial attention supervision mechanism specifically handles the localization of small objects and their components, and (2) a flexible and efficient segmentation query mechanism that handles both single-target and multi-target scenarios. Experimental results demonstrate that our SegEarth-R2 achieves outstanding performance on LaSeRS and other benchmarks, establishing a powerful baseline for the next generation of geospatial segmentation. All data and code will be released at https://github.com/earth-insights/SegEarth-R2.
MVGSR: Multi-View Consistent 3D Gaussian Super-Resolution via Epipolar Guidance
Dec 17, 2025Scenes reconstructed by 3D Gaussian Splatting (3DGS) trained on low-resolution (LR) images are unsuitable for high-resolution (HR) rendering. Consequently, a 3DGS super-resolution (SR) method is needed to bridge LR inputs and HR rendering. Early 3DGS SR methods rely on single-image SR networks, which lack cross-view consistency and fail to fuse complementary information across views. More recent video-based SR approaches attempt to address this limitation but require strictly sequential frames, limiting their applicability to unstructured multi-view datasets. In this work, we introduce Multi-View Consistent 3D Gaussian Splatting Super-Resolution (MVGSR), a framework that focuses on integrating multi-view information for 3DGS rendering with high-frequency details and enhanced consistency. We first propose an Auxiliary View Selection Method based on camera poses, making our method adaptable for arbitrarily organized multi-view datasets without the need of temporal continuity or data reordering. Furthermore, we introduce, for the first time, an epipolar-constrained multi-view attention mechanism into 3DGS SR, which serves as the core of our proposed multi-view SR network. This design enables the model to selectively aggregate consistent information from auxiliary views, enhancing the geometric consistency and detail fidelity of 3DGS representations. Extensive experiments demonstrate that our method achieves state-of-the-art performance on both object-centric and scene-level 3DGS SR benchmarks.
HGS: Hybrid Gaussian Splatting with Static-Dynamic Decomposition for Compact Dynamic View Synthesis
Dec 16, 2025Dynamic novel view synthesis (NVS) is essential for creating immersive experiences. Existing approaches have advanced dynamic NVS by introducing 3D Gaussian Splatting (3DGS) with implicit deformation fields or indiscriminately assigned time-varying parameters, surpassing NeRF-based methods. However, due to excessive model complexity and parameter redundancy, they incur large model sizes and slow rendering speeds, making them inefficient for real-time applications, particularly on resource-constrained devices. To obtain a more efficient model with fewer redundant parameters, in this paper, we propose Hybrid Gaussian Splatting (HGS), a compact and efficient framework explicitly designed to disentangle static and dynamic regions of a scene within a unified representation. The core innovation of HGS lies in our Static-Dynamic Decomposition (SDD) strategy, which leverages Radial Basis Function (RBF) modeling for Gaussian primitives. Specifically, for dynamic regions, we employ time-dependent RBFs to effectively capture temporal variations and handle abrupt scene changes, while for static regions, we reduce redundancy by sharing temporally invariant parameters. Additionally, we introduce a two-stage training strategy tailored for explicit models to enhance temporal coherence at static-dynamic boundaries. Experimental results demonstrate that our method reduces model size by up to 98% and achieves real-time rendering at up to 125 FPS at 4K resolution on a single RTX 3090 GPU. It further sustains 160 FPS at 1352 * 1014 on an RTX 3050 and has been integrated into the VR system. Moreover, HGS achieves comparable rendering quality to state-of-the-art methods while providing significantly improved visual fidelity for high-frequency details and abrupt scene changes.
ZoomEarth: Active Perception for Ultra-High-Resolution Geospatial Vision-Language Tasks
Nov 15, 2025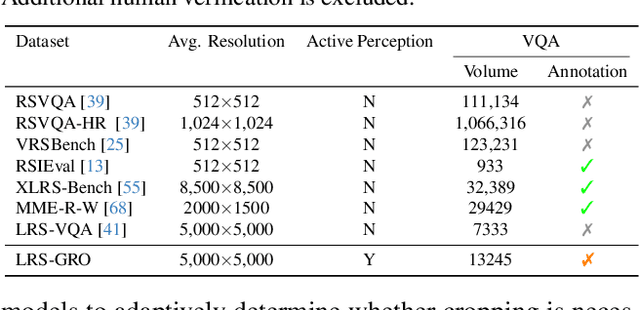
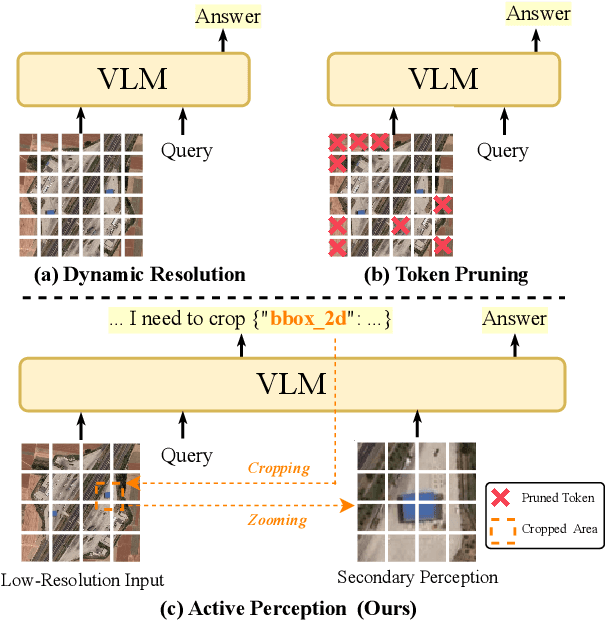
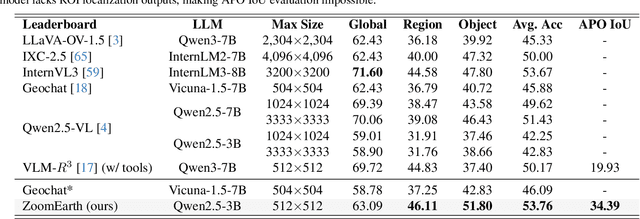
