 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Privacy Risk via Forget Set-Free Unlearning
Apr 12, 2026Training machine learning models requires the storage of large datasets, which often contain sensitive or private data. Storing data is associated with a number of potential risks which increase over time, such as database breaches and malicious adversaries. Machine unlearning is the study of methods to efficiently remove the influence of training data subsets from previously-trained models. Existing unlearning methods typically require direct access to the "forget set" -- the data to be forgotten-and organisations must retain this data for unlearning rather than deleting it immediately upon request, increasing risks associated with the forget set. We introduce partially-blind unlearning -- utilizing auxiliary information to unlearn without explicit access to the forget set. We also propose a practical framework Reload, a partially-blind method based on gradient optimization and structured weight sparsification to operationalize partially-blind unlearning. We show that Reload efficiently unlearns, approximating models retrained from scratch, and outperforms several forget set-dependent approaches. On language models, Reload unlearns entities using <0.025% of the retain set and <7% of model weights in <8 minutes on Llama2-7B. In the corrective case, Reload achieves unlearning even when only 10% of corrupted data is identified.
* 50 pages, 20 figures, Published at The Fourteenth International Conference on Learning Representations
The Curious Language Model: Strategic Test-Time Information Acquisition
Jun 10, 2025



Decision-makers often possess insufficient information to render a confident decision. In these cases, the decision-maker can often undertake actions to acquire the necessary information about the problem at hand, e.g., by consulting knowledgeable authorities or by conducting experiments. Importantly, different levers of information acquisition come with different costs, posing the challenge of selecting the actions that are both informative and cost-effective. In this work, we propose CuriosiTree, a heuristic-based, test-time policy for zero-shot information acquisition in large language models (LLMs). CuriosiTree employs a greedy tree search to estimate the expected information gain of each action and strategically chooses actions based on a balance of anticipated information gain and associated cost. Empirical validation in a clinical diagnosis simulation shows that CuriosiTree enables cost-effective integration of heterogenous sources of information, and outperforms baseline action selection strategies in selecting action sequences that enable accurate diagnosis.
Diverse Prototypical Ensembles Improve Robustness to Subpopulation Shift
May 29, 2025The subpopulationtion shift, characterized by a disparity in subpopulation distributibetween theween the training and target datasets, can significantly degrade the performance of machine learning models. Current solutions to subpopulation shift involve modifying empirical risk minimization with re-weighting strategies to improve generalization. This strategy relies on assumptions about the number and nature of subpopulations and annotations on group membership, which are unavailable for many real-world datasets. Instead, we propose using an ensemble of diverse classifiers to adaptively capture risk associated with subpopulations. Given a feature extractor network, we replace its standard linear classification layer with a mixture of prototypical classifiers, where each member is trained to classify the data while focusing on different features and samples from other members. In empirical evaluation on nine real-world datasets, covering diverse domains and kinds of subpopulation shift, our method of Diverse Prototypical Ensembles (DPEs) often outperforms the prior state-of-the-art in worst-group accuracy. The code is available at https://github.com/minhto2802/dpe4subpop
Red Teaming Large Language Models for Healthcare
May 01, 2025We present the design process and findings of the pre-conference workshop at the Machine Learning for Healthcare Conference (2024) entitled Red Teaming Large Language Models for Healthcare, which took place on August 15, 2024. Conference participants, comprising a mix of computational and clinical expertise, attempted to discover vulnerabilities -- realistic clinical prompts for which a large language model (LLM) outputs a response that could cause clinical harm. Red-teaming with clinicians enables the identification of LLM vulnerabilities that may not be recognised by LLM developers lacking clinical expertise. We report the vulnerabilities found, categorise them, and present the results of a replication study assessing the vulnerabilities across all LLMs provided.
Predicting Long-Term Allograft Survival in Liver Transplant Recipients
Aug 10, 2024



Liver allograft failure occurs in approximately 20% of liver transplant recipients within five years post-transplant, leading to mortality or the need for retransplantation. Providing an accurate and interpretable model for individualized risk estimation of graft failure is essential for improving post-transplant care. To this end, we introduce the Model for Allograft Survival (MAS), a simple linear risk score that outperforms other advanced survival models. Using longitudinal patient follow-up data from the United States (U.S.), we develop our models on 82,959 liver transplant recipients and conduct multi-site evaluations on 11 regions. Additionally, by testing on a separate non-U.S. cohort, we explore the out-of-distribution generalization performance of various models without additional fine-tuning, a crucial property for clinical deployment. We find that the most complex models are also the ones most vulnerable to distribution shifts despite achieving the best in-distribution performance. Our findings not only provide a strong risk score for predicting long-term graft failure but also suggest that the routine machine learning pipeline with only in-distribution held-out validation could create harmful consequences for patients at deployment.
InterpreTabNet: Distilling Predictive Signals from Tabular Data by Salient Feature Interpretation
Jun 01, 2024



