 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEssential-Web v1.0: 24T tokens of organized web data
Jun 17, 2025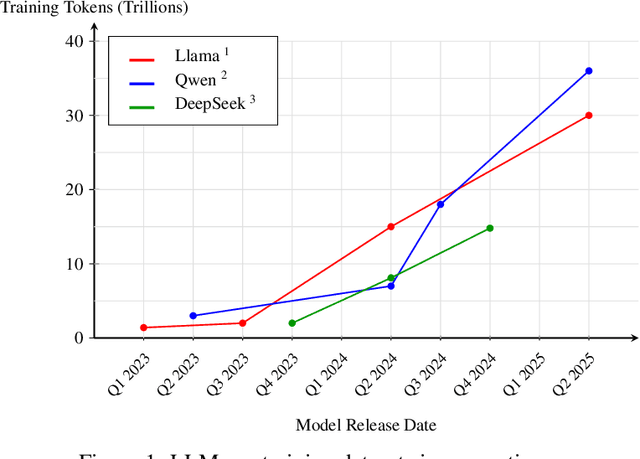
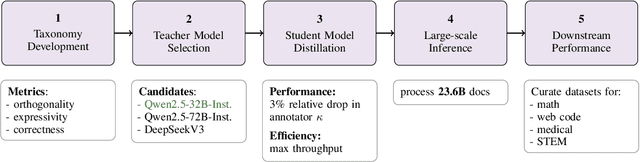

Data plays the most prominent role in how language models acquire skills and knowledge. The lack of massive, well-organized pre-training datasets results in costly and inaccessible data pipelines. We present Essential-Web v1.0, a 24-trillion-token dataset in which every document is annotated with a twelve-category taxonomy covering topic, format, content complexity, and quality. Taxonomy labels are produced by EAI-Distill-0.5b, a fine-tuned 0.5b-parameter model that achieves an annotator agreement within 3% of Qwen2.5-32B-Instruct. With nothing more than SQL-style filters, we obtain competitive web-curated datasets in math (-8.0% relative to SOTA), web code (+14.3%), STEM (+24.5%) and medical (+8.6%). Essential-Web v1.0 is available on HuggingFace: https://huggingface.co/datasets/EssentialAI/essential-web-v1.0
Practical Efficiency of Muon for Pretraining
May 04, 2025We demonstrate that Muon, the simplest instantiation of a second-order optimizer, explicitly expands the Pareto frontier over AdamW on the compute-time tradeoff. We find that Muon is more effective than AdamW in retaining data efficiency at large batch sizes, far beyond the so-called critical batch size, while remaining computationally efficient, thus enabling more economical training. We study the combination of Muon and the maximal update parameterization (muP) for efficient hyperparameter transfer and present a simple telescoping algorithm that accounts for all sources of error in muP while introducing only a modest overhead in resources. We validate our findings through extensive experiments with model sizes up to four billion parameters and ablations on the data distribution and architecture.
Rethinking Reflection in Pre-Training
Apr 05, 2025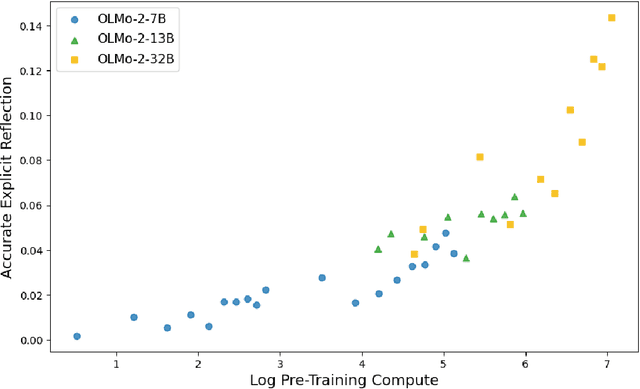
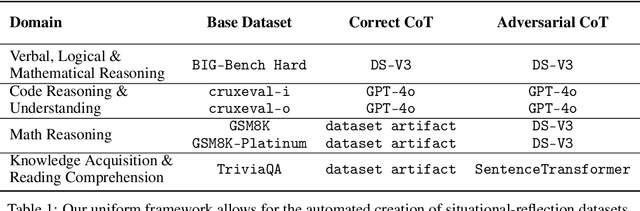
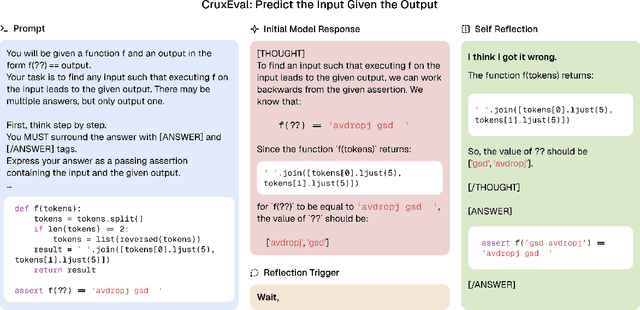
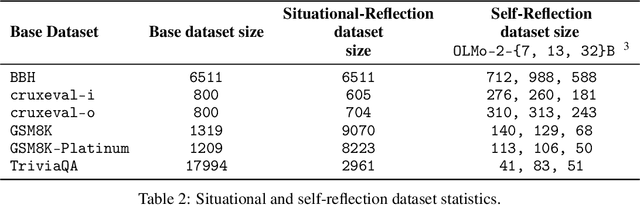
A language model's ability to reflect on its own reasoning provides a key advantage for solving complex problems. While most recent research has focused on how this ability develops during reinforcement learning, we show that it actually begins to emerge much earlier - during the model's pre-training. To study this, we introduce deliberate errors into chains-of-thought and test whether the model can still arrive at the correct answer by recognizing and correcting these mistakes. By tracking performance across different stages of pre-training, we observe that this self-correcting ability appears early and improves steadily over time. For instance, an OLMo2-7B model pre-trained on 4 trillion tokens displays self-correction on our six self-reflection tasks.
SwiftTry: Fast and Consistent Video Virtual Try-On with Diffusion Models
Dec 13, 2024



