 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Attributed and Structured Text-to-Face Synthesis
Paper and Code

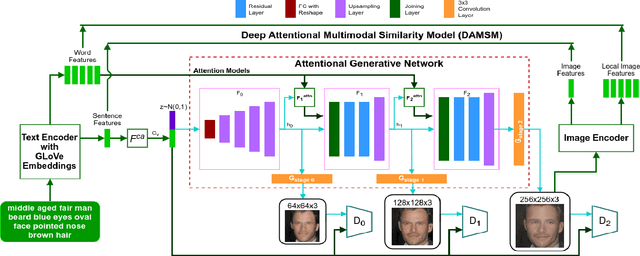
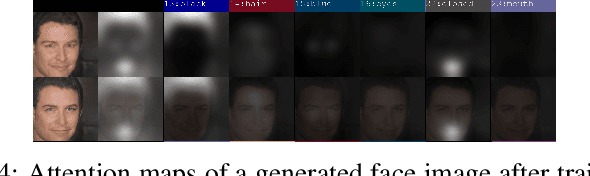
Generative Adversarial Networks (GANs) have revolutionized image synthesis through many applications like face generation, photograph editing, and image super-resolution. Image synthesis using GANs has predominantly been uni-modal, with few approaches that can synthesize images from text or other data modes. Text-to-image synthesis, especially text-to-face synthesis, has promising use cases of robust face-generation from eye witness accounts and augmentation of the reading experience with visual cues. However, only a couple of datasets provide consolidated face data and textual descriptions for text-to-face synthesis. Moreover, these textual annotations are less extensive and descriptive, which reduces the diversity of faces generated from it. This paper empirically proves that increasing the number of facial attributes in each textual description helps GANs generate more diverse and real-looking faces. To prove this, we propose a new methodology that focuses on using structured textual descriptions. We also consolidate a Multi-Attributed and Structured Text-to-face (MAST) dataset consisting of high-quality images with structured textual annotations and make it available to researchers to experiment and build upon. Lastly, we report benchmark Frechet's Inception Distance (FID), Facial Semantic Similarity (FSS), and Facial Semantic Distance (FSD) scores for the MAST dataset.