 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUPareto: Bridging the Forgetting-Utility Gap in Federated Unlearning via Pareto Augmented Optimization
Feb 02, 2026Federated Unlearning (FU) aims to efficiently remove the influence of specific client data from a federated model while preserving utility for the remaining clients. However, three key challenges remain: (1) existing unlearning objectives often compromise model utility or increase vulnerability to Membership Inference Attacks (MIA); (2) there is a persistent conflict between forgetting and utility, where further unlearning inevitably harms retained performance; and (3) support for concurrent multi-client unlearning is poor, as gradient conflicts among clients degrade the quality of forgetting. To address these issues, we propose FUPareto, an efficient unlearning framework via Pareto-augmented optimization. We first introduce the Minimum Boundary Shift (MBS) Loss, which enforces unlearning by suppressing the target class logit below the highest non-target class logit; this can improve the unlearning efficiency and mitigate MIA risks. During the unlearning process, FUPareto performs Pareto improvement steps to preserve model utility and executes Pareto expansion to guarantee forgetting. Specifically, during Pareto expansion, the framework integrates a Null-Space Projected Multiple Gradient Descent Algorithm (MGDA) to decouple gradient conflicts. This enables effective, fair, and concurrent unlearning for multiple clients while minimizing utility degradation. Extensive experiments across diverse scenarios demonstrate that FUPareto consistently outperforms state-of-the-art FU methods in both unlearning efficacy and retained utility.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
Multi-Objective Large Language Model Unlearning
Dec 29, 2024Machine unlearning in the domain of large language models (LLMs) has attracted great attention recently, which aims to effectively eliminate undesirable behaviors from LLMs without full retraining from scratch. In this paper, we explore the Gradient Ascent (GA) approach in LLM unlearning, which is a proactive way to decrease the prediction probability of the model on the target data in order to remove their influence. We analyze two challenges that render the process impractical: gradient explosion and catastrophic forgetting. To address these issues, we propose Multi-Objective Large Language Model Unlearning (MOLLM) algorithm. We first formulate LLM unlearning as a multi-objective optimization problem, in which the cross-entropy loss is modified to the unlearning version to overcome the gradient explosion issue. A common descent update direction is then calculated, which enables the model to forget the target data while preserving the utility of the LLM. Our empirical results verify that MoLLM outperforms the SOTA GA-based LLM unlearning methods in terms of unlearning effect and model utility preservation.
Federated Unlearning with Gradient Descent and Conflict Mitigation
Dec 28, 2024



Federated Learning (FL) has received much attention in recent years. However, although clients are not required to share their data in FL, the global model itself can implicitly remember clients' local data. Therefore, it's necessary to effectively remove the target client's data from the FL global model to ease the risk of privacy leakage and implement ``the right to be forgotten". Federated Unlearning (FU) has been considered a promising way to remove data without full retraining. But the model utility easily suffers significant reduction during unlearning due to the gradient conflicts. Furthermore, when conducting the post-training to recover the model utility, the model is prone to move back and revert what has already been unlearned. To address these issues, we propose Federated Unlearning with Orthogonal Steepest Descent (FedOSD). We first design an unlearning Cross-Entropy loss to overcome the convergence issue of the gradient ascent. A steepest descent direction for unlearning is then calculated in the condition of being non-conflicting with other clients' gradients and closest to the target client's gradient. This benefits to efficiently unlearn and mitigate the model utility reduction. After unlearning, we recover the model utility by maintaining the achievement of unlearning. Finally, extensive experiments in several FL scenarios verify that FedOSD outperforms the SOTA FU algorithms in terms of unlearning and model utility.
