 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAR-AMTN: Attention Multi-Task Network for Face Attribute Recognition
Jan 04, 2026To enhance the generalization performance of Multi-Task Networks (MTN) in Face Attribute Recognition (FAR), it is crucial to share relevant information across multiple related prediction tasks effectively. Traditional MTN methods create shared low-level modules and distinct high-level modules, causing an exponential increase in model parameters with the addition of tasks. This approach also limits feature interaction at the high level, hindering the exploration of semantic relations among attributes, thereby affecting generalization negatively. In response, this study introduces FAR-AMTN, a novel Attention Multi-Task Network for FAR. It incorporates a Weight-Shared Group-Specific Attention (WSGSA) module with shared parameters to minimize complexity while improving group feature representation. Furthermore, a Cross-Group Feature Fusion (CGFF) module is utilized to foster interactions between attribute groups, enhancing feature learning. A Dynamic Weighting Strategy (DWS) is also introduced for synchronized task convergence. Experiments on the CelebA and LFWA datasets demonstrate that the proposed FAR-AMTN demonstrates superior accuracy with significantly fewer parameters compared to existing models.
* 28 pages, 8figures
Mask-Guided Multi-Task Network for Face Attribute Recognition
Jan 04, 2026Face Attribute Recognition (FAR) plays a crucial role in applications such as person re-identification, face retrieval, and face editing. Conventional multi-task attribute recognition methods often process the entire feature map for feature extraction and attribute classification, which can produce redundant features due to reliance on global regions. To address these challenges, we propose a novel approach emphasizing the selection of specific feature regions for efficient feature learning. We introduce the Mask-Guided Multi-Task Network (MGMTN), which integrates Adaptive Mask Learning (AML) and Group-Global Feature Fusion (G2FF) to address the aforementioned limitations. Leveraging a pre-trained keypoint annotation model and a fully convolutional network, AML accurately localizes critical facial parts (e.g., eye and mouth groups) and generates group masks that delineate meaningful feature regions, thereby mitigating negative transfer from global region usage. Furthermore, G2FF combines group and global features to enhance FAR learning, enabling more precise attribute identification. Extensive experiments on two challenging facial attribute recognition datasets demonstrate the effectiveness of MGMTN in improving FAR performance.
In-Context Learning Enables Robot Action Prediction in LLMs
