 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandmark-Aware and Part-based Ensemble Transfer Learning Network for Facial Expression Recognition from Static images
Paper and Code
Apr 22, 2021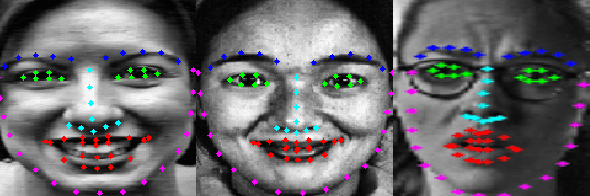
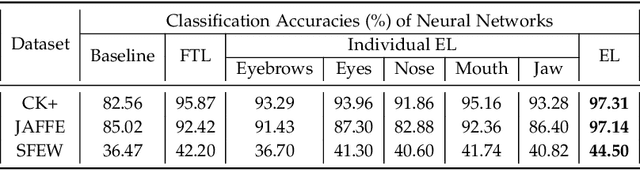

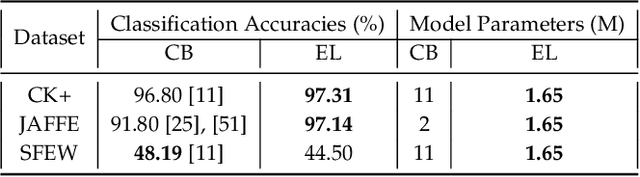
Facial Expression Recognition from static images is a challenging problem in computer vision applications. Convolutional Neural Network (CNN), the state-of-the-art method for various computer vision tasks, has had limited success in predicting expressions from faces having extreme poses, illumination, and occlusion conditions. To mitigate this issue, CNNs are often accompanied by techniques like transfer, multi-task, or ensemble learning that often provide high accuracy at the cost of high computational complexity. In this work, we propose a Part-based Ensemble Transfer Learning network, which models how humans recognize facial expressions by correlating the spatial orientation pattern of the facial features with a specific expression. It consists of 5 sub-networks, in which each sub-network performs transfer learning from one of the five subsets of facial landmarks: eyebrows, eyes, nose, mouth, or jaw to expression classification. We test the proposed network on the CK+, JAFFE, and SFEW datasets, and it outperforms the benchmark for CK+ and JAFFE datasets by 0.51\% and 5.34\%, respectively. Additionally, it consists of a total of 1.65M model parameters and requires only 3.28 $\times$ $10^{6}$ FLOPS, which ensures computational efficiency for real-time deployment. Grad-CAM visualizations of our proposed ensemble highlight the complementary nature of its sub-networks, a key design parameter of an effective ensemble network. Lastly, cross-dataset evaluation results reveal that our proposed ensemble has a high generalization capacity. Our model trained on the SFEW Train dataset achieves an accuracy of 47.53\% on the CK+ dataset, which is higher than what it achieves on the SFEW Valid dataset.