 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Models Encode Clinical Guidelines for Concept-Based Medical Reasoning
Mar 09, 2026Concept Bottleneck Models (CBMs) are a prominent framework for interpretable AI that map learned visual features to a set of meaningful concepts for task-specific downstream predictions. Their sequential structure enhances transparency by connecting model predictions to the underlying concepts that support them. In medical imaging, where transparency is essential, CBMs offer an appealing foundation for explainable model design. However, discrete concept representations often overlook broader clinical context such as diagnostic guidelines and expert heuristics, reducing reliability in complex cases. We propose MedCBR, a concept-based reasoning framework that integrates clinical guidelines with vision-language and reasoning models. Labeled clinical descriptors are transformed into guideline-conformant text, and a concept-based model is trained with a multitask objective combining multimodal contrastive alignment, concept supervision, and diagnostic classification to jointly ground image features, concepts, and pathology. A reasoning model then converts these predictions into structured clinical narratives that explain the diagnosis, emulating expert reasoning based on established guidelines. MedCBR achieves superior diagnostic and concept-level performance, with AUROCs of 94.2% on ultrasound and 84.0% on mammography. Further experiments on non-medical datasets achieve 86.1% accuracy. Our framework enhances interpretability and forms an end-to-end bridge from medical image analysis to decision-making.
GUIDE-US: Grade-Informed Unpaired Distillation of Encoder Knowledge from Histopathology to Micro-UltraSound
Feb 22, 2026Purpose: Non-invasive grading of prostate cancer (PCa) from micro-ultrasound (micro-US) could expedite triage and guide biopsies toward the most aggressive regions, yet current models struggle to infer tissue micro-structure at coarse imaging resolutions. Methods: We introduce an unpaired histopathology knowledge-distillation strategy that trains a micro-US encoder to emulate the embedding distribution of a pretrained histopathology foundation model, conditioned on International Society of Urological Pathology (ISUP) grades. Training requires no patient-level pairing or image registration, and histopathology inputs are not used at inference. Results: Compared to the current state of the art, our approach increases sensitivity to clinically significant PCa (csPCa) at 60% specificity by 3.5% and improves overall sensitivity at 60% specificity by 1.2%. Conclusion: By enabling earlier and more dependable cancer risk stratification solely from imaging, our method advances clinical feasibility. Source code will be publicly released upon publication.
ProstNFound+: A Prospective Study using Medical Foundation Models for Prostate Cancer Detection
Oct 30, 2025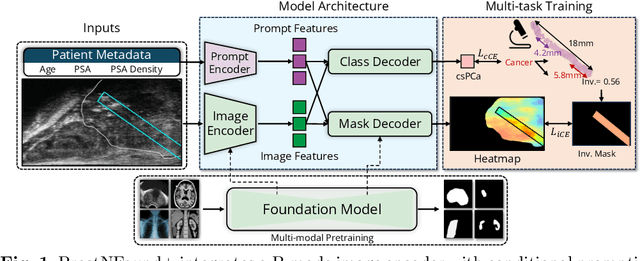
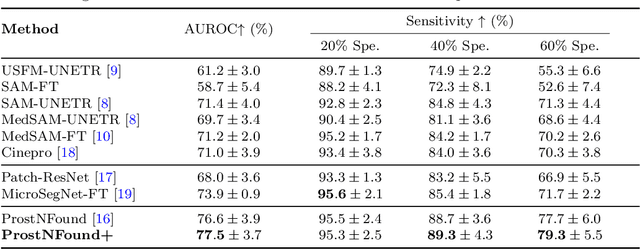
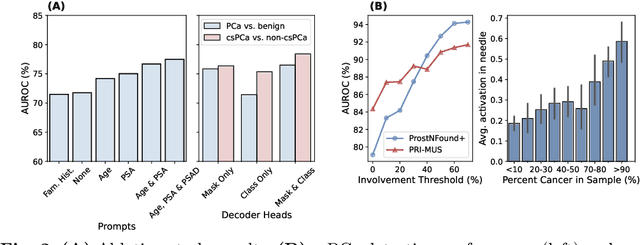
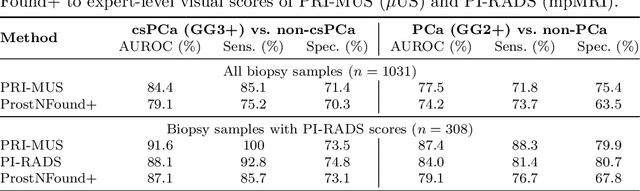
Purpose: Medical foundation models (FMs) offer a path to build high-performance diagnostic systems. However, their application to prostate cancer (PCa) detection from micro-ultrasound ({\mu}US) remains untested in clinical settings. We present ProstNFound+, an adaptation of FMs for PCa detection from {\mu}US, along with its first prospective validation. Methods: ProstNFound+ incorporates a medical FM, adapter tuning, and a custom prompt encoder that embeds PCa-specific clinical biomarkers. The model generates a cancer heatmap and a risk score for clinically significant PCa. Following training on multi-center retrospective data, the model is prospectively evaluated on data acquired five years later from a new clinical site. Model predictions are benchmarked against standard clinical scoring protocols (PRI-MUS and PI-RADS). Results: ProstNFound+ shows strong generalization to the prospective data, with no performance degradation compared to retrospective evaluation. It aligns closely with clinical scores and produces interpretable heatmaps consistent with biopsy-confirmed lesions. Conclusion: The results highlight its potential for clinical deployment, offering a scalable and interpretable alternative to expert-driven protocols.
