 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
VEU-Bench: Towards Comprehensive Understanding of Video Editing
Apr 24, 2025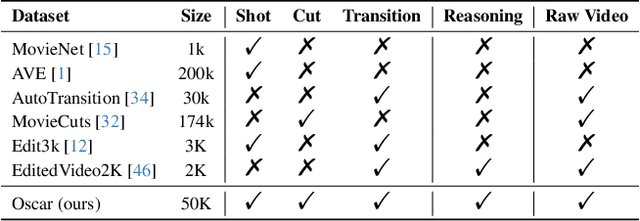
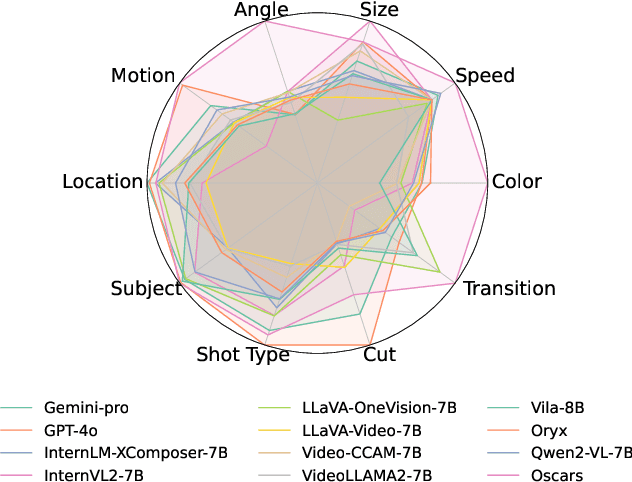
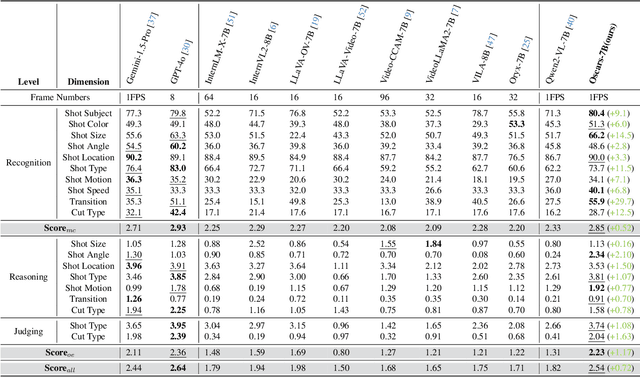
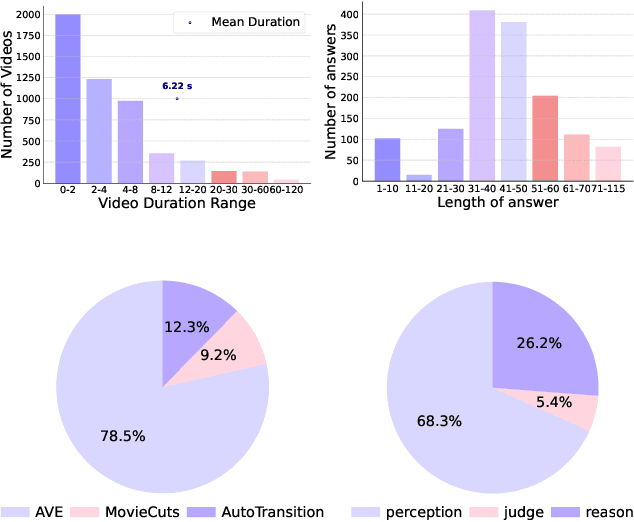
Widely shared videos on the internet are often edited. Recently, although Video Large Language Models (Vid-LLMs) have made great progress in general video understanding tasks, their capabilities in video editing understanding (VEU) tasks remain unexplored. To address this gap, in this paper, we introduce VEU-Bench (Video Editing Understanding Benchmark), a comprehensive benchmark that categorizes video editing components across various dimensions, from intra-frame features like shot size to inter-shot attributes such as cut types and transitions. Unlike previous video editing understanding benchmarks that focus mainly on editing element classification, VEU-Bench encompasses 19 fine-grained tasks across three stages: recognition, reasoning, and judging. To enhance the annotation of VEU automatically, we built an annotation pipeline integrated with an ontology-based knowledge base. Through extensive experiments with 11 state-of-the-art Vid-LLMs, our findings reveal that current Vid-LLMs face significant challenges in VEU tasks, with some performing worse than random choice. To alleviate this issue, we develop Oscars, a VEU expert model fine-tuned on the curated VEU-Bench dataset. It outperforms existing open-source Vid-LLMs on VEU-Bench by over 28.3% in accuracy and achieves performance comparable to commercial models like GPT-4o. We also demonstrate that incorporating VEU data significantly enhances the performance of Vid-LLMs on general video understanding benchmarks, with an average improvement of 8.3% across nine reasoning tasks.
AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era
Apr 15, 2025



Recent advances in image generation, particularly diffusion models, have significantly lowered the barrier for creating sophisticated forgeries, making image manipulation detection and localization (IMDL) increasingly challenging. While prior work in IMDL has focused largely on natural images, the anime domain remains underexplored-despite its growing vulnerability to AI-generated forgeries. Misrepresentations of AI-generated images as hand-drawn artwork, copyright violations, and inappropriate content modifications pose serious threats to the anime community and industry. To address this gap, we propose AnimeDL-2M, the first large-scale benchmark for anime IMDL with comprehensive annotations. It comprises over two million images including real, partially manipulated, and fully AI-generated samples. Experiments indicate that models trained on existing IMDL datasets of natural images perform poorly when applied to anime images, highlighting a clear domain gap between anime and natural images. To better handle IMDL tasks in anime domain, we further propose AniXplore, a novel model tailored to the visual characteristics of anime imagery. Extensive evaluations demonstrate that AniXplore achieves superior performance compared to existing methods. Dataset and code can be found in https://flytweety.github.io/AnimeDL2M/.
ACORD: An Expert-Annotated Retrieval Dataset for Legal Contract Drafting
Jan 11, 2025Information retrieval, specifically contract clause retrieval, is foundational to contract drafting because lawyers rarely draft contracts from scratch; instead, they locate and revise the most relevant precedent. We introduce the Atticus Clause Retrieval Dataset (ACORD), the first retrieval benchmark for contract drafting fully annotated by experts. ACORD focuses on complex contract clauses such as Limitation of Liability, Indemnification, Change of Control, and Most Favored Nation. It includes 114 queries and over 126,000 query-clause pairs, each ranked on a scale from 1 to 5 stars. The task is to find the most relevant precedent clauses to a query. The bi-encoder retriever paired with pointwise LLMs re-rankers shows promising results. However, substantial improvements are still needed to effectively manage the complex legal work typically undertaken by lawyers. As the first retrieval benchmark for contract drafting annotated by experts, ACORD can serve as a valuable IR benchmark for the NLP community.
CorrDiff: Adaptive Delay-aware Detector with Temporal Cue Inputs for Real-time Object Detection
Jan 09, 2025



Real-time object detection takes an essential part in the decision-making process of numerous real-world applications, including collision avoidance and path planning in autonomous driving systems. This paper presents a novel real-time streaming perception method named CorrDiff, designed to tackle the challenge of delays in real-time detection systems. The main contribution of CorrDiff lies in its adaptive delay-aware detector, which is able to utilize runtime-estimated temporal cues to predict objects' locations for multiple future frames, and selectively produce predictions that matches real-world time, effectively compensating for any communication and computational delays. The proposed model outperforms current state-of-the-art methods by leveraging motion estimation and feature enhancement, both for 1) single-frame detection for the current frame or the next frame, in terms of the metric mAP, and 2) the prediction for (multiple) future frame(s), in terms of the metric sAP (The sAP metric is to evaluate object detection algorithms in streaming scenarios, factoring in both latency and accuracy). It demonstrates robust performance across a range of devices, from powerful Tesla V100 to modest RTX 2080Ti, achieving the highest level of perceptual accuracy on all platforms. Unlike most state-of-the-art methods that struggle to complete computation within a single frame on less powerful devices, CorrDiff meets the stringent real-time processing requirements on all kinds of devices. The experimental results emphasize the system's adaptability and its potential to significantly improve the safety and reliability for many real-world systems, such as autonomous driving. Our code is completely open-sourced and is available at https://anonymous.4open.science/r/CorrDiff.
