 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
Multi-Objective Large Language Model Unlearning
Dec 29, 2024Machine unlearning in the domain of large language models (LLMs) has attracted great attention recently, which aims to effectively eliminate undesirable behaviors from LLMs without full retraining from scratch. In this paper, we explore the Gradient Ascent (GA) approach in LLM unlearning, which is a proactive way to decrease the prediction probability of the model on the target data in order to remove their influence. We analyze two challenges that render the process impractical: gradient explosion and catastrophic forgetting. To address these issues, we propose Multi-Objective Large Language Model Unlearning (MOLLM) algorithm. We first formulate LLM unlearning as a multi-objective optimization problem, in which the cross-entropy loss is modified to the unlearning version to overcome the gradient explosion issue. A common descent update direction is then calculated, which enables the model to forget the target data while preserving the utility of the LLM. Our empirical results verify that MoLLM outperforms the SOTA GA-based LLM unlearning methods in terms of unlearning effect and model utility preservation.
GuideLight: "Industrial Solution" Guidance for More Practical Traffic Signal Control Agents
Jul 15, 2024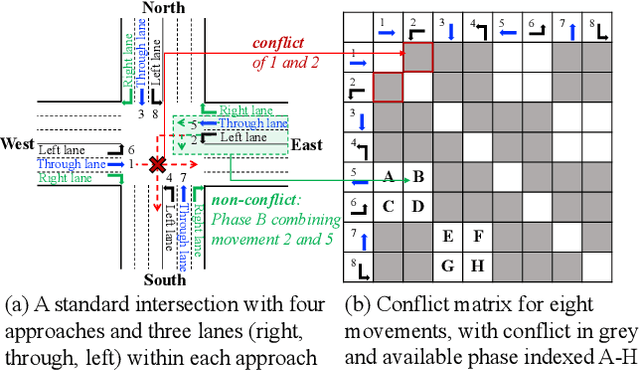
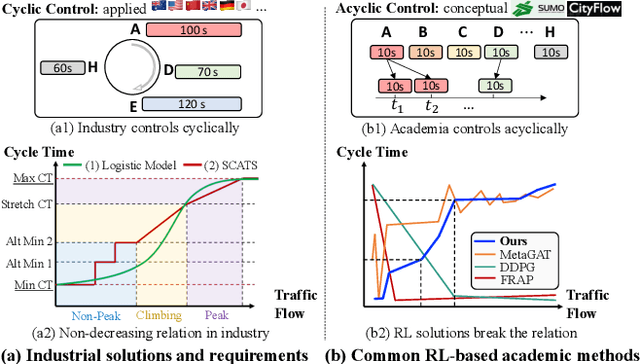
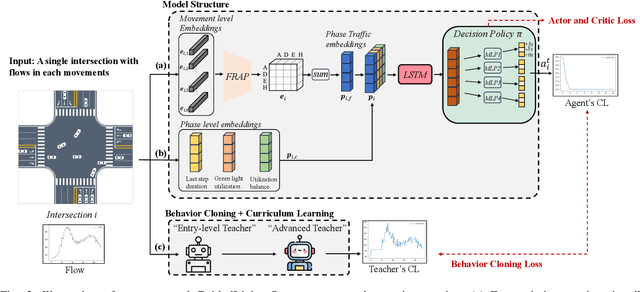
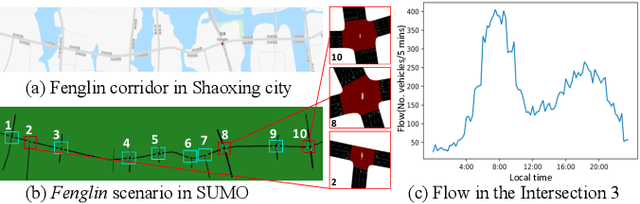
Currently, traffic signal control (TSC) methods based on reinforcement learning (RL) have proven superior to traditional methods. However, most RL methods face difficulties when applied in the real world due to three factors: input, output, and the cycle-flow relation. The industry's observable input is much more limited than simulation-based RL methods. For real-world solutions, only flow can be reliably collected, whereas common RL methods need more. For the output action, most RL methods focus on acyclic control, which real-world signal controllers do not support. Most importantly, industry standards require a consistent cycle-flow relationship: non-decreasing and different response strategies for low, medium, and high-level flows, which is ignored by the RL methods. To narrow the gap between RL methods and industry standards, we innovatively propose to use industry solutions to guide the RL agent. Specifically, we design behavior cloning and curriculum learning to guide the agent to mimic and meet industry requirements and, at the same time, leverage the power of exploration and exploitation in RL for better performance. We theoretically prove that such guidance can largely decrease the sample complexity to polynomials in the horizon when searching for an optimal policy. Our rigid experiments show that our method has good cycle-flow relation and superior performance.