Domain Knowledge is Power: Leveraging Physiological Priors for Self Supervised Representation Learning in Electrocardiography
Sep 09, 2025Objective: Electrocardiograms (ECGs) play a crucial role in diagnosing heart conditions; however, the effectiveness of artificial intelligence (AI)-based ECG analysis is often hindered by the limited availability of labeled data. Self-supervised learning (SSL) can address this by leveraging large-scale unlabeled data. We introduce PhysioCLR (Physiology-aware Contrastive Learning Representation for ECG), a physiology-aware contrastive learning framework that incorporates domain-specific priors to enhance the generalizability and clinical relevance of ECG-based arrhythmia classification. Methods: During pretraining, PhysioCLR learns to bring together embeddings of samples that share similar clinically relevant features while pushing apart those that are dissimilar. Unlike existing methods, our method integrates ECG physiological similarity cues into contrastive learning, promoting the learning of clinically meaningful representations. Additionally, we introduce ECG- specific augmentations that preserve the ECG category post augmentation and propose a hybrid loss function to further refine the quality of learned representations. Results: We evaluate PhysioCLR on two public ECG datasets, Chapman and Georgia, for multilabel ECG diagnoses, as well as a private ICU dataset labeled for binary classification. Across the Chapman, Georgia, and private cohorts, PhysioCLR boosts the mean AUROC by 12% relative to the strongest baseline, underscoring its robust cross-dataset generalization. Conclusion: By embedding physiological knowledge into contrastive learning, PhysioCLR enables the model to learn clinically meaningful and transferable ECG eatures. Significance: PhysioCLR demonstrates the potential of physiology-informed SSL to offer a promising path toward more effective and label-efficient ECG diagnostics.
Diverse Prototypical Ensembles Improve Robustness to Subpopulation Shift
May 29, 2025The subpopulationtion shift, characterized by a disparity in subpopulation distributibetween theween the training and target datasets, can significantly degrade the performance of machine learning models. Current solutions to subpopulation shift involve modifying empirical risk minimization with re-weighting strategies to improve generalization. This strategy relies on assumptions about the number and nature of subpopulations and annotations on group membership, which are unavailable for many real-world datasets. Instead, we propose using an ensemble of diverse classifiers to adaptively capture risk associated with subpopulations. Given a feature extractor network, we replace its standard linear classification layer with a mixture of prototypical classifiers, where each member is trained to classify the data while focusing on different features and samples from other members. In empirical evaluation on nine real-world datasets, covering diverse domains and kinds of subpopulation shift, our method of Diverse Prototypical Ensembles (DPEs) often outperforms the prior state-of-the-art in worst-group accuracy. The code is available at https://github.com/minhto2802/dpe4subpop
TRUSWorthy: Toward Clinically Applicable Deep Learning for Confident Detection of Prostate Cancer in Micro-Ultrasound
Feb 20, 2025While deep learning methods have shown great promise in improving the effectiveness of prostate cancer (PCa) diagnosis by detecting suspicious lesions from trans-rectal ultrasound (TRUS), they must overcome multiple simultaneous challenges. There is high heterogeneity in tissue appearance, significant class imbalance in favor of benign examples, and scarcity in the number and quality of ground truth annotations available to train models. Failure to address even a single one of these problems can result in unacceptable clinical outcomes.We propose TRUSWorthy, a carefully designed, tuned, and integrated system for reliable PCa detection. Our pipeline integrates self-supervised learning, multiple-instance learning aggregation using transformers, random-undersampled boosting and ensembling: these address label scarcity, weak labels, class imbalance, and overconfidence, respectively. We train and rigorously evaluate our method using a large, multi-center dataset of micro-ultrasound data. Our method outperforms previous state-of-the-art deep learning methods in terms of accuracy and uncertainty calibration, with AUROC and balanced accuracy scores of 79.9% and 71.5%, respectively. On the top 20% of predictions with the highest confidence, we can achieve a balanced accuracy of up to 91%. The success of TRUSWorthy demonstrates the potential of integrated deep learning solutions to meet clinical needs in a highly challenging deployment setting, and is a significant step towards creating a trustworthy system for computer-assisted PCa diagnosis.