Oct 16, 2024Recently, Large Language Models (LLMs) have achieved remarkable success using in-context learning (ICL) in the language domain. However, leveraging the ICL capabilities within LLMs to directly predict robot actions remains largely unexplored. In this paper, we introduce RoboPrompt, a framework that enables off-the-shelf text-only LLMs to directly predict robot actions through ICL without training. Our approach first heuristically identifies keyframes that capture important moments from an episode. Next, we extract end-effector actions from these keyframes as well as the estimated initial object poses, and both are converted into textual descriptions. Finally, we construct a structured template to form ICL demonstrations from these textual descriptions and a task instruction. This enables an LLM to directly predict robot actions at test time. Through extensive experiments and analysis, RoboPrompt shows stronger performance over zero-shot and ICL baselines in simulated and real-world settings.
MUSE-Net: Missingness-aware mUlti-branching Self-attention Encoder for Irregular Longitudinal Electronic Health Records
Jun 30, 2024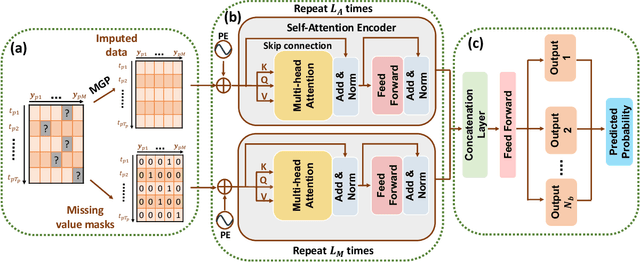

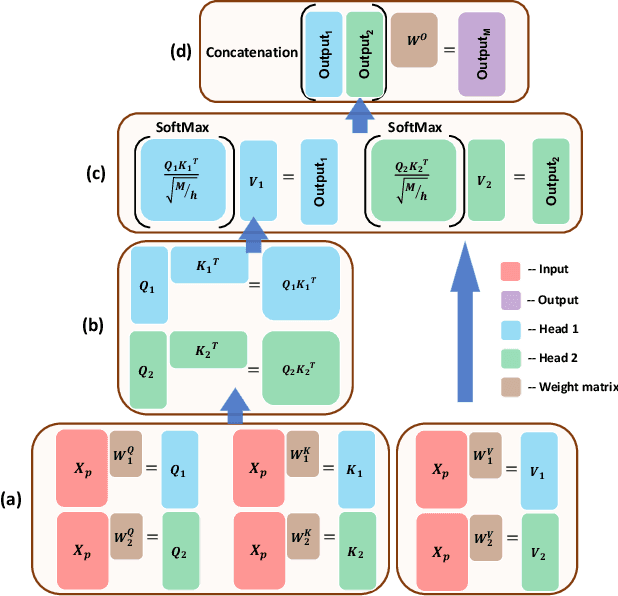
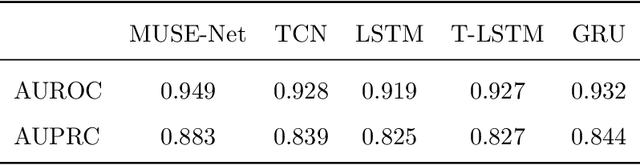
The era of big data has made vast amounts of clinical data readily available, particularly in the form of electronic health records (EHRs), which provides unprecedented opportunities for developing data-driven diagnostic tools to enhance clinical decision making. However, the application of EHRs in data-driven modeling faces challenges such as irregularly spaced multi-variate time series, issues of incompleteness, and data imbalance. Realizing the full data potential of EHRs hinges on the development of advanced analytical models. In this paper, we propose a novel Missingness-aware mUlti-branching Self-attention Encoder (MUSE-Net) to cope with the challenges in modeling longitudinal EHRs for data-driven disease prediction. The MUSE-Net leverages a multi-task Gaussian process (MGP) with missing value masks for data imputation, a multi-branching architecture to address the data imbalance problem, and a time-aware self-attention encoder to account for the irregularly spaced time interval in longitudinal EHRs. We evaluate the proposed MUSE-Net using both synthetic and real-world datasets. Experimental results show that our MUSE-Net outperforms existing methods that are widely used to investigate longitudinal signals.
Exploring Large Language Model based Intelligent Agents: Definitions, Methods, and Prospects
Jan 07, 2024Intelligent agents stand out as a potential path toward artificial general intelligence (AGI). Thus, researchers have dedicated significant effort to diverse implementations for them. Benefiting from recent progress in large language models (LLMs), LLM-based agents that use universal natural language as an interface exhibit robust generalization capabilities across various applications -- from serving as autonomous general-purpose task assistants to applications in coding, social, and economic domains, LLM-based agents offer extensive exploration opportunities. This paper surveys current research to provide an in-depth overview of LLM-based intelligent agents within single-agent and multi-agent systems. It covers their definitions, research frameworks, and foundational components such as their composition, cognitive and planning methods, tool utilization, and responses to environmental feedback. We also delve into the mechanisms of deploying LLM-based agents in multi-agent systems, including multi-role collaboration, message passing, and strategies to alleviate communication issues between agents. The discussions also shed light on popular datasets and application scenarios. We conclude by envisioning prospects for LLM-based agents, considering the evolving landscape of AI and natural language processing.
