 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Self-Supervised Video Alignment and Action Segmentation
Mar 21, 2025We introduce a novel approach for simultaneous self-supervised video alignment and action segmentation based on a unified optimal transport framework. In particular, we first tackle self-supervised video alignment by developing a fused Gromov-Wasserstein optimal transport formulation with a structural prior, which trains efficiently on GPUs and needs only a few iterations for solving the optimal transport problem. Our single-task method achieves the state-of-the-art performance on multiple video alignment benchmarks and outperforms VAVA, which relies on a traditional Kantorovich optimal transport formulation with an optimality prior. Furthermore, we extend our approach by proposing a unified optimal transport framework for joint self-supervised video alignment and action segmentation, which requires training and storing a single model and saves both time and memory consumption as compared to two different single-task models. Extensive evaluations on several video alignment and action segmentation datasets demonstrate that our multi-task method achieves comparable video alignment yet superior action segmentation results over previous methods in video alignment and action segmentation respectively. Finally, to the best of our knowledge, this is the first work to unify video alignment and action segmentation into a single model.
Video LLMs for Temporal Reasoning in Long Videos
Dec 04, 2024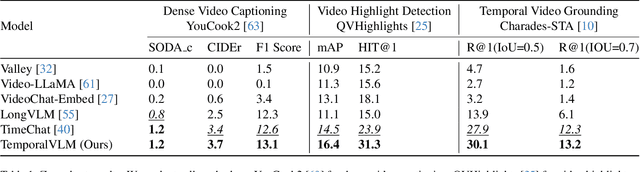
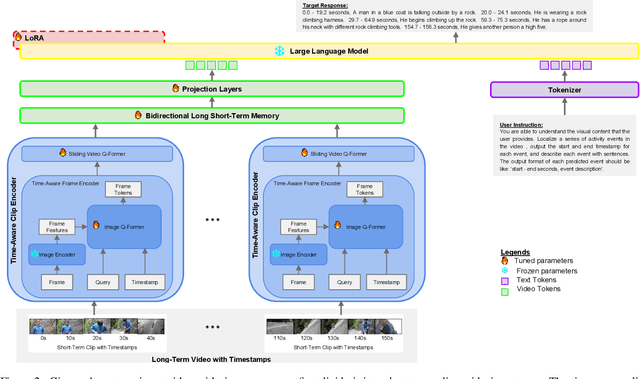


This paper introduces TemporalVLM, a video large language model capable of effective temporal reasoning and fine-grained understanding in long videos. At the core, our approach includes a visual encoder for mapping a long-term input video into features which are time-aware and contain both local and global cues. In particular, it first divides the input video into short-term clips, which are jointly encoded with their timestamps into time-sensitive local features. Next, the local features are passed through a bidirectional long short-term memory module for global feature aggregation. The extracted time-aware and multi-level features are important for accurate temporal reasoning and fine-grained understanding in long videos. Moreover, to facilitate the evaluation of TemporalVLM, we present a large-scale long video dataset of industry assembly processes, namely IndustryASM, which consists of videos recorded on factory floors with actions and timestamps annotated by industrial engineers for time and motion studies and temporal action segmentation evaluation. Finally, extensive experiments on datasets of long videos, including TimeIT and IndustryASM, show that TemporalVLM achieves superior performance than previous methods across temporal reasoning and fine-grained understanding tasks, namely dense video captioning, temporal video grounding, video highlight detection, and temporal action segmentation.
Action Segmentation Using 2D Skeleton Heatmaps
Sep 19, 2023



This paper presents a 2D skeleton-based action segmentation method with applications in fine-grained human activity recognition. In contrast with state-of-the-art methods which directly take sequences of 3D skeleton coordinates as inputs and apply Graph Convolutional Networks (GCNs) for spatiotemporal feature learning, our main idea is to use sequences of 2D skeleton heatmaps as inputs and employ Temporal Convolutional Networks (TCNs) to extract spatiotemporal features. Despite lacking 3D information, our approach yields comparable/superior performances and better robustness against missing keypoints than previous methods on action segmentation datasets. Moreover, we improve the performances further by using both 2D skeleton heatmaps and RGB videos as inputs. To our best knowledge, this is the first work to utilize 2D skeleton heatmap inputs and the first work to explore 2D skeleton+RGB fusion for action segmentation.