Cinepro: Robust Training of Foundation Models for Cancer Detection in Prostate Ultrasound Cineloops
Jan 21, 2025



Prostate cancer (PCa) detection using deep learning (DL) models has shown potential for enhancing real-time guidance during biopsies. However, prostate ultrasound images lack pixel-level cancer annotations, introducing label noise. Current approaches often focus on limited regions of interest (ROIs), disregarding anatomical context necessary for accurate diagnosis. Foundation models can overcome this limitation by analyzing entire images to capture global spatial relationships; however, they still encounter challenges stemming from the weak labels associated with coarse pathology annotations in ultrasound data. We introduce Cinepro, a novel framework that strengthens foundation models' ability to localize PCa in ultrasound cineloops. Cinepro adapts robust training by integrating the proportion of cancer tissue reported by pathology in a biopsy core into its loss function to address label noise, providing a more nuanced supervision. Additionally, it leverages temporal data across multiple frames to apply robust augmentations, enhancing the model's ability to learn stable cancer-related features. Cinepro demonstrates superior performance on a multi-center prostate ultrasound dataset, achieving an AUROC of 77.1% and a balanced accuracy of 83.8%, surpassing current benchmarks. These findings underscore Cinepro's promise in advancing foundation models for weakly labeled ultrasound data.
Calibrated Diverse Ensemble Entropy Minimization for Robust Test-Time Adaptation in Prostate Cancer Detection
Jul 17, 2024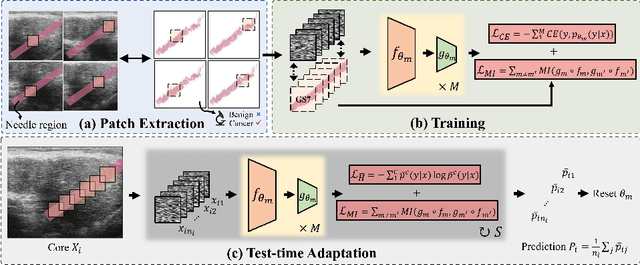
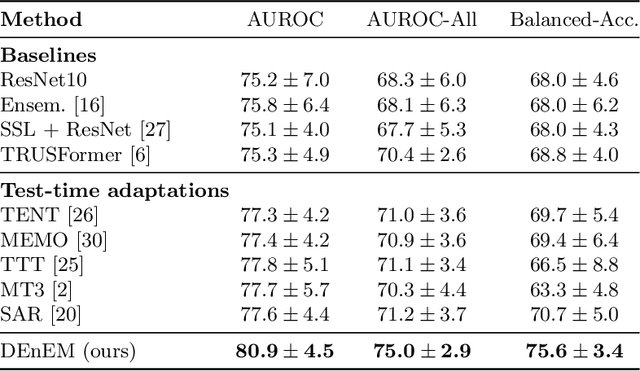

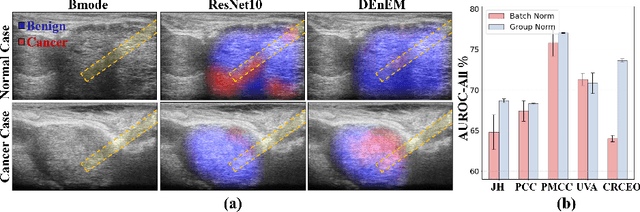
High resolution micro-ultrasound has demonstrated promise in real-time prostate cancer detection, with deep learning becoming a prominent tool for learning complex tissue properties reflected on ultrasound. However, a significant roadblock to real-world deployment remains, which prior works often overlook: model performance suffers when applied to data from different clinical centers due to variations in data distribution. This distribution shift significantly impacts the model's robustness, posing major challenge to clinical deployment. Domain adaptation and specifically its test-time adaption (TTA) variant offer a promising solution to address this challenge. In a setting designed to reflect real-world conditions, we compare existing methods to state-of-the-art TTA approaches adopted for cancer detection, demonstrating the lack of robustness to distribution shifts in the former. We then propose Diverse Ensemble Entropy Minimization (DEnEM), questioning the effectiveness of current TTA methods on ultrasound data. We show that these methods, although outperforming baselines, are suboptimal due to relying on neural networks output probabilities, which could be uncalibrated, or relying on data augmentation, which is not straightforward to define on ultrasound data. Our results show a significant improvement of $5\%$ to $7\%$ in AUROC over the existing methods and $3\%$ to $5\%$ over TTA methods, demonstrating the advantage of DEnEM in addressing distribution shift. \keywords{Ultrasound Imaging \and Prostate Cancer \and Computer-aided Diagnosis \and Distribution Shift Robustness \and Test-time Adaptation.}
Benchmarking Image Transformers for Prostate Cancer Detection from Ultrasound Data