UMSNet: An Universal Multi-sensor Network for Human Activity Recognition
May 24, 2022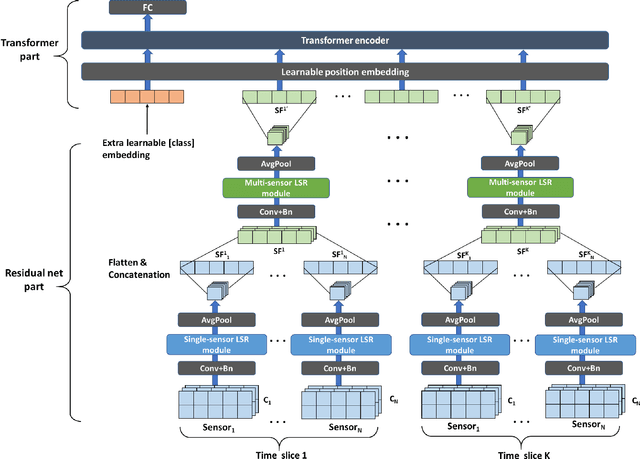



Human activity recognition (HAR) based on multimodal sensors has become a rapidly growing branch of biometric recognition and artificial intelligence. However, how to fully mine multimodal time series data and effectively learn accurate behavioral features has always been a hot topic in this field. Practical applications also require a well-generalized framework that can quickly process a variety of raw sensor data and learn better feature representations. This paper proposes a universal multi-sensor network (UMSNet) for human activity recognition. In particular, we propose a new lightweight sensor residual block (called LSR block), which improves the performance by reducing the number of activation function and normalization layers, and adding inverted bottleneck structure and grouping convolution. Then, the Transformer is used to extract the relationship of series features to realize the classification and recognition of human activities. Our framework has a clear structure and can be directly applied to various types of multi-modal Time Series Classification (TSC) tasks after simple specialization. Extensive experiments show that the proposed UMSNet outperforms other state-of-the-art methods on two popular multi-sensor human activity recognition datasets (i.e. HHAR dataset and MHEALTH dataset).
Self-Representation Based Unsupervised Exemplar Selection in a Union of Subspaces
Jun 07, 2020
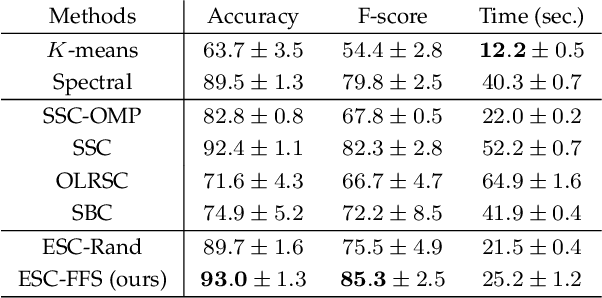
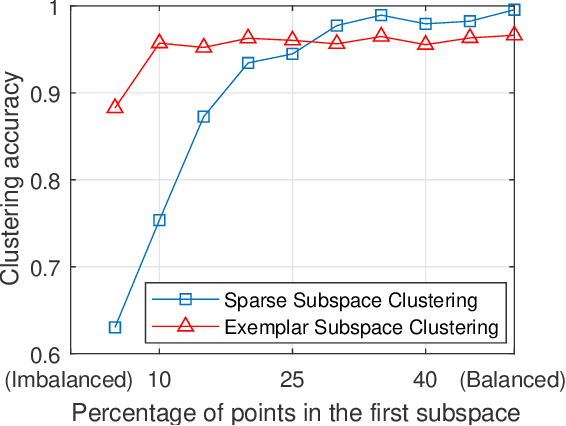
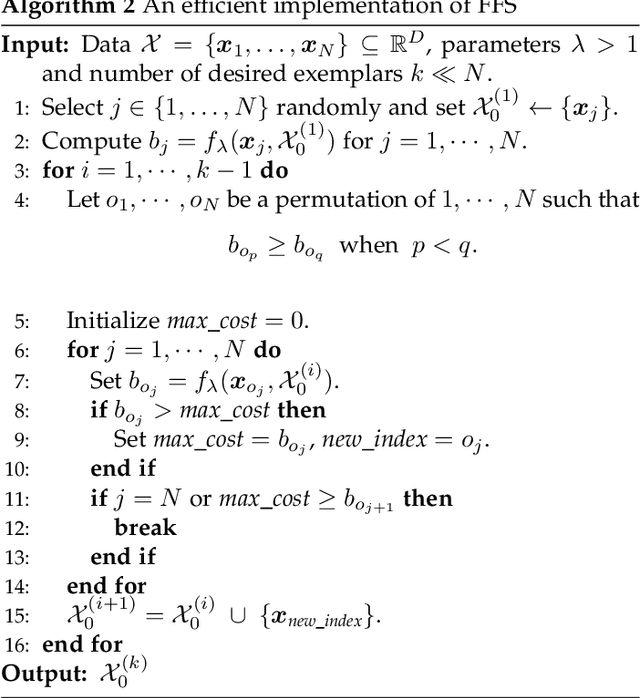
Finding a small set of representatives from an unlabeled dataset is a core problem in a broad range of applications such as dataset summarization and information extraction. Classical exemplar selection methods such as $k$-medoids work under the assumption that the data points are close to a few cluster centroids, and cannot handle the case where data lie close to a union of subspaces. This paper proposes a new exemplar selection model that searches for a subset that best reconstructs all data points as measured by the $\ell_1$ norm of the representation coefficients. Geometrically, this subset best covers all the data points as measured by the Minkowski functional of the subset. To solve our model efficiently, we introduce a farthest first search algorithm that iteratively selects the worst represented point as an exemplar. When the dataset is drawn from a union of independent subspaces, our method is able to select sufficiently many representatives from each subspace. We further develop an exemplar based subspace clustering method that is robust to imbalanced data and efficient for large scale data. Moreover, we show that a classifier trained on the selected exemplars (when they are labeled) can correctly classify the rest of the data points.
