 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Diverse Ensemble Entropy Minimization for Robust Test-Time Adaptation in Prostate Cancer Detection
Jul 17, 2024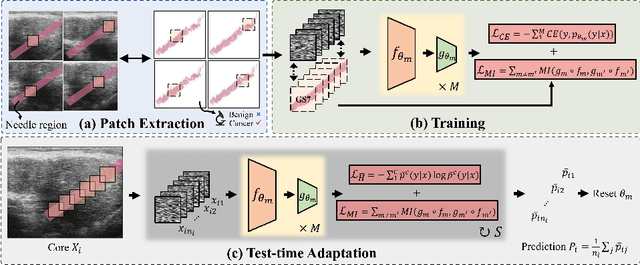
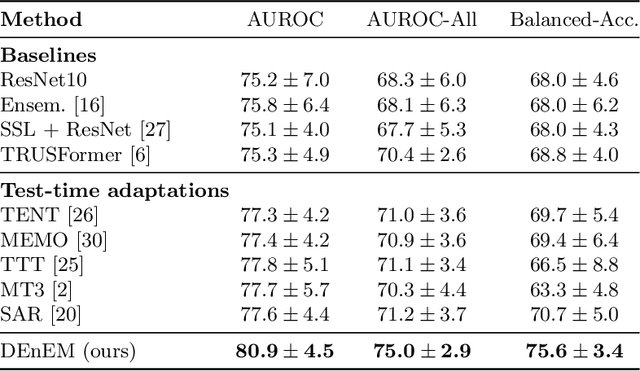

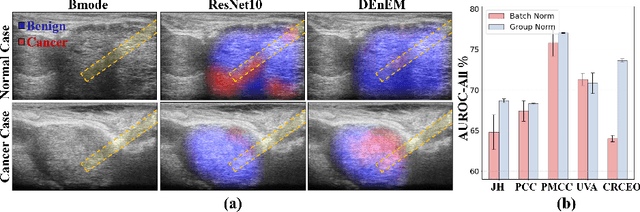
High resolution micro-ultrasound has demonstrated promise in real-time prostate cancer detection, with deep learning becoming a prominent tool for learning complex tissue properties reflected on ultrasound. However, a significant roadblock to real-world deployment remains, which prior works often overlook: model performance suffers when applied to data from different clinical centers due to variations in data distribution. This distribution shift significantly impacts the model's robustness, posing major challenge to clinical deployment. Domain adaptation and specifically its test-time adaption (TTA) variant offer a promising solution to address this challenge. In a setting designed to reflect real-world conditions, we compare existing methods to state-of-the-art TTA approaches adopted for cancer detection, demonstrating the lack of robustness to distribution shifts in the former. We then propose Diverse Ensemble Entropy Minimization (DEnEM), questioning the effectiveness of current TTA methods on ultrasound data. We show that these methods, although outperforming baselines, are suboptimal due to relying on neural networks output probabilities, which could be uncalibrated, or relying on data augmentation, which is not straightforward to define on ultrasound data. Our results show a significant improvement of $5\%$ to $7\%$ in AUROC over the existing methods and $3\%$ to $5\%$ over TTA methods, demonstrating the advantage of DEnEM in addressing distribution shift. \keywords{Ultrasound Imaging \and Prostate Cancer \and Computer-aided Diagnosis \and Distribution Shift Robustness \and Test-time Adaptation.}
Deep Learning with Parametric Lenses
Mar 30, 2024We propose a categorical semantics for machine learning algorithms in terms of lenses, parametric maps, and reverse derivative categories. This foundation provides a powerful explanatory and unifying framework: it encompasses a variety of gradient descent algorithms such as ADAM, AdaGrad, and Nesterov momentum, as well as a variety of loss functions such as MSE and Softmax cross-entropy, and different architectures, shedding new light on their similarities and differences. Furthermore, our approach to learning has examples generalising beyond the familiar continuous domains (modelled in categories of smooth maps) and can be realised in the discrete setting of Boolean and polynomial circuits. We demonstrate the practical significance of our framework with an implementation in Python.