Tabular data are omnipresent in various sectors of industries. Neural networks for tabular data such as TabNet have been proposed to make predictions while leveraging the attention mechanism for interpretability. However, the inferred attention masks are often dense, making it challenging to come up with rationales about the predictive signal. To remedy this, we propose InterpreTabNet, a variant of the TabNet model that models the attention mechanism as a latent variable sampled from a Gumbel-Softmax distribution. This enables us to regularize the model to learn distinct concepts in the attention masks via a KL Divergence regularizer. It prevents overlapping feature selection by promoting sparsity which maximizes the model's efficacy and improves interpretability to determine the important features when predicting the outcome. To assist in the interpretation of feature interdependencies from our model, we employ a large language model (GPT-4) and use prompt engineering to map from the learned feature mask onto natural language text describing the learned signal. Through comprehensive experiments on real-world datasets, we demonstrate that InterpreTabNet outperforms previous methods for interpreting tabular data while attaining competitive accuracy.
Copula-Based Deep Survival Models for Dependent Censoring
Jun 20, 2023
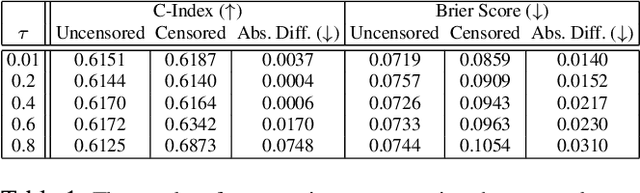
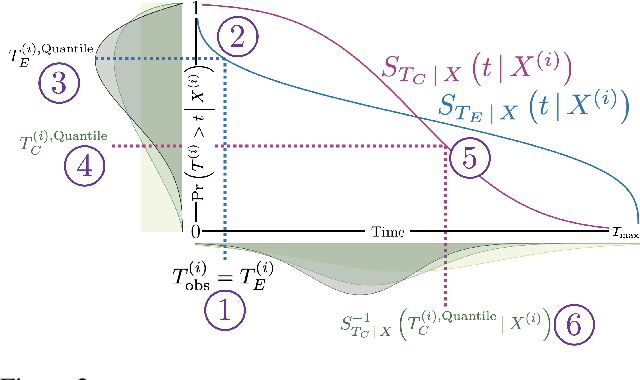
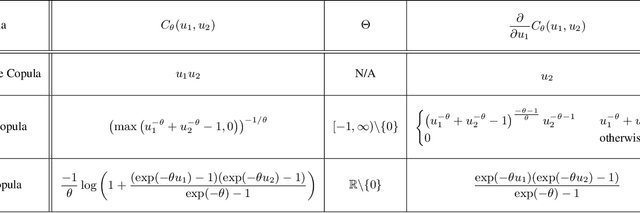
A survival dataset describes a set of instances (e.g. patients) and provides, for each, either the time until an event (e.g. death), or the censoring time (e.g. when lost to follow-up - which is a lower bound on the time until the event). We consider the challenge of survival prediction: learning, from such data, a predictive model that can produce an individual survival distribution for a novel instance. Many contemporary methods of survival prediction implicitly assume that the event and censoring distributions are independent conditional on the instance's covariates - a strong assumption that is difficult to verify (as we observe only one outcome for each instance) and which can induce significant bias when it does not hold. This paper presents a parametric model of survival that extends modern non-linear survival analysis by relaxing the assumption of conditional independence. On synthetic and semi-synthetic data, our approach significantly improves estimates of survival distributions compared to the standard that assumes conditional independence in the data.
CompLex --- A New Corpus for Lexical Complexity Predicition from Likert Scale Data
Mar 16, 2020
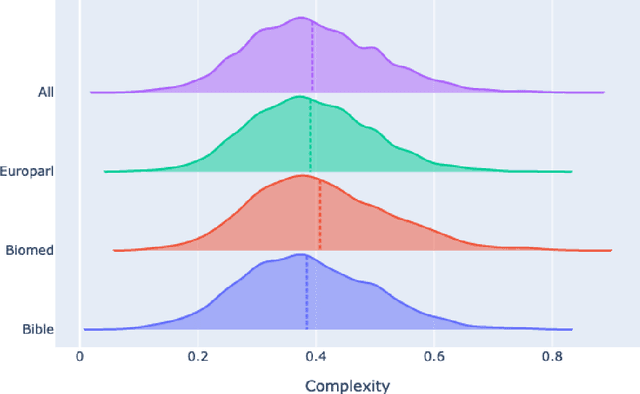
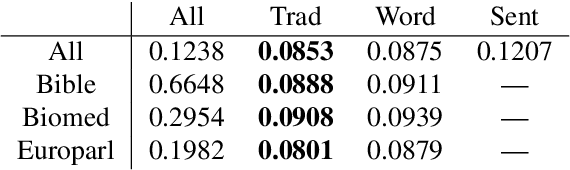
Predicting which words are considered hard to understand for a given target population is a vital step in many NLP applications such as text simplification. This task is commonly referred to as Complex Word Identification (CWI). With a few exceptions, previous studies have approached the task as a binary classification task in which systems predict a complexity value (complex vs. non-complex) for a set of target words in a text. This choice is motivated by the fact that all CWI datasets compiled so far have been annotated using a binary annotation scheme. Our paper addresses this limitation by presenting the first English dataset for continuous lexical complexity prediction. We use a 5-point Likert scale scheme to annotate complex words in texts from three sources/domains: the Bible, Europarl, and biomedical texts. This resulted in a corpus of 9,476 sentences each annotated by around 7 annotators.