 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEMENT: Incomplete Multi-View Weak-Label Learning with Long-Tailed Labels
Paper and Code
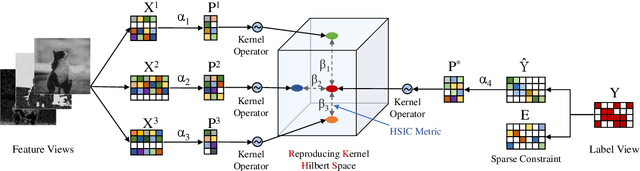

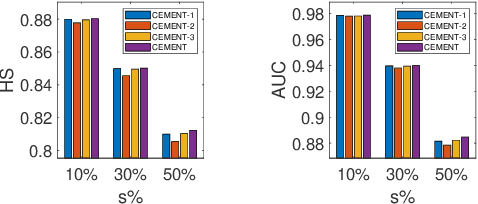
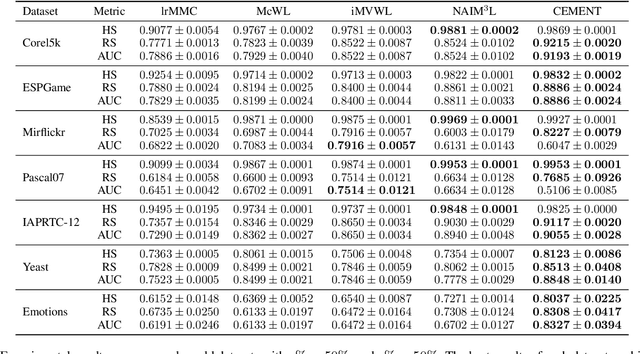
A variety of modern applications exhibit multi-view multi-label learning, where each sample has multi-view features, and multiple labels are correlated via common views. In recent years, several methods have been proposed to cope with it and achieve much success, but still suffer from two key problems: 1) lack the ability to deal with the incomplete multi-view weak-label data, in which only a subset of features and labels are provided for each sample; 2) ignore the presence of noisy views and tail labels usually occurring in real-world problems. In this paper, we propose a novel method, named CEMENT, to overcome the limitations. For 1), CEMENT jointly embeds incomplete views and weak labels into distinct low-dimensional subspaces, and then correlates them via Hilbert-Schmidt Independence Criterion (HSIC). For 2), CEMEMT adaptively learns the weights of embeddings to capture noisy views, and explores an additional sparse component to model tail labels, making the low-rankness available in the multi-label setting. We develop an alternating algorithm to solve the proposed optimization problem. Experimental results on seven real-world datasets demonstrate the effectiveness of the proposed method.