Better Diffusion Models Further Improve Adversarial Training
Feb 09, 2023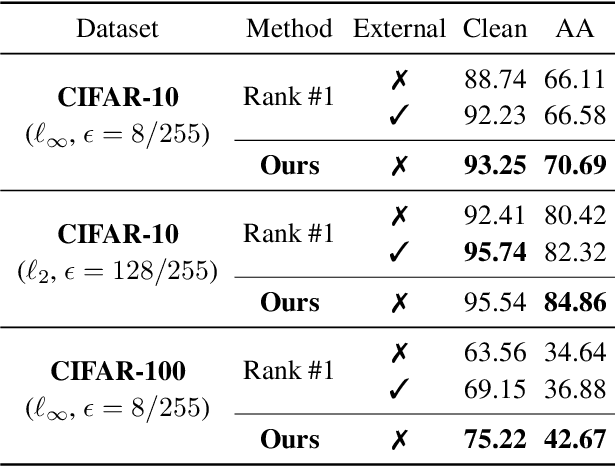
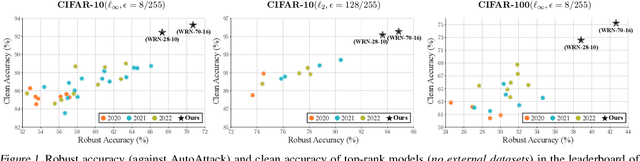
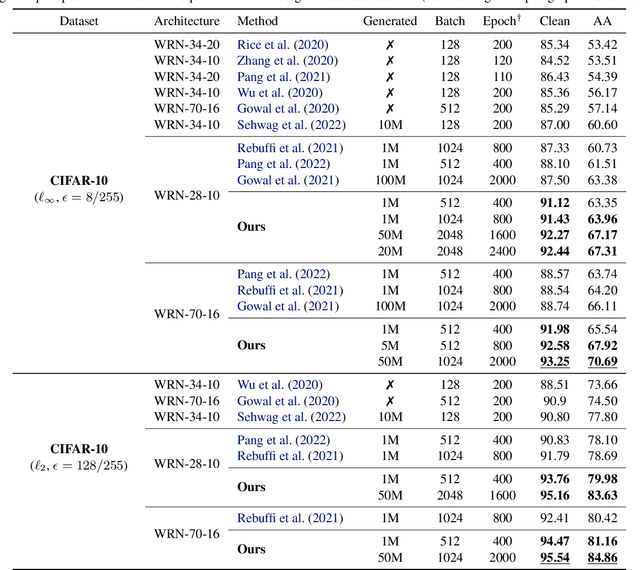
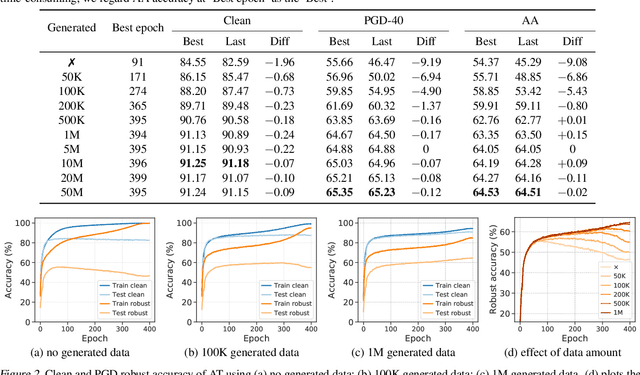
It has been recognized that the data generated by the denoising diffusion probabilistic model (DDPM) improves adversarial training. After two years of rapid development in diffusion models, a question naturally arises: can better diffusion models further improve adversarial training? This paper gives an affirmative answer by employing the most recent diffusion model which has higher efficiency ($\sim 20$ sampling steps) and image quality (lower FID score) compared with DDPM. Our adversarially trained models achieve state-of-the-art performance on RobustBench using only generated data (no external datasets). Under the $\ell_\infty$-norm threat model with $\epsilon=8/255$, our models achieve $70.69\%$ and $42.67\%$ robust accuracy on CIFAR-10 and CIFAR-100, respectively, i.e. improving upon previous state-of-the-art models by $+4.58\%$ and $+8.03\%$. Under the $\ell_2$-norm threat model with $\epsilon=128/255$, our models achieve $84.86\%$ on CIFAR-10 ($+4.44\%$). These results also beat previous works that use external data. Our code is available at https://github.com/wzekai99/DM-Improves-AT.
Hierarchical Deep Learning with Generative Adversarial Network for Automatic Cardiac Diagnosis from ECG Signals
Oct 19, 2022
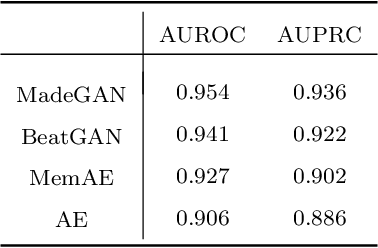

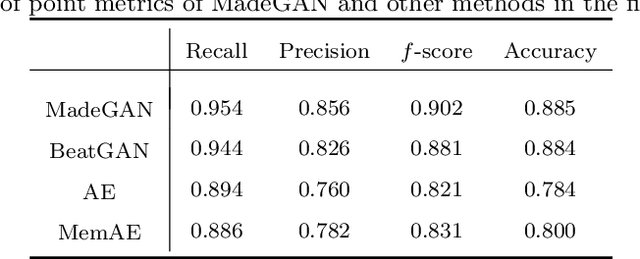
Cardiac disease is the leading cause of death in the US. Accurate heart disease detection is of critical importance for timely medical treatment to save patients' lives. Routine use of electrocardiogram (ECG) is the most common method for physicians to assess the electrical activities of the heart and detect possible abnormal cardiac conditions. Fully utilizing the ECG data for reliable heart disease detection depends on developing effective analytical models. In this paper, we propose a two-level hierarchical deep learning framework with Generative Adversarial Network (GAN) for automatic diagnosis of ECG signals. The first-level model is composed of a Memory-Augmented Deep auto-Encoder with GAN (MadeGAN), which aims to differentiate abnormal signals from normal ECGs for anomaly detection. The second-level learning aims at robust multi-class classification for different arrhythmias identification, which is achieved by integrating the transfer learning technique to transfer knowledge from the first-level learning with the multi-branching architecture to handle the data-lacking and imbalanced data issue. We evaluate the performance of the proposed framework using real-world medical data from the MIT-BIH arrhythmia database. Experimental results show that our proposed model outperforms existing methods that are commonly used in current practice.