Given an input video of a person and a new garment, the objective of this paper is to synthesize a new video where the person is wearing the specified garment while maintaining spatiotemporal consistency. While significant advances have been made in image-based virtual try-ons, extending these successes to video often results in frame-to-frame inconsistencies. Some approaches have attempted to address this by increasing the overlap of frames across multiple video chunks, but this comes at a steep computational cost due to the repeated processing of the same frames, especially for long video sequence. To address these challenges, we reconceptualize video virtual try-on as a conditional video inpainting task, with garments serving as input conditions. Specifically, our approach enhances image diffusion models by incorporating temporal attention layers to improve temporal coherence. To reduce computational overhead, we introduce ShiftCaching, a novel technique that maintains temporal consistency while minimizing redundant computations. Furthermore, we introduce the \dataname~dataset, a new video try-on dataset featuring more complex backgrounds, challenging movements, and higher resolution compared to existing public datasets. Extensive experiments show that our approach outperforms current baselines, particularly in terms of video consistency and inference speed. Data and code are available at https://github.com/VinAIResearch/swift-try
SwiftEdit: Lightning Fast Text-Guided Image Editing via One-Step Diffusion
Dec 05, 2024Recent advances in text-guided image editing enable users to perform image edits through simple text inputs, leveraging the extensive priors of multi-step diffusion-based text-to-image models. However, these methods often fall short of the speed demands required for real-world and on-device applications due to the costly multi-step inversion and sampling process involved. In response to this, we introduce SwiftEdit, a simple yet highly efficient editing tool that achieve instant text-guided image editing (in 0.23s). The advancement of SwiftEdit lies in its two novel contributions: a one-step inversion framework that enables one-step image reconstruction via inversion and a mask-guided editing technique with our proposed attention rescaling mechanism to perform localized image editing. Extensive experiments are provided to demonstrate the effectiveness and efficiency of SwiftEdit. In particular, SwiftEdit enables instant text-guided image editing, which is extremely faster than previous multi-step methods (at least 50 times faster) while maintain a competitive performance in editing results. Our project page is at: https://swift-edit.github.io/
EditScout: Locating Forged Regions from Diffusion-based Edited Images with Multimodal LLM
Dec 05, 2024



Image editing technologies are tools used to transform, adjust, remove, or otherwise alter images. Recent research has significantly improved the capabilities of image editing tools, enabling the creation of photorealistic and semantically informed forged regions that are nearly indistinguishable from authentic imagery, presenting new challenges in digital forensics and media credibility. While current image forensic techniques are adept at localizing forged regions produced by traditional image manipulation methods, current capabilities struggle to localize regions created by diffusion-based techniques. To bridge this gap, we present a novel framework that integrates a multimodal Large Language Model (LLM) for enhanced reasoning capabilities to localize tampered regions in images produced by diffusion model-based editing methods. By leveraging the contextual and semantic strengths of LLMs, our framework achieves promising results on MagicBrush, AutoSplice, and PerfBrush (novel diffusion-based dataset) datasets, outperforming previous approaches in mIoU and F1-score metrics. Notably, our method excels on the PerfBrush dataset, a self-constructed test set featuring previously unseen types of edits. Here, where traditional methods typically falter, achieving markedly low scores, our approach demonstrates promising performance.
SNOOPI: Supercharged One-step Diffusion Distillation with Proper Guidance
Dec 03, 2024