NM-Net: Mining Reliable Neighbors for Robust Feature Correspondences
Mar 31, 2019



Feature correspondence selection is pivotal to many feature-matching based tasks in computer vision. Searching for spatially k-nearest neighbors is a common strategy for extracting local information in many previous works. However, there is no guarantee that the spatially k-nearest neighbors of correspondences are consistent because the spatial distribution of false correspondences is often irregular. To address this issue, we present a compatibility-specific mining method to search for consistent neighbors. Moreover, in order to extract and aggregate more reliable features from neighbors, we propose a hierarchical network named NM-Net with a series of convolution layers taking the generated graph as input, which is insensitive to the order of correspondences. Our experimental results have shown the proposed method achieves the state-of-the-art performance on four datasets with various inlier ratios and varying numbers of feature consistencies.
A Unified Framework for Multi-View Multi-Class Object Pose Estimation
Oct 06, 2018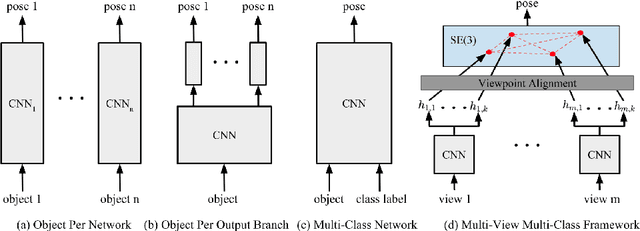
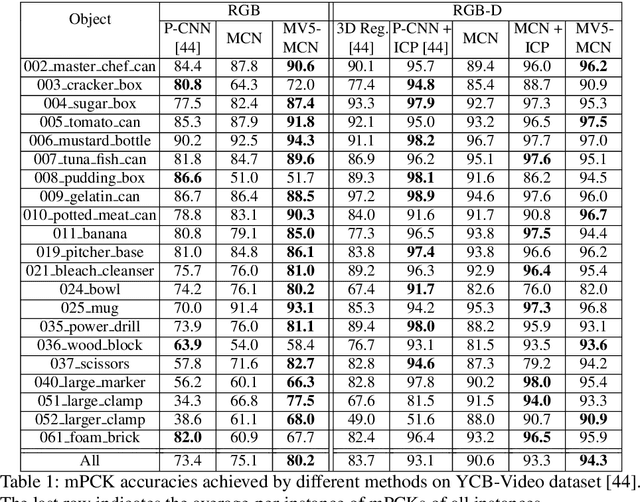
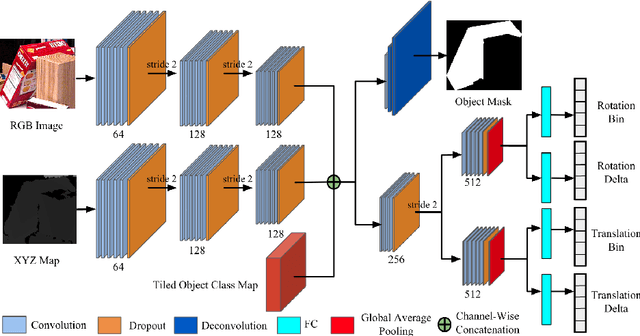
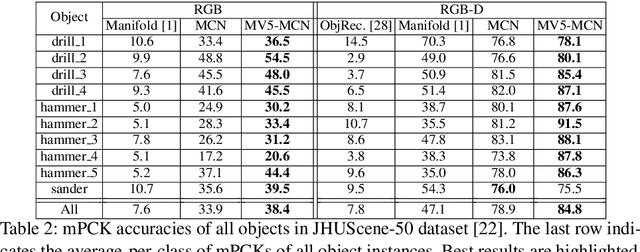
One core challenge in object pose estimation is to ensure accurate and robust performance for large numbers of diverse foreground objects amidst complex background clutter. In this work, we present a scalable framework for accurately inferring six Degree-of-Freedom (6-DoF) pose for a large number of object classes from single or multiple views. To learn discriminative pose features, we integrate three new capabilities into a deep Convolutional Neural Network (CNN): an inference scheme that combines both classification and pose regression based on a uniform tessellation of the Special Euclidean group in three dimensions (SE(3)), the fusion of class priors into the training process via a tiled class map, and an additional regularization using deep supervision with an object mask. Further, an efficient multi-view framework is formulated to address single-view ambiguity. We show that this framework consistently improves the performance of the single-view network. We evaluate our method on three large-scale benchmarks: YCB-Video, JHUScene-50 and ObjectNet-3D. Our approach achieves competitive or superior performance over the current state-of-the-art methods.
