 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVaPR -- Vision-language Preference alignment for Reasoning
Oct 02, 2025Preference finetuning methods like Direct Preference Optimization (DPO) with AI-generated feedback have shown promise in aligning Large Vision-Language Models (LVLMs) with human preferences. However, existing techniques overlook the prevalence of noise in synthetic preference annotations in the form of stylistic and length biases. To this end, we introduce a hard-negative response generation framework based on LLM-guided response editing, that produces rejected responses with targeted errors, maintaining stylistic and length similarity to the accepted ones. Using this framework, we develop the VaPR dataset, comprising 30K high-quality samples, to finetune three LVLM families: LLaVA-V1.5, Qwen2VL & Qwen2.5VL (2B-13B sizes). Our VaPR models deliver significant performance improvements across ten benchmarks, achieving average gains of 6.5% (LLaVA), 4.0% (Qwen2VL), and 1.5% (Qwen2.5VL), with notable improvements on reasoning tasks. A scaling analysis shows that performance consistently improves with data size, with LLaVA models benefiting even at smaller scales. Moreover, VaPR reduces the tendency to answer "Yes" in binary questions - addressing a common failure mode in LVLMs like LLaVA. Lastly, we show that the framework generalizes to open-source LLMs as editors, with models trained on VaPR-OS achieving ~99% of the performance of models trained on \name, which is synthesized using GPT-4o. Our data, models, and code can be found on the project page https://vap-r.github.io
The Curious Language Model: Strategic Test-Time Information Acquisition
Jun 10, 2025



Decision-makers often possess insufficient information to render a confident decision. In these cases, the decision-maker can often undertake actions to acquire the necessary information about the problem at hand, e.g., by consulting knowledgeable authorities or by conducting experiments. Importantly, different levers of information acquisition come with different costs, posing the challenge of selecting the actions that are both informative and cost-effective. In this work, we propose CuriosiTree, a heuristic-based, test-time policy for zero-shot information acquisition in large language models (LLMs). CuriosiTree employs a greedy tree search to estimate the expected information gain of each action and strategically chooses actions based on a balance of anticipated information gain and associated cost. Empirical validation in a clinical diagnosis simulation shows that CuriosiTree enables cost-effective integration of heterogenous sources of information, and outperforms baseline action selection strategies in selecting action sequences that enable accurate diagnosis.
ConTextual: Evaluating Context-Sensitive Text-Rich Visual Reasoning in Large Multimodal Models
Jan 24, 2024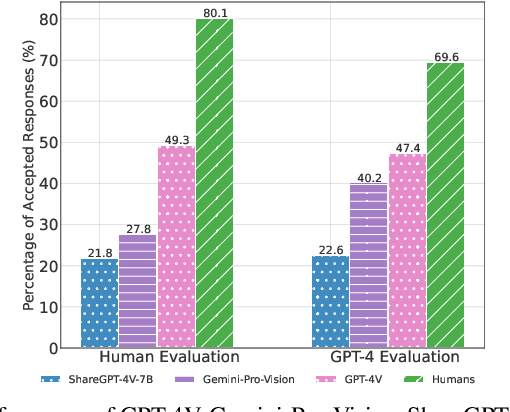