Permutation-Aware Action Segmentation via Unsupervised Frame-to-Segment Alignment
May 31, 2023This paper presents a novel transformer-based framework for unsupervised activity segmentation which leverages not only frame-level cues but also segment-level cues. This is in contrast with previous methods which often rely on frame-level information only. Our approach begins with a frame-level prediction module which estimates framewise action classes via a transformer encoder. The frame-level prediction module is trained in an unsupervised manner via temporal optimal transport. To exploit segment-level information, we introduce a segment-level prediction module and a frame-to-segment alignment module. The former includes a transformer decoder for estimating video transcripts, while the latter matches frame-level features with segment-level features, yielding permutation-aware segmentation results. Moreover, inspired by temporal optimal transport, we develop simple-yet-effective pseudo labels for unsupervised training of the above modules. Our experiments on four public datasets, i.e., 50 Salads, YouTube Instructions, Breakfast, and Desktop Assembly show that our approach achieves comparable or better performance than previous methods in unsupervised activity segmentation.
Learning by Aligning 2D Skeleton Sequences in Time
May 31, 2023



This paper presents a novel self-supervised temporal video alignment framework which is useful for several fine-grained human activity understanding applications. In contrast with the state-of-the-art method of CASA, where sequences of 3D skeleton coordinates are taken directly as input, our key idea is to use sequences of 2D skeleton heatmaps as input. Given 2D skeleton heatmaps, we utilize a video transformer which performs self-attention in the spatial and temporal domains for extracting effective spatiotemporal and contextual features. In addition, we introduce simple heatmap augmentation techniques based on 2D skeletons for self-supervised learning. Despite the lack of 3D information, our approach achieves not only higher accuracy but also better robustness against missing and noisy keypoints than CASA. Extensive evaluations on three public datasets, i.e., Penn Action, IKEA ASM, and H2O, demonstrate that our approach outperforms previous methods in different fine-grained human activity understanding tasks, i.e., phase classification, phase progression, video alignment, and fine-grained frame retrieval.
Inductive and Transductive Few-Shot Video Classification via Appearance and Temporal Alignments
Jul 21, 2022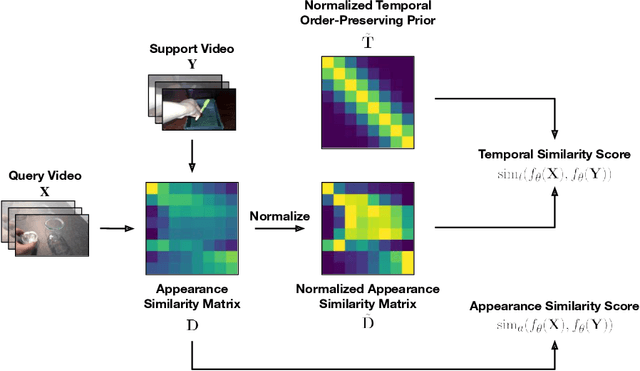



We present a novel method for few-shot video classification, which performs appearance and temporal alignments. In particular, given a pair of query and support videos, we conduct appearance alignment via frame-level feature matching to achieve the appearance similarity score between the videos, while utilizing temporal order-preserving priors for obtaining the temporal similarity score between the videos. Moreover, we introduce a few-shot video classification framework that leverages the above appearance and temporal similarity scores across multiple steps, namely prototype-based training and testing as well as inductive and transductive prototype refinement. To the best of our knowledge, our work is the first to explore transductive few-shot video classification. Extensive experiments on both Kinetics and Something-Something V2 datasets show that both appearance and temporal alignments are crucial for datasets with temporal order sensitivity such as Something-Something V2. Our approach achieves similar or better results than previous methods on both datasets. Our code is available at https://github.com/VinAIResearch/fsvc-ata.
