 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet-based Decoupling Framework for low-light Stereo Image Enhancement
Jul 16, 2025Low-light images suffer from complex degradation, and existing enhancement methods often encode all degradation factors within a single latent space. This leads to highly entangled features and strong black-box characteristics, making the model prone to shortcut learning. To mitigate the above issues, this paper proposes a wavelet-based low-light stereo image enhancement method with feature space decoupling. Our insight comes from the following findings: (1) Wavelet transform enables the independent processing of low-frequency and high-frequency information. (2) Illumination adjustment can be achieved by adjusting the low-frequency component of a low-light image, extracted through multi-level wavelet decomposition. Thus, by using wavelet transform the feature space is decomposed into a low-frequency branch for illumination adjustment and multiple high-frequency branches for texture enhancement. Additionally, stereo low-light image enhancement can extract useful cues from another view to improve enhancement. To this end, we propose a novel high-frequency guided cross-view interaction module (HF-CIM) that operates within high-frequency branches rather than across the entire feature space, effectively extracting valuable image details from the other view. Furthermore, to enhance the high-frequency information, a detail and texture enhancement module (DTEM) is proposed based on cross-attention mechanism. The model is trained on a dataset consisting of images with uniform illumination and images with non-uniform illumination. Experimental results on both real and synthetic images indicate that our algorithm offers significant advantages in light adjustment while effectively recovering high-frequency information. The code and dataset are publicly available at: https://github.com/Cherisherr/WDCI-Net.git.
Accelerating Non-Maximum Suppression: A Graph Theory Perspective
Sep 30, 2024



Non-maximum suppression (NMS) is an indispensable post-processing step in object detection. With the continuous optimization of network models, NMS has become the ``last mile'' to enhance the efficiency of object detection. This paper systematically analyzes NMS from a graph theory perspective for the first time, revealing its intrinsic structure. Consequently, we propose two optimization methods, namely QSI-NMS and BOE-NMS. The former is a fast recursive divide-and-conquer algorithm with negligible mAP loss, and its extended version (eQSI-NMS) achieves optimal complexity of $\mathcal{O}(n\log n)$. The latter, concentrating on the locality of NMS, achieves an optimization at a constant level without an mAP loss penalty. Moreover, to facilitate rapid evaluation of NMS methods for researchers, we introduce NMS-Bench, the first benchmark designed to comprehensively assess various NMS methods. Taking the YOLOv8-N model on MS COCO 2017 as the benchmark setup, our method QSI-NMS provides $6.2\times$ speed of original NMS on the benchmark, with a $0.1\%$ decrease in mAP. The optimal eQSI-NMS, with only a $0.3\%$ mAP decrease, achieves $10.7\times$ speed. Meanwhile, BOE-NMS exhibits $5.1\times$ speed with no compromise in mAP.
Generalized Deepfakes Detection with Reconstructed-Blended Images and Multi-scale Feature Reconstruction Network
Dec 13, 2023
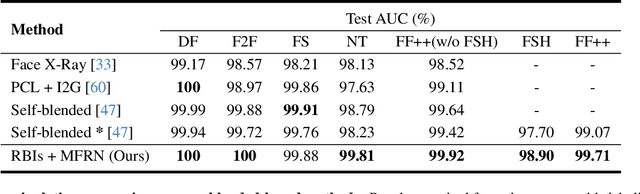
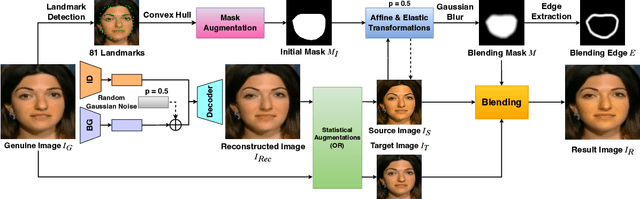
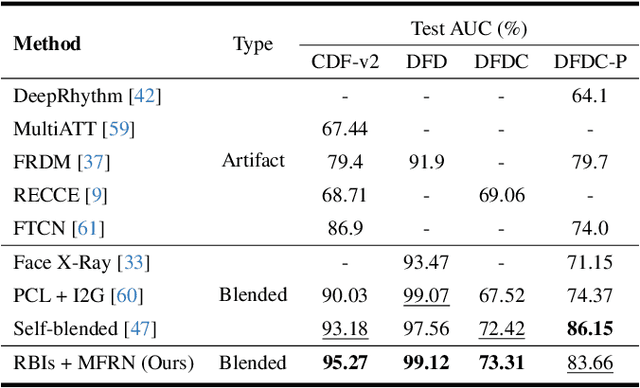
The growing diversity of digital face manipulation techniques has led to an urgent need for a universal and robust detection technology to mitigate the risks posed by malicious forgeries. We present a blended-based detection approach that has robust applicability to unseen datasets. It combines a method for generating synthetic training samples, i.e., reconstructed blended images, that incorporate potential deepfake generator artifacts and a detection model, a multi-scale feature reconstruction network, for capturing the generic boundary artifacts and noise distribution anomalies brought about by digital face manipulations. Experiments demonstrated that this approach results in better performance in both cross-manipulation detection and cross-dataset detection on unseen data.