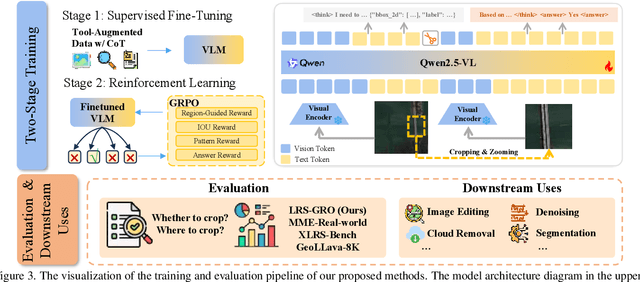
Ultra-high-resolution (UHR) remote sensing (RS) images offer rich fine-grained information but also present challenges in effective processing. Existing dynamic resolution and token pruning methods are constrained by a passive perception paradigm, suffering from increased redundancy when obtaining finer visual inputs. In this work, we explore a new active perception paradigm that enables models to revisit information-rich regions. First, we present LRS-GRO, a large-scale benchmark dataset tailored for active perception in UHR RS processing, encompassing 17 question types across global, region, and object levels, annotated via a semi-automatic pipeline. Building on LRS-GRO, we propose ZoomEarth, an adaptive cropping-zooming framework with a novel Region-Guided reward that provides fine-grained guidance. Trained via supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO), ZoomEarth achieves state-of-the-art performance on LRS-GRO and, in the zero-shot setting, on three public UHR remote sensing benchmarks. Furthermore, ZoomEarth can be seamlessly integrated with downstream models for tasks such as cloud removal, denoising, segmentation, and image editing through simple tool interfaces, demonstrating strong versatility and extensibility.
InfoSAM: Fine-Tuning the Segment Anything Model from An Information-Theoretic Perspective
May 28, 2025The Segment Anything Model (SAM), a vision foundation model, exhibits impressive zero-shot capabilities in general tasks but struggles in specialized domains. Parameter-efficient fine-tuning (PEFT) is a promising approach to unleash the potential of SAM in novel scenarios. However, existing PEFT methods for SAM neglect the domain-invariant relations encoded in the pre-trained model. To bridge this gap, we propose InfoSAM, an information-theoretic approach that enhances SAM fine-tuning by distilling and preserving its pre-trained segmentation knowledge. Specifically, we formulate the knowledge transfer process as two novel mutual information-based objectives: (i) to compress the domain-invariant relation extracted from pre-trained SAM, excluding pseudo-invariant information as possible, and (ii) to maximize mutual information between the relational knowledge learned by the teacher (pre-trained SAM) and the student (fine-tuned model). The proposed InfoSAM establishes a robust distillation framework for PEFT of SAM. Extensive experiments across diverse benchmarks validate InfoSAM's effectiveness in improving SAM family's performance on real-world tasks, demonstrating its adaptability and superiority in handling specialized scenarios.
DynamicID: Zero-Shot Multi-ID Image Personalization with Flexible Facial Editability
Mar 09, 2025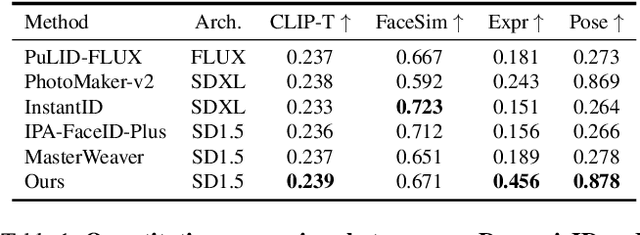

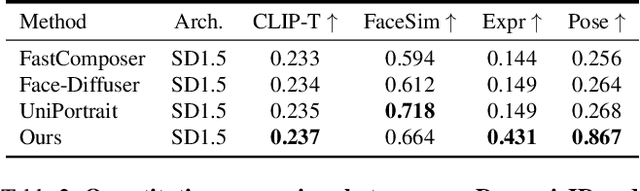
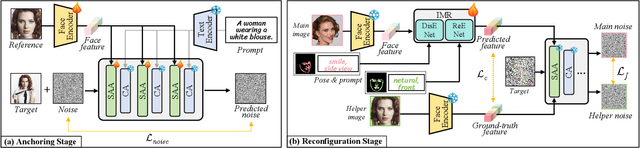
Recent advancements in text-to-image generation have spurred interest in personalized human image generation, which aims to create novel images featuring specific human identities as reference images indicate. Although existing methods achieve high-fidelity identity preservation, they often struggle with limited multi-ID usability and inadequate facial editability. We present DynamicID, a tuning-free framework supported by a dual-stage training paradigm that inherently facilitates both single-ID and multi-ID personalized generation with high fidelity and flexible facial editability. Our key innovations include: 1) Semantic-Activated Attention (SAA), which employs query-level activation gating to minimize disruption to the original model when injecting ID features and achieve multi-ID personalization without requiring multi-ID samples during training. 2) Identity-Motion Reconfigurator (IMR), which leverages contrastive learning to effectively disentangle and re-entangle facial motion and identity features, thereby enabling flexible facial editing. Additionally, we have developed a curated VariFace-10k facial dataset, comprising 10k unique individuals, each represented by 35 distinct facial images. Experimental results demonstrate that DynamicID outperforms state-of-the-art methods in identity fidelity, facial editability, and multi-ID personalization capability.