Timestamp-Supervised Action Segmentation with Graph Convolutional Networks
Jun 30, 2022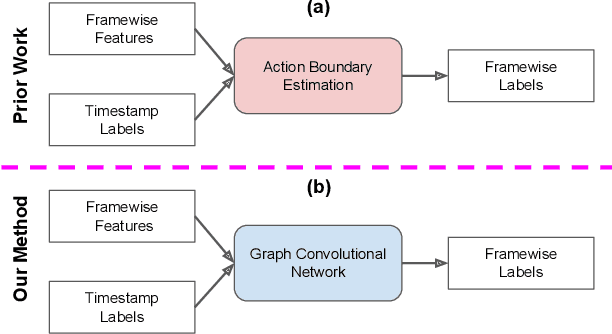
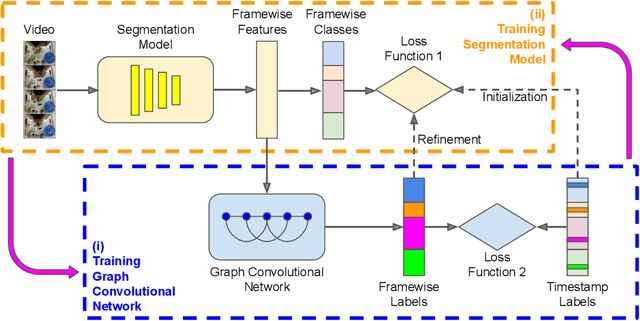

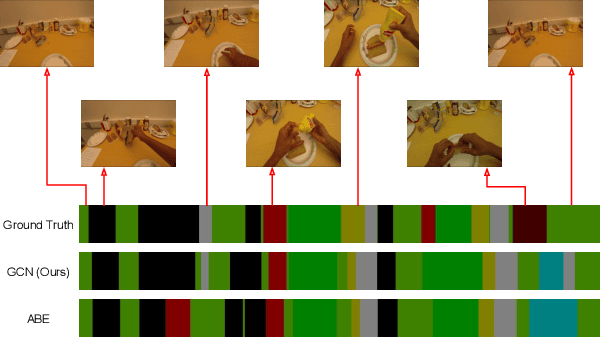
We introduce a novel approach for temporal activity segmentation with timestamp supervision. Our main contribution is a graph convolutional network, which is learned in an end-to-end manner to exploit both frame features and connections between neighboring frames to generate dense framewise labels from sparse timestamp labels. The generated dense framewise labels can then be used to train the segmentation model. In addition, we propose a framework for alternating learning of both the segmentation model and the graph convolutional model, which first initializes and then iteratively refines the learned models. Detailed experiments on four public datasets, including 50 Salads, GTEA, Breakfast, and Desktop Assembly, show that our method is superior to the multi-layer perceptron baseline, while performing on par with or better than the state of the art in temporal activity segmentation with timestamp supervision.
POODLE: Improving Few-shot Learning via Penalizing Out-of-Distribution Samples
Jun 08, 2022


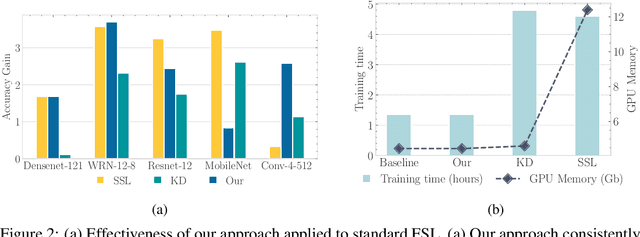
In this work, we propose to use out-of-distribution samples, i.e., unlabeled samples coming from outside the target classes, to improve few-shot learning. Specifically, we exploit the easily available out-of-distribution samples to drive the classifier to avoid irrelevant features by maximizing the distance from prototypes to out-of-distribution samples while minimizing that of in-distribution samples (i.e., support, query data). Our approach is simple to implement, agnostic to feature extractors, lightweight without any additional cost for pre-training, and applicable to both inductive and transductive settings. Extensive experiments on various standard benchmarks demonstrate that the proposed method consistently improves the performance of pretrained networks with different architectures.
