 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Statistical Theory of Gated Attention through the Lens of Hierarchical Mixture of Experts
Feb 01, 2026Self-attention has greatly contributed to the success of the widely used Transformer architecture by enabling learning from data with long-range dependencies. In an effort to improve performance, a gated attention model that leverages a gating mechanism within the multi-head self-attention has recently been proposed as a promising alternative. Gated attention has been empirically demonstrated to increase the expressiveness of low-rank mapping in standard attention and even to eliminate the attention sink phenomenon. Despite its efficacy, a clear theoretical understanding of gated attention's benefits remains lacking in the literature. To close this gap, we rigorously show that each entry in a gated attention matrix or a multi-head self-attention matrix can be written as a hierarchical mixture of experts. By recasting learning as an expert estimation problem, we demonstrate that gated attention is more sample-efficient than multi-head self-attention. In particular, while the former needs only a polynomial number of data points to estimate an expert, the latter requires exponentially many data points to achieve the same estimation error. Furthermore, our analysis also provides a theoretical justification for why gated attention yields higher performance when a gate is placed at the output of the scaled dot product attention or the value map rather than at other positions in the multi-head self-attention architecture.
Rethinking Multinomial Logistic Mixture of Experts with Sigmoid Gating Function
Feb 01, 2026The sigmoid gate in mixture-of-experts (MoE) models has been empirically shown to outperform the softmax gate across several tasks, ranging from approximating feed-forward networks to language modeling. Additionally, recent efforts have demonstrated that the sigmoid gate is provably more sample-efficient than its softmax counterpart under regression settings. Nevertheless, there are three notable concerns that have not been addressed in the literature, namely (i) the benefits of the sigmoid gate have not been established under classification settings; (ii) existing sigmoid-gated MoE models may not converge to their ground-truth; and (iii) the effects of a temperature parameter in the sigmoid gate remain theoretically underexplored. To tackle these open problems, we perform a comprehensive analysis of multinomial logistic MoE equipped with a modified sigmoid gate to ensure model convergence. Our results indicate that the sigmoid gate exhibits a lower sample complexity than the softmax gate for both parameter and expert estimation. Furthermore, we find that incorporating a temperature into the sigmoid gate leads to a sample complexity of exponential order due to an intrinsic interaction between the temperature and gating parameters. To overcome this issue, we propose replacing the vanilla inner product score in the gating function with a Euclidean score that effectively removes that interaction, thereby substantially improving the sample complexity to a polynomial order.
CGCE: Classifier-Guided Concept Erasure in Generative Models
Nov 08, 2025Recent advancements in large-scale generative models have enabled the creation of high-quality images and videos, but have also raised significant safety concerns regarding the generation of unsafe content. To mitigate this, concept erasure methods have been developed to remove undesirable concepts from pre-trained models. However, existing methods remain vulnerable to adversarial attacks that can regenerate the erased content. Moreover, achieving robust erasure often degrades the model's generative quality for safe, unrelated concepts, creating a difficult trade-off between safety and performance. To address this challenge, we introduce Classifier-Guided Concept Erasure (CGCE), an efficient plug-and-play framework that provides robust concept erasure for diverse generative models without altering their original weights. CGCE uses a lightweight classifier operating on text embeddings to first detect and then refine prompts containing undesired concepts. This approach is highly scalable, allowing for multi-concept erasure by aggregating guidance from several classifiers. By modifying only unsafe embeddings at inference time, our method prevents harmful content generation while preserving the model's original quality on benign prompts. Extensive experiments show that CGCE achieves state-of-the-art robustness against a wide range of red-teaming attacks. Our approach also maintains high generative utility, demonstrating a superior balance between safety and performance. We showcase the versatility of CGCE through its successful application to various modern T2I and T2V models, establishing it as a practical and effective solution for safe generative AI.