Recent approaches have yielded promising results in distilling multi-step text-to-image diffusion models into one-step ones. The state-of-the-art efficient distillation technique, i.e., SwiftBrushv2 (SBv2), even surpasses the teacher model's performance with limited resources. However, our study reveals its instability when handling different diffusion model backbones due to using a fixed guidance scale within the Variational Score Distillation (VSD) loss. Another weakness of the existing one-step diffusion models is the missing support for negative prompt guidance, which is crucial in practical image generation. This paper presents SNOOPI, a novel framework designed to address these limitations by enhancing the guidance in one-step diffusion models during both training and inference. First, we effectively enhance training stability through Proper Guidance-SwiftBrush (PG-SB), which employs a random-scale classifier-free guidance approach. By varying the guidance scale of both teacher models, we broaden their output distributions, resulting in a more robust VSD loss that enables SB to perform effectively across diverse backbones while maintaining competitive performance. Second, we propose a training-free method called Negative-Away Steer Attention (NASA), which integrates negative prompts into one-step diffusion models via cross-attention to suppress undesired elements in generated images. Our experimental results show that our proposed methods significantly improve baseline models across various metrics. Remarkably, we achieve an HPSv2 score of 31.08, setting a new state-of-the-art benchmark for one-step diffusion models.
ModeDreamer: Mode Guiding Score Distillation for Text-to-3D Generation using Reference Image Prompts
Nov 27, 2024



Existing Score Distillation Sampling (SDS)-based methods have driven significant progress in text-to-3D generation. However, 3D models produced by SDS-based methods tend to exhibit over-smoothing and low-quality outputs. These issues arise from the mode-seeking behavior of current methods, where the scores used to update the model oscillate between multiple modes, resulting in unstable optimization and diminished output quality. To address this problem, we introduce a novel image prompt score distillation loss named ISD, which employs a reference image to direct text-to-3D optimization toward a specific mode. Our ISD loss can be implemented by using IP-Adapter, a lightweight adapter for integrating image prompt capability to a text-to-image diffusion model, as a mode-selection module. A variant of this adapter, when not being prompted by a reference image, can serve as an efficient control variate to reduce variance in score estimates, thereby enhancing both output quality and optimization stability. Our experiments demonstrate that the ISD loss consistently achieves visually coherent, high-quality outputs and improves optimization speed compared to prior text-to-3D methods, as demonstrated through both qualitative and quantitative evaluations on the T3Bench benchmark suite.
SharpDepth: Sharpening Metric Depth Predictions Using Diffusion Distillation
Nov 27, 2024

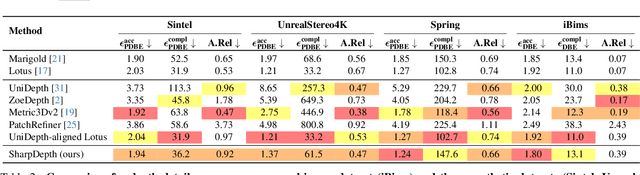

We propose SharpDepth, a novel approach to monocular metric depth estimation that combines the metric accuracy of discriminative depth estimation methods (e.g., Metric3D, UniDepth) with the fine-grained boundary sharpness typically achieved by generative methods (e.g., Marigold, Lotus). Traditional discriminative models trained on real-world data with sparse ground-truth depth can accurately predict metric depth but often produce over-smoothed or low-detail depth maps. Generative models, in contrast, are trained on synthetic data with dense ground truth, generating depth maps with sharp boundaries yet only providing relative depth with low accuracy. Our approach bridges these limitations by integrating metric accuracy with detailed boundary preservation, resulting in depth predictions that are both metrically precise and visually sharp. Our extensive zero-shot evaluations on standard depth estimation benchmarks confirm SharpDepth effectiveness, showing its ability to achieve both high depth accuracy and detailed representation, making it well-suited for applications requiring high-quality depth perception across diverse, real-world environments.
Any3DIS: Class-Agnostic 3D Instance Segmentation by 2D Mask Tracking
Nov 25, 2024Existing 3D instance segmentation methods frequently encounter issues with over-segmentation, leading to redundant and inaccurate 3D proposals that complicate downstream tasks. This challenge arises from their unsupervised merging approach, where dense 2D instance masks are lifted across frames into point clouds to form 3D candidate proposals without direct supervision. These candidates are then hierarchically merged based on heuristic criteria, often resulting in numerous redundant segments that fail to combine into precise 3D proposals. To overcome these limitations, we propose a 3D-Aware 2D Mask Tracking module that uses robust 3D priors from a 2D mask segmentation and tracking foundation model (SAM-2) to ensure consistent object masks across video frames. Rather than merging all visible superpoints across views to create a 3D mask, our 3D Mask Optimization module leverages a dynamic programming algorithm to select an optimal set of views, refining the superpoints to produce a final 3D proposal for each object. Our approach achieves comprehensive object coverage within the scene while reducing unnecessary proposals, which could otherwise impair downstream applications. Evaluations on ScanNet200 and ScanNet++ confirm the effectiveness of our method, with improvements across Class-Agnostic, Open-Vocabulary, and Open-Ended 3D Instance Segmentation tasks.