Unsupervised Activity Segmentation by Joint Representation Learning and Online Clustering
May 28, 2021
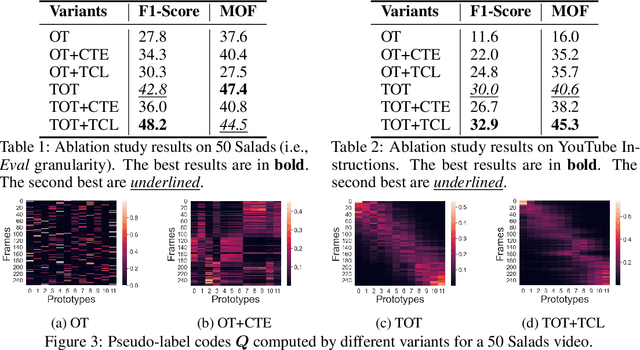
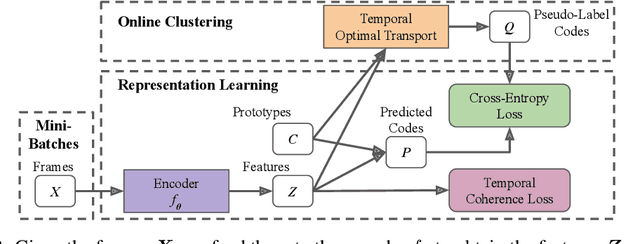
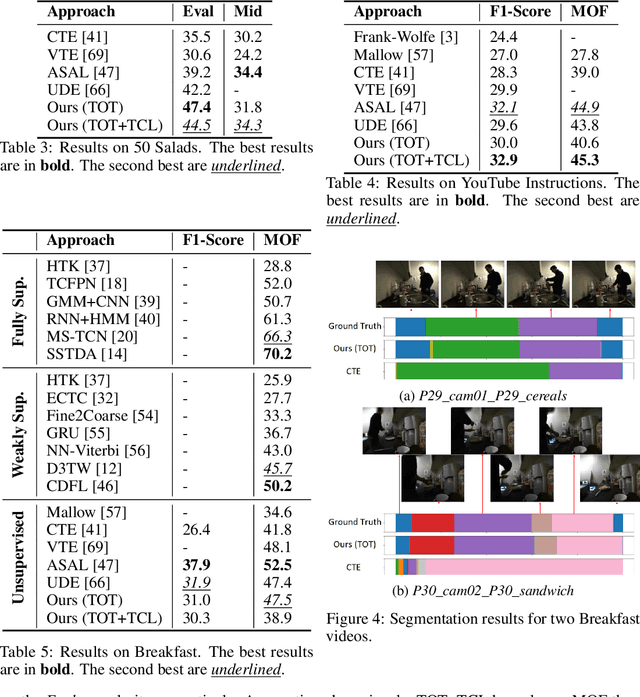
We present a novel approach for unsupervised activity segmentation, which uses video frame clustering as a pretext task and simultaneously performs representation learning and online clustering. This is in contrast with prior works where representation learning and clustering are often performed sequentially. We leverage temporal information in videos by employing temporal optimal transport and temporal coherence loss. In particular, we incorporate a temporal regularization term into the standard optimal transport module, which preserves the temporal order of the activity, yielding the temporal optimal transport module for computing pseudo-label cluster assignments. Next, the temporal coherence loss encourages neighboring video frames to be mapped to nearby points while distant video frames are mapped to farther away points in the embedding space. The combination of these two components results in effective representations for unsupervised activity segmentation. Furthermore, previous methods require storing learned features for the entire dataset before clustering them in an offline manner, whereas our approach processes one mini-batch at a time in an online manner. Extensive evaluations on three public datasets, i.e. 50-Salads, YouTube Instructions, and Breakfast, and our dataset, i.e., Desktop Assembly, show that our approach performs on par or better than previous methods for unsupervised activity segmentation, despite having significantly less memory constraints.