ElecBench: a Power Dispatch Evaluation Benchmark for Large Language Models
Jul 07, 2024In response to the urgent demand for grid stability and the complex challenges posed by renewable energy integration and electricity market dynamics, the power sector increasingly seeks innovative technological solutions. In this context, large language models (LLMs) have become a key technology to improve efficiency and promote intelligent progress in the power sector with their excellent natural language processing, logical reasoning, and generalization capabilities. Despite their potential, the absence of a performance evaluation benchmark for LLM in the power sector has limited the effective application of these technologies. Addressing this gap, our study introduces "ElecBench", an evaluation benchmark of LLMs within the power sector. ElecBench aims to overcome the shortcomings of existing evaluation benchmarks by providing comprehensive coverage of sector-specific scenarios, deepening the testing of professional knowledge, and enhancing decision-making precision. The framework categorizes scenarios into general knowledge and professional business, further divided into six core performance metrics: factuality, logicality, stability, security, fairness, and expressiveness, and is subdivided into 24 sub-metrics, offering profound insights into the capabilities and limitations of LLM applications in the power sector. To ensure transparency, we have made the complete test set public, evaluating the performance of eight LLMs across various scenarios and metrics. ElecBench aspires to serve as the standard benchmark for LLM applications in the power sector, supporting continuous updates of scenarios, metrics, and models to drive technological progress and application.
Survey on Large Language Model-Enhanced Reinforcement Learning: Concept, Taxonomy, and Methods
Mar 30, 2024With extensive pre-trained knowledge and high-level general capabilities, large language models (LLMs) emerge as a promising avenue to augment reinforcement learning (RL) in aspects such as multi-task learning, sample efficiency, and task planning. In this survey, we provide a comprehensive review of the existing literature in $\textit{LLM-enhanced RL}$ and summarize its characteristics compared to conventional RL methods, aiming to clarify the research scope and directions for future studies. Utilizing the classical agent-environment interaction paradigm, we propose a structured taxonomy to systematically categorize LLMs' functionalities in RL, including four roles: information processor, reward designer, decision-maker, and generator. Additionally, for each role, we summarize the methodologies, analyze the specific RL challenges that are mitigated, and provide insights into future directions. Lastly, potential applications, prospective opportunities and challenges of the $\textit{LLM-enhanced RL}$ are discussed.