Mar 27, 2024PURPOSE: Deep learning methods for classifying prostate cancer (PCa) in ultrasound images typically employ convolutional networks (CNNs) to detect cancer in small regions of interest (ROI) along a needle trace region. However, this approach suffers from weak labelling, since the ground-truth histopathology labels do not describe the properties of individual ROIs. Recently, multi-scale approaches have sought to mitigate this issue by combining the context awareness of transformers with a CNN feature extractor to detect cancer from multiple ROIs using multiple-instance learning (MIL). In this work, we present a detailed study of several image transformer architectures for both ROI-scale and multi-scale classification, and a comparison of the performance of CNNs and transformers for ultrasound-based prostate cancer classification. We also design a novel multi-objective learning strategy that combines both ROI and core predictions to further mitigate label noise. METHODS: We evaluate 3 image transformers on ROI-scale cancer classification, then use the strongest model to tune a multi-scale classifier with MIL. We train our MIL models using our novel multi-objective learning strategy and compare our results to existing baselines. RESULTS: We find that for both ROI-scale and multi-scale PCa detection, image transformer backbones lag behind their CNN counterparts. This deficit in performance is even more noticeable for larger models. When using multi-objective learning, we can improve performance of MIL, with a 77.9% AUROC, a sensitivity of 75.9%, and a specificity of 66.3%. CONCLUSION: Convolutional networks are better suited for modelling sparse datasets of prostate ultrasounds, producing more robust features than transformers in PCa detection. Multi-scale methods remain the best architecture for this task, with multi-objective learning presenting an effective way to improve performance.
Manifold DivideMix: A Semi-Supervised Contrastive Learning Framework for Severe Label Noise
Aug 13, 2023



Deep neural networks have proven to be highly effective when large amounts of data with clean labels are available. However, their performance degrades when training data contains noisy labels, leading to poor generalization on the test set. Real-world datasets contain noisy label samples that either have similar visual semantics to other classes (in-distribution) or have no semantic relevance to any class (out-of-distribution) in the dataset. Most state-of-the-art methods leverage ID labeled noisy samples as unlabeled data for semi-supervised learning, but OOD labeled noisy samples cannot be used in this way because they do not belong to any class within the dataset. Hence, in this paper, we propose incorporating the information from all the training data by leveraging the benefits of self-supervised training. Our method aims to extract a meaningful and generalizable embedding space for each sample regardless of its label. Then, we employ a simple yet effective K-nearest neighbor method to remove portions of out-of-distribution samples. By discarding these samples, we propose an iterative "Manifold DivideMix" algorithm to find clean and noisy samples, and train our model in a semi-supervised way. In addition, we propose "MixEMatch", a new algorithm for the semi-supervised step that involves mixup augmentation at the input and final hidden representations of the model. This will extract better representations by interpolating both in the input and manifold spaces. Extensive experiments on multiple synthetic-noise image benchmarks and real-world web-crawled datasets demonstrate the effectiveness of our proposed framework. Code is available at https://github.com/Fahim-F/ManifoldDivideMix.