Deep Supervision with Intermediate Concepts
Jul 20, 2018



Recent data-driven approaches to scene interpretation predominantly pose inference as an end-to-end black-box mapping, commonly performed by a Convolutional Neural Network (CNN). However, decades of work on perceptual organization in both human and machine vision suggests that there are often intermediate representations that are intrinsic to an inference task, and which provide essential structure to improve generalization. In this work, we explore an approach for injecting prior domain structure into neural network training by supervising hidden layers of a CNN with intermediate concepts that normally are not observed in practice. We formulate a probabilistic framework which formalizes these notions and predicts improved generalization via this deep supervision method. One advantage of this approach is that we are able to train only from synthetic CAD renderings of cluttered scenes, where concept values can be extracted, but apply the results to real images. Our implementation achieves the state-of-the-art performance of 2D/3D keypoint localization and image classification on real image benchmarks, including KITTI, PASCAL VOC, PASCAL3D+, IKEA, and CIFAR100. We provide additional evidence that our approach outperforms alternative forms of supervision, such as multi-task networks.
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
Apr 20, 2017



Monocular 3D object parsing is highly desirable in various scenarios including occlusion reasoning and holistic scene interpretation. We present a deep convolutional neural network (CNN) architecture to localize semantic parts in 2D image and 3D space while inferring their visibility states, given a single RGB image. Our key insight is to exploit domain knowledge to regularize the network by deeply supervising its hidden layers, in order to sequentially infer intermediate concepts associated with the final task. To acquire training data in desired quantities with ground truth 3D shape and relevant concepts, we render 3D object CAD models to generate large-scale synthetic data and simulate challenging occlusion configurations between objects. We train the network only on synthetic data and demonstrate state-of-the-art performances on real image benchmarks including an extended version of KITTI, PASCAL VOC, PASCAL3D+ and IKEA for 2D and 3D keypoint localization and instance segmentation. The empirical results substantiate the utility of our deep supervision scheme by demonstrating effective transfer of knowledge from synthetic data to real images, resulting in less overfitting compared to standard end-to-end training.