Data Interpreter: An LLM Agent For Data Science
Mar 12, 2024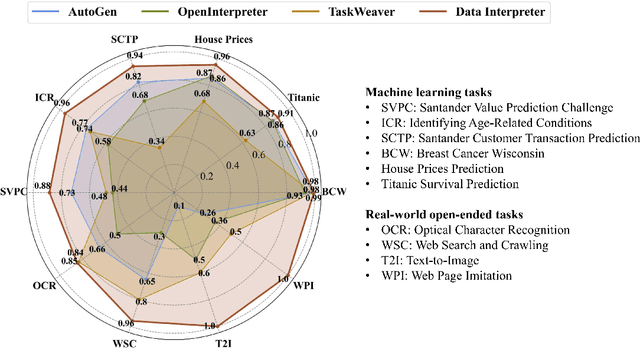
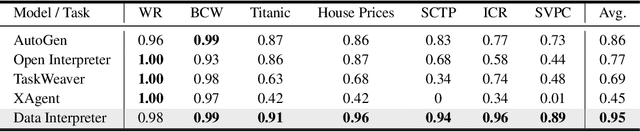
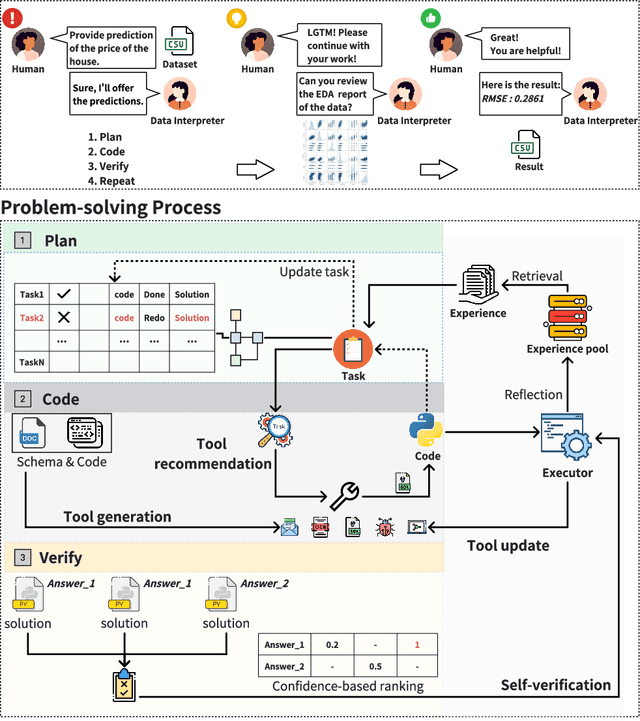

Large Language Model (LLM)-based agents have demonstrated remarkable effectiveness. However, their performance can be compromised in data science scenarios that require real-time data adjustment, expertise in optimization due to complex dependencies among various tasks, and the ability to identify logical errors for precise reasoning. In this study, we introduce the Data Interpreter, a solution designed to solve with code that emphasizes three pivotal techniques to augment problem-solving in data science: 1) dynamic planning with hierarchical graph structures for real-time data adaptability;2) tool integration dynamically to enhance code proficiency during execution, enriching the requisite expertise;3) logical inconsistency identification in feedback, and efficiency enhancement through experience recording. We evaluate the Data Interpreter on various data science and real-world tasks. Compared to open-source baselines, it demonstrated superior performance, exhibiting significant improvements in machine learning tasks, increasing from 0.86 to 0.95. Additionally, it showed a 26% increase in the MATH dataset and a remarkable 112% improvement in open-ended tasks. The solution will be released at https://github.com/geekan/MetaGPT.
Exploring Large Language Model based Intelligent Agents: Definitions, Methods, and Prospects
Jan 07, 2024Intelligent agents stand out as a potential path toward artificial general intelligence (AGI). Thus, researchers have dedicated significant effort to diverse implementations for them. Benefiting from recent progress in large language models (LLMs), LLM-based agents that use universal natural language as an interface exhibit robust generalization capabilities across various applications -- from serving as autonomous general-purpose task assistants to applications in coding, social, and economic domains, LLM-based agents offer extensive exploration opportunities. This paper surveys current research to provide an in-depth overview of LLM-based intelligent agents within single-agent and multi-agent systems. It covers their definitions, research frameworks, and foundational components such as their composition, cognitive and planning methods, tool utilization, and responses to environmental feedback. We also delve into the mechanisms of deploying LLM-based agents in multi-agent systems, including multi-role collaboration, message passing, and strategies to alleviate communication issues between agents. The discussions also shed light on popular datasets and application scenarios. We conclude by envisioning prospects for LLM-based agents, considering the evolving landscape of AI and natural language processing.