Learning by Aligning Videos in Time
Mar 31, 2021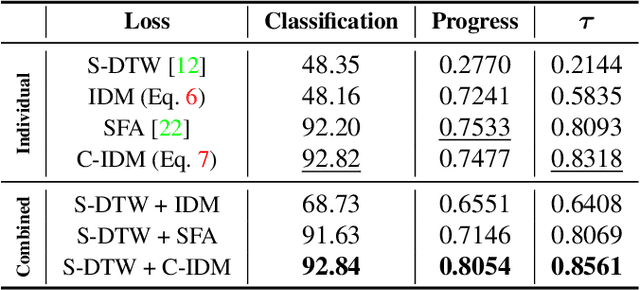
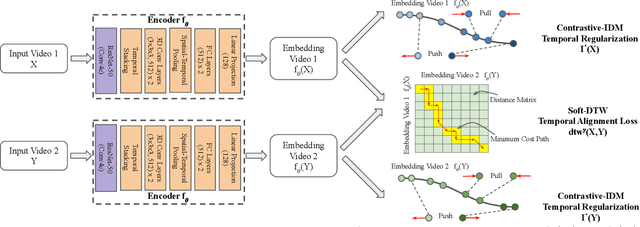
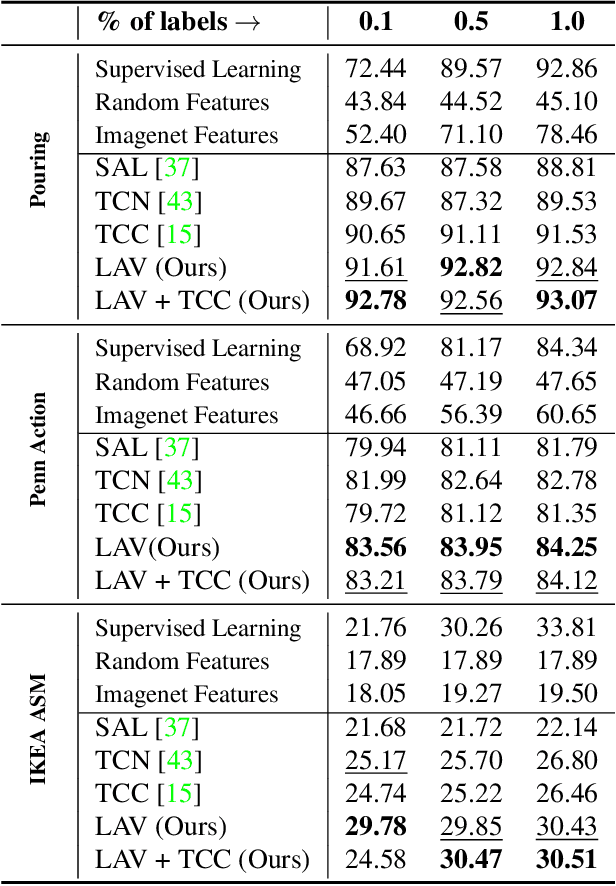
We present a self-supervised approach for learning video representations using temporal video alignment as a pretext task, while exploiting both frame-level and video-level information. We leverage a novel combination of temporal alignment loss and temporal regularization terms, which can be used as supervision signals for training an encoder network. Specifically, the temporal alignment loss (i.e., Soft-DTW) aims for the minimum cost for temporally aligning videos in the embedding space. However, optimizing solely for this term leads to trivial solutions, particularly, one where all frames get mapped to a small cluster in the embedding space. To overcome this problem, we propose a temporal regularization term (i.e., Contrastive-IDM) which encourages different frames to be mapped to different points in the embedding space. Extensive evaluations on various tasks, including action phase classification, action phase progression, and fine-grained frame retrieval, on three datasets, namely Pouring, Penn Action, and IKEA ASM, show superior performance of our approach over state-of-the-art methods for self-supervised representation learning from videos. In addition, our method provides significant performance gain where labeled data is lacking.