Diverse Prototypical Ensembles Improve Robustness to Subpopulation Shift
May 29, 2025The subpopulationtion shift, characterized by a disparity in subpopulation distributibetween theween the training and target datasets, can significantly degrade the performance of machine learning models. Current solutions to subpopulation shift involve modifying empirical risk minimization with re-weighting strategies to improve generalization. This strategy relies on assumptions about the number and nature of subpopulations and annotations on group membership, which are unavailable for many real-world datasets. Instead, we propose using an ensemble of diverse classifiers to adaptively capture risk associated with subpopulations. Given a feature extractor network, we replace its standard linear classification layer with a mixture of prototypical classifiers, where each member is trained to classify the data while focusing on different features and samples from other members. In empirical evaluation on nine real-world datasets, covering diverse domains and kinds of subpopulation shift, our method of Diverse Prototypical Ensembles (DPEs) often outperforms the prior state-of-the-art in worst-group accuracy. The code is available at https://github.com/minhto2802/dpe4subpop
SNOOPI: Supercharged One-step Diffusion Distillation with Proper Guidance
Dec 03, 2024



Recent approaches have yielded promising results in distilling multi-step text-to-image diffusion models into one-step ones. The state-of-the-art efficient distillation technique, i.e., SwiftBrushv2 (SBv2), even surpasses the teacher model's performance with limited resources. However, our study reveals its instability when handling different diffusion model backbones due to using a fixed guidance scale within the Variational Score Distillation (VSD) loss. Another weakness of the existing one-step diffusion models is the missing support for negative prompt guidance, which is crucial in practical image generation. This paper presents SNOOPI, a novel framework designed to address these limitations by enhancing the guidance in one-step diffusion models during both training and inference. First, we effectively enhance training stability through Proper Guidance-SwiftBrush (PG-SB), which employs a random-scale classifier-free guidance approach. By varying the guidance scale of both teacher models, we broaden their output distributions, resulting in a more robust VSD loss that enables SB to perform effectively across diverse backbones while maintaining competitive performance. Second, we propose a training-free method called Negative-Away Steer Attention (NASA), which integrates negative prompts into one-step diffusion models via cross-attention to suppress undesired elements in generated images. Our experimental results show that our proposed methods significantly improve baseline models across various metrics. Remarkably, we achieve an HPSv2 score of 31.08, setting a new state-of-the-art benchmark for one-step diffusion models.
Dual-Model Defense: Safeguarding Diffusion Models from Membership Inference Attacks through Disjoint Data Splitting
Oct 22, 2024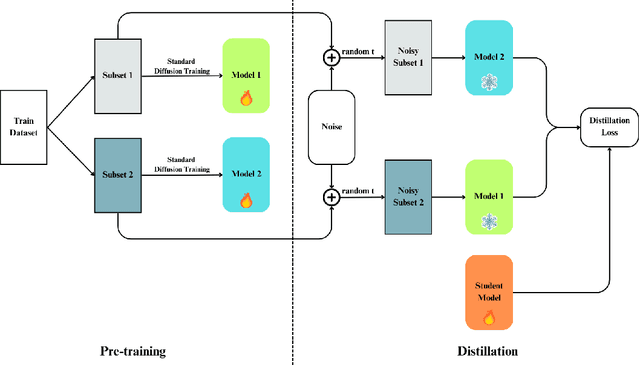



Diffusion models have demonstrated remarkable capabilities in image synthesis, but their recently proven vulnerability to Membership Inference Attacks (MIAs) poses a critical privacy concern. This paper introduces two novel and efficient approaches (DualMD and DistillMD) to protect diffusion models against MIAs while maintaining high utility. Both methods are based on training two separate diffusion models on disjoint subsets of the original dataset. DualMD then employs a private inference pipeline that utilizes both models. This strategy significantly reduces the risk of black-box MIAs by limiting the information any single model contains about individual training samples. The dual models can also generate "soft targets" to train a private student model in DistillMD, enhancing privacy guarantees against all types of MIAs. Extensive evaluations of DualMD and DistillMD against state-of-the-art MIAs across various datasets in white-box and black-box settings demonstrate their effectiveness in substantially reducing MIA success rates while preserving competitive image generation performance. Notably, our experiments reveal that DistillMD not only defends against MIAs but also mitigates model memorization, indicating that both vulnerabilities stem from overfitting and can be addressed simultaneously with our unified approach.
Sequential Decision Making with Expert Demonstrations under Unobserved Heterogeneity
Apr 10, 2024We study the problem of online sequential decision-making given auxiliary demonstrations from experts who made their decisions based on unobserved contextual information. These demonstrations can be viewed as solving related but slightly different tasks than what the learner faces. This setting arises in many application domains, such as self-driving cars, healthcare, and finance, where expert demonstrations are made using contextual information, which is not recorded in the data available to the learning agent. We model the problem as a zero-shot meta-reinforcement learning setting with an unknown task distribution and a Bayesian regret minimization objective, where the unobserved tasks are encoded as parameters with an unknown prior. We propose the Experts-as-Priors algorithm (ExPerior), a non-parametric empirical Bayes approach that utilizes the principle of maximum entropy to establish an informative prior over the learner's decision-making problem. This prior enables the application of any Bayesian approach for online decision-making, such as posterior sampling. We demonstrate that our strategy surpasses existing behaviour cloning and online algorithms for multi-armed bandits and reinforcement learning, showcasing the utility of our approach in leveraging expert demonstrations across different decision-making setups.