FakeTransformer: Exposing Face Forgery From Spatial-Temporal Representation Modeled By Facial Pixel Variations
Nov 15, 2021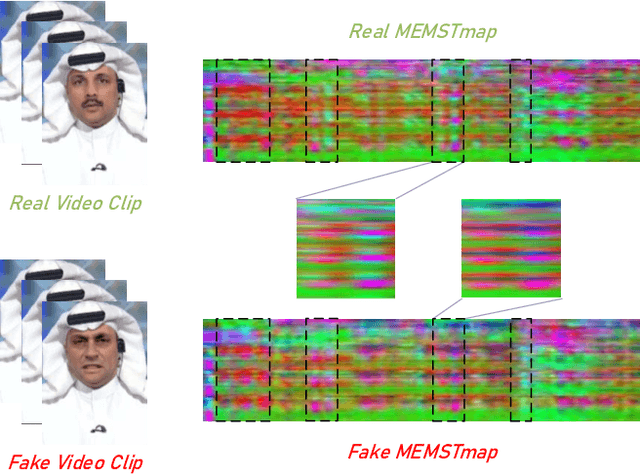
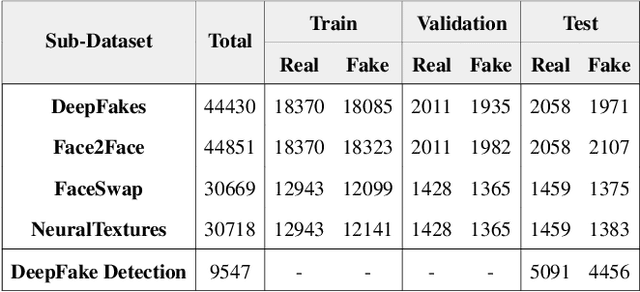
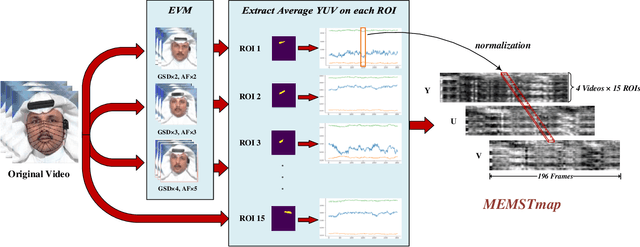
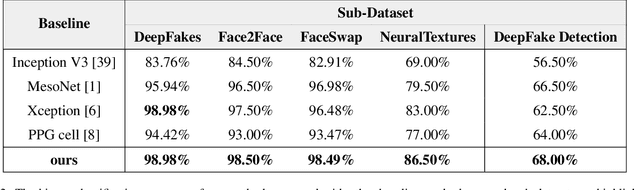
With the rapid development of generation model, AI-based face manipulation technology, which called DeepFakes, has become more and more realistic. This means of face forgery can attack any target, which poses a new threat to personal privacy and property security. Moreover, the misuse of synthetic video shows potential dangers in many areas, such as identity harassment, pornography and news rumors. Inspired by the fact that the spatial coherence and temporal consistency of physiological signal are destroyed in the generated content, we attempt to find inconsistent patterns that can distinguish between real videos and synthetic videos from the variations of facial pixels, which are highly related to physiological information. Our approach first applies Eulerian Video Magnification (EVM) at multiple Gaussian scales to the original video to enlarge the physiological variations caused by the change of facial blood volume, and then transform the original video and magnified videos into a Multi-Scale Eulerian Magnified Spatial-Temporal map (MEMSTmap), which can represent time-varying physiological enhancement sequences on different octaves. Then, these maps are reshaped into frame patches in column units and sent to the vision Transformer to learn the spatio-time descriptors of frame levels. Finally, we sort out the feature embedding and output the probability of judging whether the video is real or fake. We validate our method on the FaceForensics++ and DeepFake Detection datasets. The results show that our model achieves excellent performance in forgery detection, and also show outstanding generalization capability in cross-data domain.