TRUSformer: Improving Prostate Cancer Detection from Micro-Ultrasound Using Attention and Self-Supervision
Mar 03, 2023A large body of previous machine learning methods for ultrasound-based prostate cancer detection classify small regions of interest (ROIs) of ultrasound signals that lie within a larger needle trace corresponding to a prostate tissue biopsy (called biopsy core). These ROI-scale models suffer from weak labeling as histopathology results available for biopsy cores only approximate the distribution of cancer in the ROIs. ROI-scale models do not take advantage of contextual information that are normally considered by pathologists, i.e. they do not consider information about surrounding tissue and larger-scale trends when identifying cancer. We aim to improve cancer detection by taking a multi-scale, i.e. ROI-scale and biopsy core-scale, approach. Methods: Our multi-scale approach combines (i) an "ROI-scale" model trained using self-supervised learning to extract features from small ROIs and (ii) a "core-scale" transformer model that processes a collection of extracted features from multiple ROIs in the needle trace region to predict the tissue type of the corresponding core. Attention maps, as a byproduct, allow us to localize cancer at the ROI scale. We analyze this method using a dataset of micro-ultrasound acquired from 578 patients who underwent prostate biopsy, and compare our model to baseline models and other large-scale studies in the literature. Results and Conclusions: Our model shows consistent and substantial performance improvements compared to ROI-scale-only models. It achieves 80.3% AUROC, a statistically significant improvement over ROI-scale classification. We also compare our method to large studies on prostate cancer detection, using other imaging modalities. Our code is publicly available at www.github.com/med-i-lab/TRUSFormer
Predicting article quality scores with machine learning: The UK Research Excellence Framework
Dec 11, 2022National research evaluation initiatives and incentive schemes have previously chosen between simplistic quantitative indicators and time-consuming peer review, sometimes supported by bibliometrics. Here we assess whether artificial intelligence (AI) could provide a third alternative, estimating article quality using more multiple bibliometric and metadata inputs. We investigated this using provisional three-level REF2021 peer review scores for 84,966 articles submitted to the UK Research Excellence Framework 2021, matching a Scopus record 2014-18 and with a substantial abstract. We found that accuracy is highest in the medical and physical sciences Units of Assessment (UoAs) and economics, reaching 42% above the baseline (72% overall) in the best case. This is based on 1000 bibliometric inputs and half of the articles used for training in each UoA. Prediction accuracies above the baseline for the social science, mathematics, engineering, arts, and humanities UoAs were much lower or close to zero. The Random Forest Classifier (standard or ordinal) and Extreme Gradient Boosting Classifier algorithms performed best from the 32 tested. Accuracy was lower if UoAs were merged or replaced by Scopus broad categories. We increased accuracy with an active learning strategy and by selecting articles with higher prediction probabilities, as estimated by the algorithms, but this substantially reduced the number of scores predicted.
Can REF output quality scores be assigned by AI? Experimental evidence
Dec 11, 2022This document describes strategies for using Artificial Intelligence (AI) to predict some journal article scores in future research assessment exercises. Five strategies have been assessed.