Face Forgery Detection Based on Facial Region Displacement Trajectory Series
Dec 07, 2022



Deep-learning-based technologies such as deepfakes ones have been attracting widespread attention in both society and academia, particularly ones used to synthesize forged face images. These automatic and professional-skill-free face manipulation technologies can be used to replace the face in an original image or video with any target object while maintaining the expression and demeanor. Since human faces are closely related to identity characteristics, maliciously disseminated identity manipulated videos could trigger a crisis of public trust in the media and could even have serious political, social, and legal implications. To effectively detect manipulated videos, we focus on the position offset in the face blending process, resulting from the forced affine transformation of the normalized forged face. We introduce a method for detecting manipulated videos that is based on the trajectory of the facial region displacement. Specifically, we develop a virtual-anchor-based method for extracting the facial trajectory, which can robustly represent displacement information. This information was used to construct a network for exposing multidimensional artifacts in the trajectory sequences of manipulated videos that is based on dual-stream spatial-temporal graph attention and a gated recurrent unit backbone. Testing of our method on various manipulation datasets demonstrated that its accuracy and generalization ability is competitive with that of the leading detection methods.
CEMENT: Incomplete Multi-View Weak-Label Learning with Long-Tailed Labels
Jan 12, 2022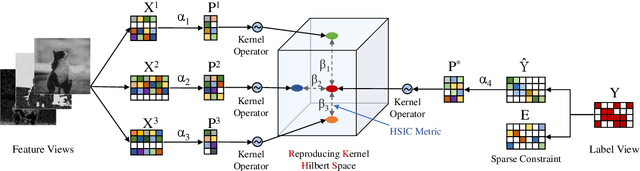

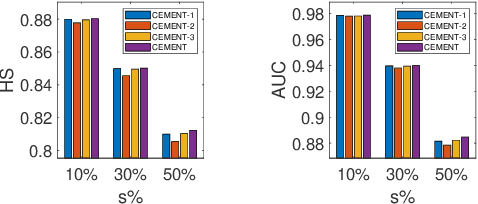
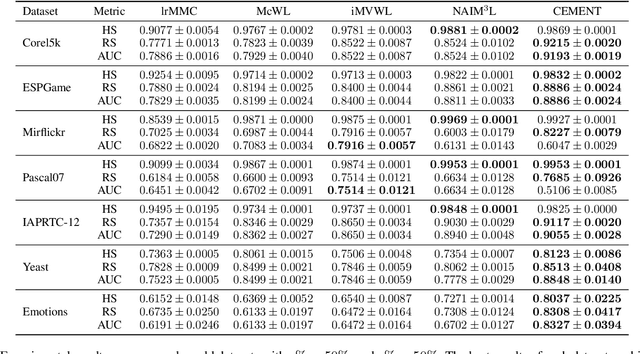
A variety of modern applications exhibit multi-view multi-label learning, where each sample has multi-view features, and multiple labels are correlated via common views. In recent years, several methods have been proposed to cope with it and achieve much success, but still suffer from two key problems: 1) lack the ability to deal with the incomplete multi-view weak-label data, in which only a subset of features and labels are provided for each sample; 2) ignore the presence of noisy views and tail labels usually occurring in real-world problems. In this paper, we propose a novel method, named CEMENT, to overcome the limitations. For 1), CEMENT jointly embeds incomplete views and weak labels into distinct low-dimensional subspaces, and then correlates them via Hilbert-Schmidt Independence Criterion (HSIC). For 2), CEMEMT adaptively learns the weights of embeddings to capture noisy views, and explores an additional sparse component to model tail labels, making the low-rankness available in the multi-label setting. We develop an alternating algorithm to solve the proposed optimization problem. Experimental results on seven real-world datasets demonstrate the effectiveness of the proposed method.