On Inference Stability for Diffusion Models
Dec 19, 2023Denoising Probabilistic Models (DPMs) represent an emerging domain of generative models that excel in generating diverse and high-quality images. However, most current training methods for DPMs often neglect the correlation between timesteps, limiting the model's performance in generating images effectively. Notably, we theoretically point out that this issue can be caused by the cumulative estimation gap between the predicted and the actual trajectory. To minimize that gap, we propose a novel \textit{sequence-aware} loss that aims to reduce the estimation gap to enhance the sampling quality. Furthermore, we theoretically show that our proposed loss function is a tighter upper bound of the estimation loss in comparison with the conventional loss in DPMs. Experimental results on several benchmark datasets including CIFAR10, CelebA, and CelebA-HQ consistently show a remarkable improvement of our proposed method regarding the image generalization quality measured by FID and Inception Score compared to several DPM baselines. Our code and pre-trained checkpoints are available at \url{https://github.com/viettmab/SA-DPM}.
Individual Tree Detection in Large-Scale Urban Environments using High-Resolution Multispectral Imagery
Aug 24, 2022


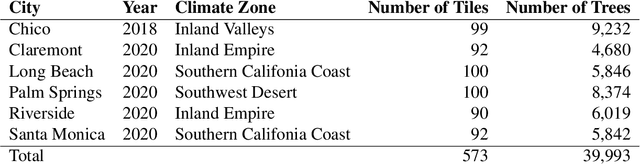
We introduce a novel deep learning method for detection of individual trees in urban environments using high-resolution multispectral aerial imagery. We use a convolutional neural network to regress a confidence map indicating the locations of individual trees, which are localized using a peak finding algorithm. Our method provides complete spatial coverage by detecting trees in both public and private spaces, and can scale to very large areas. In our study area spanning five cities in Southern California, we achieved an F-score of 0.735 and an RMSE of 2.157 m. We used our method to produce a map of all trees in the urban forest of California, indicating the potential for our method to support future urban forestry studies at unprecedented scales.
Human Imperceptible Attacks and Applications to Improve Fairness
Nov 30, 2021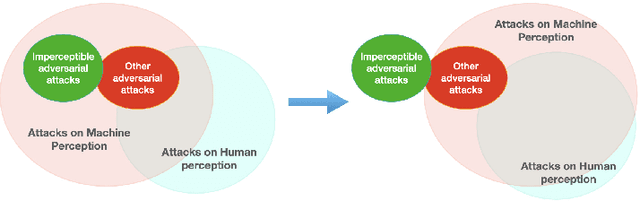


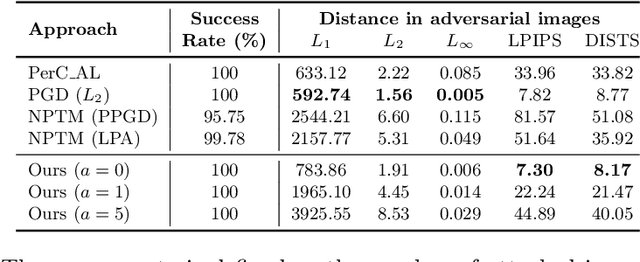
Modern neural networks are able to perform at least as well as humans in numerous tasks involving object classification and image generation. However, small perturbations which are imperceptible to humans may significantly degrade the performance of well-trained deep neural networks. We provide a Distributionally Robust Optimization (DRO) framework which integrates human-based image quality assessment methods to design optimal attacks that are imperceptible to humans but significantly damaging to deep neural networks. Through extensive experiments, we show that our attack algorithm generates better-quality (less perceptible to humans) attacks than other state-of-the-art human imperceptible attack methods. Moreover, we demonstrate that DRO training using our optimally designed human imperceptible attacks can improve group fairness in image classification. Towards the end, we provide an algorithmic implementation to speed up DRO training significantly, which could be of independent interest.