Number it: Temporal Grounding Videos like Flipping Manga
Nov 15, 2024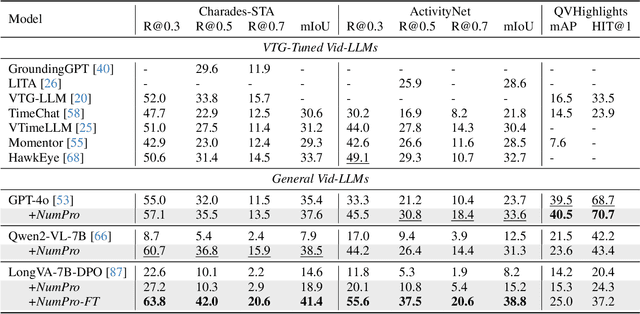

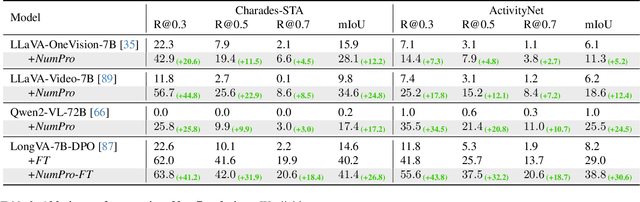
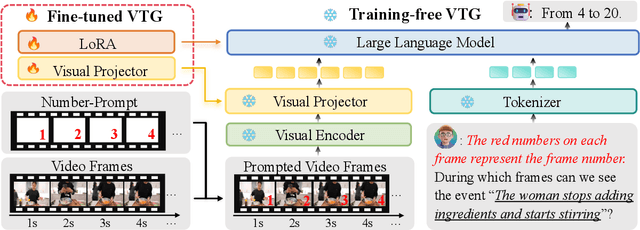
Video Large Language Models (Vid-LLMs) have made remarkable advancements in comprehending video content for QA dialogue. However, they struggle to extend this visual understanding to tasks requiring precise temporal localization, known as Video Temporal Grounding (VTG). To address this gap, we introduce Number-Prompt (NumPro), a novel method that empowers Vid-LLMs to bridge visual comprehension with temporal grounding by adding unique numerical identifiers to each video frame. Treating a video as a sequence of numbered frame images, NumPro transforms VTG into an intuitive process: flipping through manga panels in sequence. This allows Vid-LLMs to "read" event timelines, accurately linking visual content with corresponding temporal information. Our experiments demonstrate that NumPro significantly boosts VTG performance of top-tier Vid-LLMs without additional computational cost. Furthermore, fine-tuning on a NumPro-enhanced dataset defines a new state-of-the-art for VTG, surpassing previous top-performing methods by up to 6.9\% in mIoU for moment retrieval and 8.5\% in mAP for highlight detection. The code will be available at https://github.com/yongliang-wu/NumPro.
Non-Invasive Glucose Prediction System Enhanced by Mixed Linear Models and Meta-Forests for Domain Generalization
Sep 11, 2024In this study, we present a non-invasive glucose prediction system that integrates Near-Infrared (NIR) spectroscopy and millimeter-wave (mm-wave) sensing. We employ a Mixed Linear Model (MixedLM) to analyze the association between mm-wave frequency S_21 parameters and blood glucose levels within a heterogeneous dataset. The MixedLM method considers inter-subject variability and integrates multiple predictors, offering a more comprehensive analysis than traditional correlation analysis. Additionally, we incorporate a Domain Generalization (DG) model, Meta-forests, to effectively handle domain variance in the dataset, enhancing the model's adaptability to individual differences. Our results demonstrate promising accuracy in glucose prediction for unseen subjects, with a mean absolute error (MAE) of 17.47 mg/dL, a root mean square error (RMSE) of 31.83 mg/dL, and a mean absolute percentage error (MAPE) of 10.88%, highlighting its potential for clinical application. This study marks a significant step towards developing accurate, personalized, and non-invasive glucose monitoring systems, contributing to improved diabetes management.
Transtreaming: Adaptive Delay-aware Transformer for Real-time Streaming Perception
Sep 10, 2024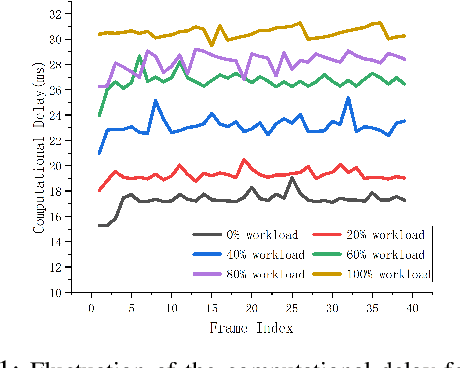



Real-time object detection is critical for the decision-making process for many real-world applications, such as collision avoidance and path planning in autonomous driving. This work presents an innovative real-time streaming perception method, Transtreaming, which addresses the challenge of real-time object detection with dynamic computational delay. The core innovation of Transtreaming lies in its adaptive delay-aware transformer, which can concurrently predict multiple future frames and select the output that best matches the real-world present time, compensating for any system-induced computation delays. The proposed model outperforms the existing state-of-the-art methods, even in single-frame detection scenarios, by leveraging a transformer-based methodology. It demonstrates robust performance across a range of devices, from powerful V100 to modest 2080Ti, achieving the highest level of perceptual accuracy on all platforms. Unlike most state-of-the-art methods that struggle to complete computation within a single frame on less powerful devices, Transtreaming meets the stringent real-time processing requirements on all kinds of devices. The experimental results emphasize the system's adaptability and its potential to significantly improve the safety and reliability for many real-world systems, such as autonomous driving.