MetaGPT: Meta Programming for Multi-Agent Collaborative Framework
Aug 17, 2023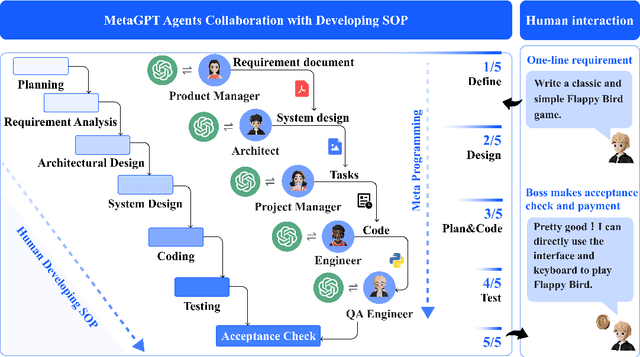
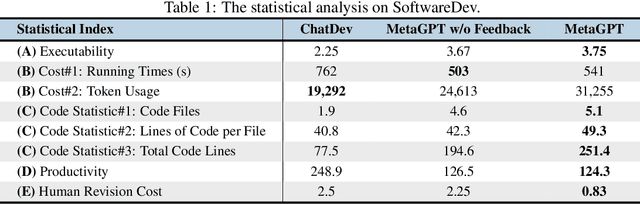
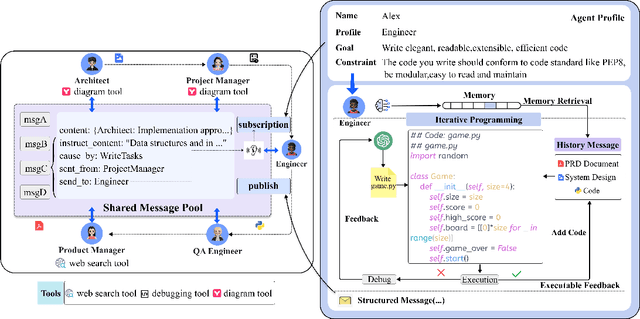
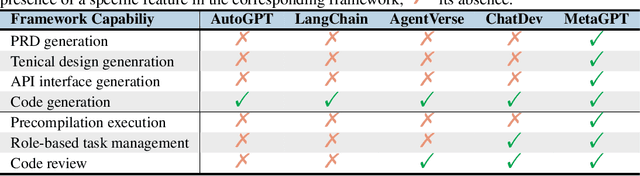
Recently, remarkable progress has been made in automated task-solving through the use of multi-agent driven by large language models (LLMs). However, existing LLM-based multi-agent works primarily focus on solving simple dialogue tasks, and complex tasks are rarely studied, mainly due to the LLM hallucination problem. This type of hallucination becomes cascading when naively chaining multiple intelligent agents, resulting in a failure to effectively address complex problems. Therefore, we introduce MetaGPT, an innovative framework that incorporates efficient human workflows as a meta programming approach into LLM-based multi-agent collaboration. Specifically, MetaGPT encodes Standardized Operating Procedures (SOPs) into prompts to enhance structured coordination. Subsequently, it mandates modular outputs, empowering agents with domain expertise comparable to human professionals, to validate outputs and minimize compounded errors. In this way, MetaGPT leverages the assembly line paradigm to assign diverse roles to various agents, thereby establishing a framework that can effectively and cohesively deconstruct complex multi-agent collaborative problems. Our experiments on collaborative software engineering benchmarks demonstrate that MetaGPT generates more coherent and correct solutions compared to existing chat-based multi-agent systems. This highlights the potential of integrating human domain knowledge into multi-agent systems, thereby creating new opportunities to tackle complex real-world challenges. The GitHub repository of this project is publicly available on:https://github.com/geekan/MetaGPT.