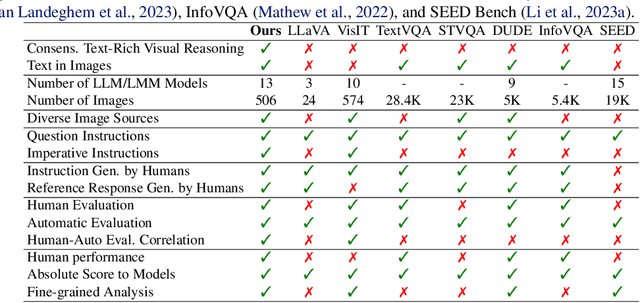

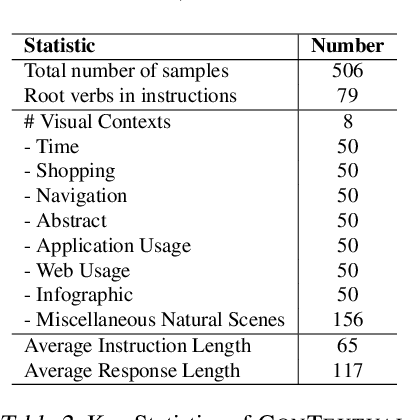
Recent advancements in AI have led to the development of large multimodal models (LMMs) capable of processing complex tasks involving joint reasoning over text and visual content in the image (e.g., navigating maps in public places). This paper introduces ConTextual, a novel benchmark comprising instructions designed explicitly to evaluate LMMs' ability to perform context-sensitive text-rich visual reasoning. ConTextual emphasizes diverse real-world scenarios (e.g., time-reading, navigation, shopping and more) demanding a deeper understanding of the interactions between textual and visual elements. Our findings reveal a significant performance gap of 30.8% between the best-performing LMM, GPT-4V(ision), and human capabilities using human evaluation indicating substantial room for improvement in context-sensitive text-rich visual reasoning. Notably, while GPT-4V excelled in abstract categories like meme and quote interpretation, its overall performance still lagged behind humans. In addition to human evaluations, we also employed automatic evaluation metrics using GPT-4, uncovering similar trends in performance disparities. We also perform a fine-grained evaluation across diverse visual contexts and provide qualitative analysis which provides a robust framework for future advancements in the LMM design. https://con-textual.github.io/
Multi-Attributed and Structured Text-to-Face Synthesis
Aug 25, 2021
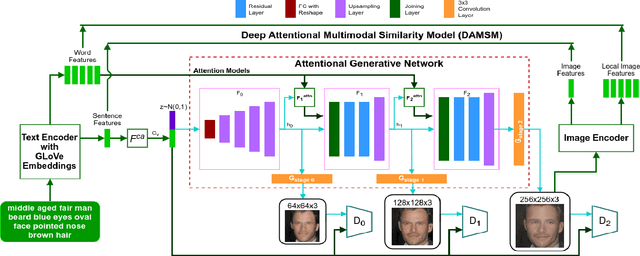
Generative Adversarial Networks (GANs) have revolutionized image synthesis through many applications like face generation, photograph editing, and image super-resolution. Image synthesis using GANs has predominantly been uni-modal, with few approaches that can synthesize images from text or other data modes. Text-to-image synthesis, especially text-to-face synthesis, has promising use cases of robust face-generation from eye witness accounts and augmentation of the reading experience with visual cues. However, only a couple of datasets provide consolidated face data and textual descriptions for text-to-face synthesis. Moreover, these textual annotations are less extensive and descriptive, which reduces the diversity of faces generated from it. This paper empirically proves that increasing the number of facial attributes in each textual description helps GANs generate more diverse and real-looking faces. To prove this, we propose a new methodology that focuses on using structured textual descriptions. We also consolidate a Multi-Attributed and Structured Text-to-face (MAST) dataset consisting of high-quality images with structured textual annotations and make it available to researchers to experiment and build upon. Lastly, we report benchmark Frechet's Inception Distance (FID), Facial Semantic Similarity (FSS), and Facial Semantic Distance (FSD) scores for the MAST dataset.