DLO: Direct LiDAR Odometry for 2.5D Outdoor Environment
Sep 15, 2018



For autonomous vehicles, high-precision real-time localization is the guarantee of stable driving. Compared with the visual odometry (VO), the LiDAR odometry (LO) has the advantages of higher accuracy and better stability. However, 2D LO is only suitable for the indoor environment, and 3D LO has less efficiency in general. Both are not suitable for the online localization of an autonomous vehicle in an outdoor driving environment. In this paper, a direct LO method based on the 2.5D grid map is proposed. The fast semi-dense direct method proposed for VO is employed to register two 2.5D maps. Experiments show that this method is superior to both the 3D-NDT and LOAM in the outdoor environment.
Automatic Vector-based Road Structure Mapping Using Multi-beam LiDAR
Jun 06, 2018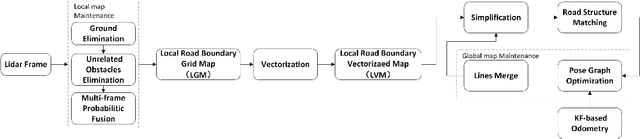

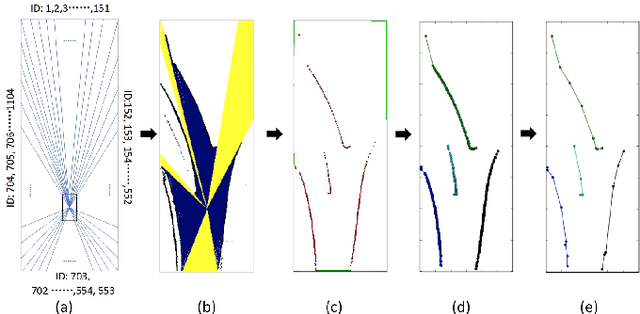
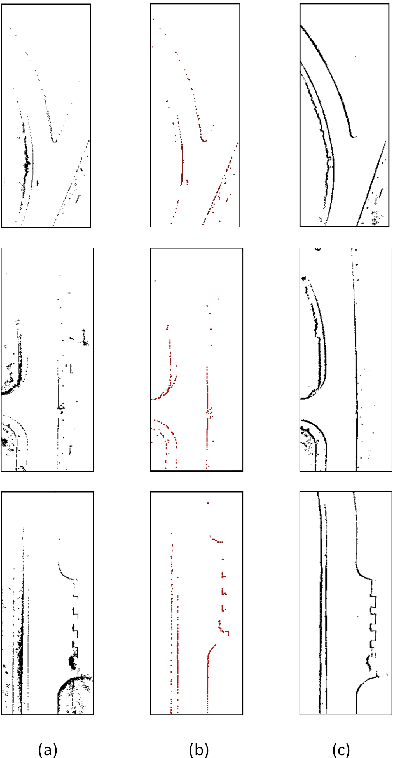
In this paper, we studied a SLAM method for vector-based road structure mapping using multi-beam LiDAR. We propose to use the polyline as the primary mapping element instead of grid cell or point cloud, because the vector-based representation is precise and lightweight, and it can directly generate vector-based High-Definition (HD) driving map as demanded by autonomous driving systems. We explored: 1) the extraction and vectorization of road structures based on local probabilistic fusion. 2) the efficient vector-based matching between frames of road structures. 3) the loop closure and optimization based on the pose-graph. In this study, we took a specific road structure, the road boundary, as an example. We applied the proposed matching method in three different scenes and achieved the average absolute matching error of 0.07. We further applied the mapping system to the urban road with the length of 860 meters and achieved an average global accuracy of 0.466 m without the help of high precision GPS.