Exploring Biomarker Relationships in Both Type 1 and Type 2 Diabetes Mellitus Through a Bayesian Network Analysis Approach
Jun 24, 2024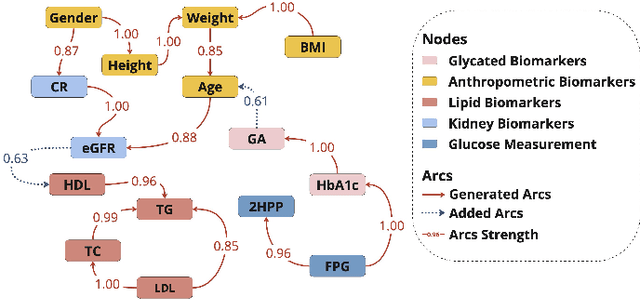
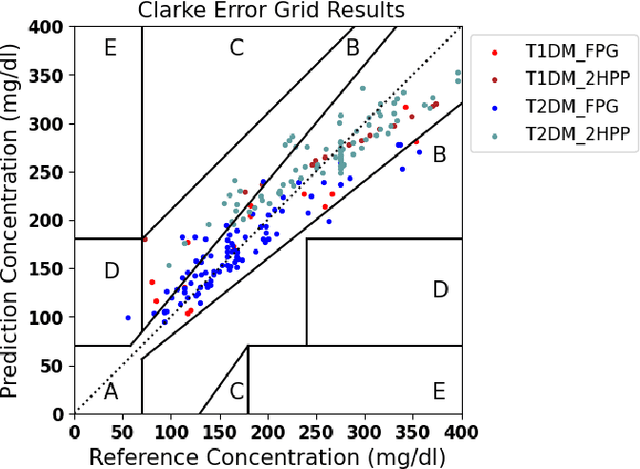
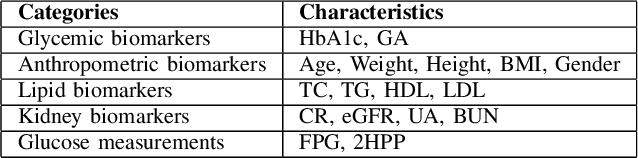
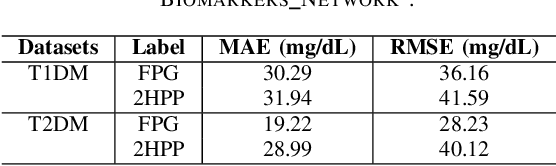
Understanding the complex relationships of biomarkers in diabetes is pivotal for advancing treatment strategies, a pressing need in diabetes research. This study applies Bayesian network structure learning to analyze the Shanghai Type 1 and Type 2 diabetes mellitus datasets, revealing complex relationships among key diabetes-related biomarkers. The constructed Bayesian network presented notable predictive accuracy, particularly for Type 2 diabetes mellitus, with root mean squared error (RMSE) of 18.23 mg/dL, as validated through leave-one-domain experiments and Clarke error grid analysis. This study not only elucidates the intricate dynamics of diabetes through a deeper understanding of biomarker interplay but also underscores the significant potential of integrating data-driven and knowledge-driven methodologies in the realm of personalized diabetes management. Such an approach paves the way for more custom and effective treatment strategies, marking a notable advancement in the field.
Meta-forests: Domain generalization on random forests with meta-learning
Jan 09, 2024Domain generalization is a popular machine learning technique that enables models to perform well on the unseen target domain, by learning from multiple source domains. Domain generalization is useful in cases where data is limited, difficult, or expensive to collect, such as in object recognition and biomedicine. In this paper, we propose a novel domain generalization algorithm called "meta-forests", which builds upon the basic random forests model by incorporating the meta-learning strategy and maximum mean discrepancy measure. The aim of meta-forests is to enhance the generalization ability of classifiers by reducing the correlation among trees and increasing their strength. More specifically, meta-forests conducts meta-learning optimization during each meta-task, while also utilizing the maximum mean discrepancy as a regularization term to penalize poor generalization performance in the meta-test process. To evaluate the effectiveness of our algorithm, we test it on two publicly object recognition datasets and a glucose monitoring dataset that we have used in a previous study. Our results show that meta-forests outperforms state-of-the-art approaches in terms of generalization performance on both object recognition and glucose monitoring datasets.