Landmark-Aware and Part-based Ensemble Transfer Learning Network for Facial Expression Recognition from Static images
Apr 22, 2021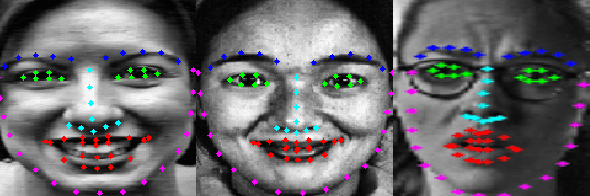
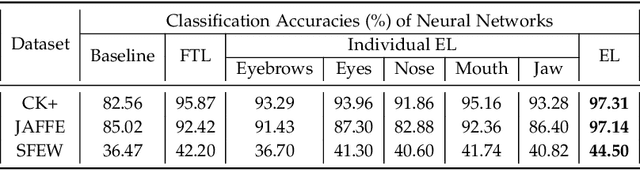

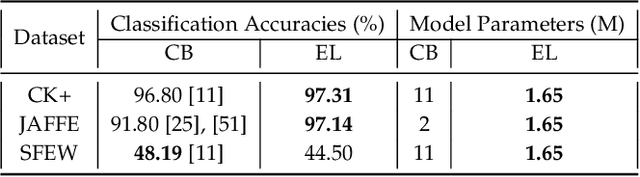
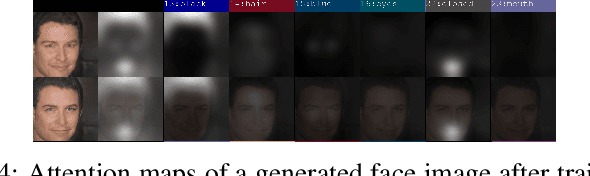
Facial Expression Recognition from static images is a challenging problem in computer vision applications. Convolutional Neural Network (CNN), the state-of-the-art method for various computer vision tasks, has had limited success in predicting expressions from faces having extreme poses, illumination, and occlusion conditions. To mitigate this issue, CNNs are often accompanied by techniques like transfer, multi-task, or ensemble learning that often provide high accuracy at the cost of high computational complexity. In this work, we propose a Part-based Ensemble Transfer Learning network, which models how humans recognize facial expressions by correlating the spatial orientation pattern of the facial features with a specific expression. It consists of 5 sub-networks, in which each sub-network performs transfer learning from one of the five subsets of facial landmarks: eyebrows, eyes, nose, mouth, or jaw to expression classification. We test the proposed network on the CK+, JAFFE, and SFEW datasets, and it outperforms the benchmark for CK+ and JAFFE datasets by 0.51\% and 5.34\%, respectively. Additionally, it consists of a total of 1.65M model parameters and requires only 3.28 $\times$ $10^{6}$ FLOPS, which ensures computational efficiency for real-time deployment. Grad-CAM visualizations of our proposed ensemble highlight the complementary nature of its sub-networks, a key design parameter of an effective ensemble network. Lastly, cross-dataset evaluation results reveal that our proposed ensemble has a high generalization capacity. Our model trained on the SFEW Train dataset achieves an accuracy of 47.53\% on the CK+ dataset, which is higher than what it achieves on the SFEW Valid dataset.
Identifying Water Stress in Chickpea Plant by Analyzing Progressive Changes in Shoot Images using Deep Learning
Apr 16, 2021



To meet the needs of a growing world population, we need to increase the global agricultural yields by employing modern, precision, and automated farming methods. In the recent decade, high-throughput plant phenotyping techniques, which combine non-invasive image analysis and machine learning, have been successfully applied to identify and quantify plant health and diseases. However, these image-based machine learning usually do not consider plant stress's progressive or temporal nature. This time-invariant approach also requires images showing severe signs of stress to ensure high confidence detections, thereby reducing this approach's feasibility for early detection and recovery of plants under stress. In order to overcome the problem mentioned above, we propose a temporal analysis of the visual changes induced in the plant due to stress and apply it for the specific case of water stress identification in Chickpea plant shoot images. For this, we have considered an image dataset of two chickpea varieties JG-62 and Pusa-372, under three water stress conditions; control, young seedling, and before flowering, captured over five months. We then develop an LSTM-CNN architecture to learn visual-temporal patterns from this dataset and predict the water stress category with high confidence. To establish a baseline context, we also conduct a comparative analysis of the CNN architecture used in the proposed model with the other CNN techniques used for the time-invariant classification of water stress. The results reveal that our proposed LSTM-CNN model has resulted in the ceiling level classification performance of \textbf{98.52\%} on JG-62 and \textbf{97.78\%} on Pusa-372 and the chickpea plant data. Lastly, we perform an ablation study to determine the LSTM-CNN model's performance on decreasing the amount of temporal session data used for training.