TiEV: The Tongji Intelligent Electric Vehicle in the Intelligent Vehicle Future Challenge of China
May 07, 2018
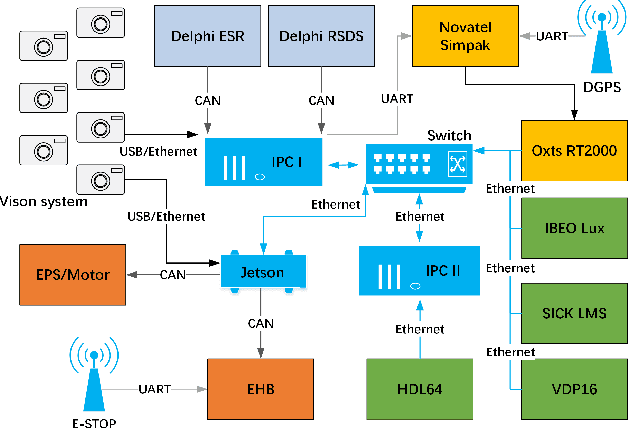
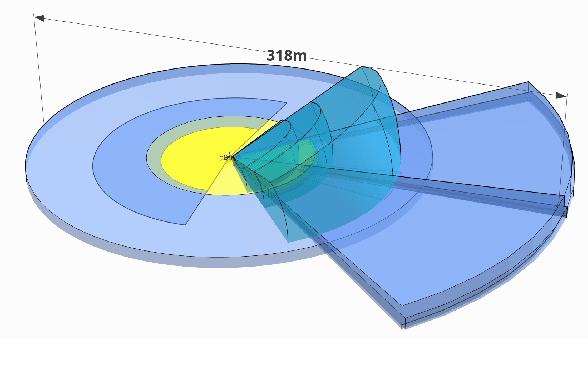
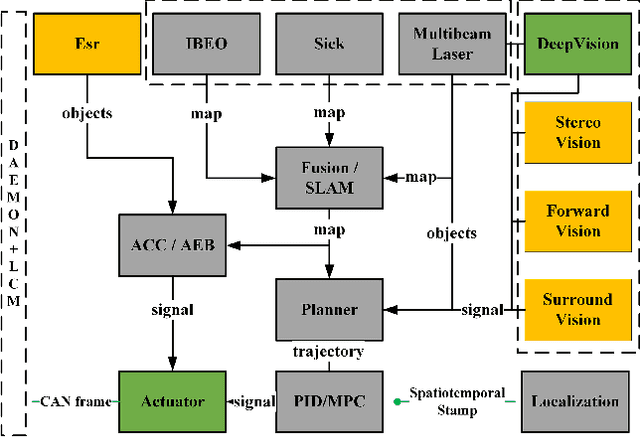
TiEV is an autonomous driving platform implemented by Tongji University of China. The vehicle is drive-by-wire and is fully powered by electricity. We devised the software system of TiEV from scratch, which is capable of driving the vehicle autonomously in urban paths as well as on fast express roads. We describe our whole system, especially novel modules of probabilistic perception fusion, incremental mapping, the 1st and the 2nd planning and the overall safety concern. TiEV finished 2016 and 2017 Intelligent Vehicle Future Challenge of China held at Changshu. We show our experiences on the development of autonomous vehicles and future trends.
MLC Toolbox: A MATLAB/OCTAVE Library for Multi-Label Classification
Apr 09, 2017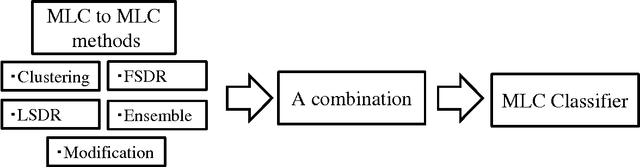

Multi-Label Classification toolbox is a MATLAB/OCTAVE library for Multi-Label Classification (MLC). There exists a few Java libraries for MLC, but no MATLAB/OCTAVE library that covers various methods. This toolbox offers an environment for evaluation, comparison and visualization of the MLC results. One attraction of this toolbox is that it enables us to try many combinations of feature space dimension reduction, sample clustering, label space dimension reduction and ensemble, etc.