Towards Confident Detection of Prostate Cancer using High Resolution Micro-ultrasound
Jul 21, 2022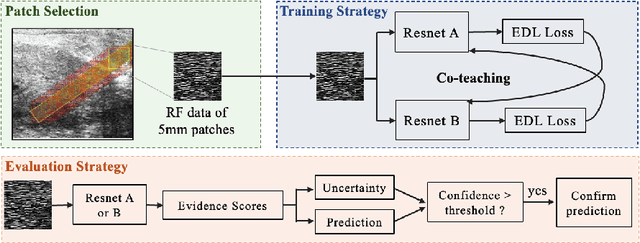
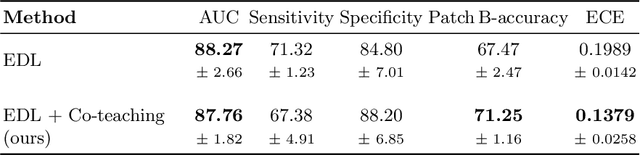
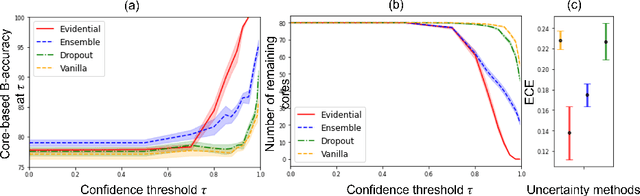
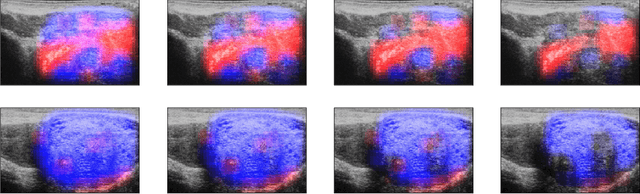
MOTIVATION: Detection of prostate cancer during transrectal ultrasound-guided biopsy is challenging. The highly heterogeneous appearance of cancer, presence of ultrasound artefacts, and noise all contribute to these difficulties. Recent advancements in high-frequency ultrasound imaging - micro-ultrasound - have drastically increased the capability of tissue imaging at high resolution. Our aim is to investigate the development of a robust deep learning model specifically for micro-ultrasound-guided prostate cancer biopsy. For the model to be clinically adopted, a key challenge is to design a solution that can confidently identify the cancer, while learning from coarse histopathology measurements of biopsy samples that introduce weak labels. METHODS: We use a dataset of micro-ultrasound images acquired from 194 patients, who underwent prostate biopsy. We train a deep model using a co-teaching paradigm to handle noise in labels, together with an evidential deep learning method for uncertainty estimation. We evaluate the performance of our model using the clinically relevant metric of accuracy vs. confidence. RESULTS: Our model achieves a well-calibrated estimation of predictive uncertainty with area under the curve of 88$\%$. The use of co-teaching and evidential deep learning in combination yields significantly better uncertainty estimation than either alone. We also provide a detailed comparison against state-of-the-art in uncertainty estimation.
Categories of Differentiable Polynomial Circuits for Machine Learning
Mar 12, 2022Reverse derivative categories (RDCs) have recently been shown to be a suitable semantic framework for studying machine learning algorithms. Whereas emphasis has been put on training methodologies, less attention has been devoted to particular \emph{model classes}: the concrete categories whose morphisms represent machine learning models. In this paper we study presentations by generators and equations of classes of RDCs. In particular, we propose \emph{polynomial circuits} as a suitable machine learning model. We give an axiomatisation for these circuits and prove a functional completeness result. Finally, we discuss the use of polynomial circuits over specific semirings to perform machine learning with discrete values.
Category Theory in Machine Learning
Jun 13, 2021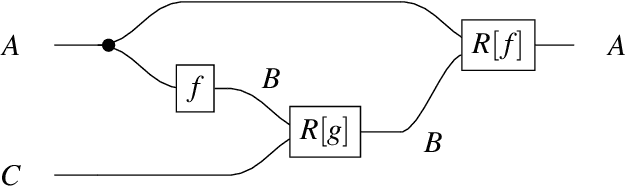


Over the past two decades machine learning has permeated almost every realm of technology. At the same time, many researchers have begun using category theory as a unifying language, facilitating communication between different scientific disciplines. It is therefore unsurprising that there is a burgeoning interest in applying category theory to machine learning. We aim to document the motivations, goals and common themes across these applications. We touch on gradient-based learning, probability, and equivariant learning.
Categorical Foundations of Gradient-Based Learning
Mar 02, 2021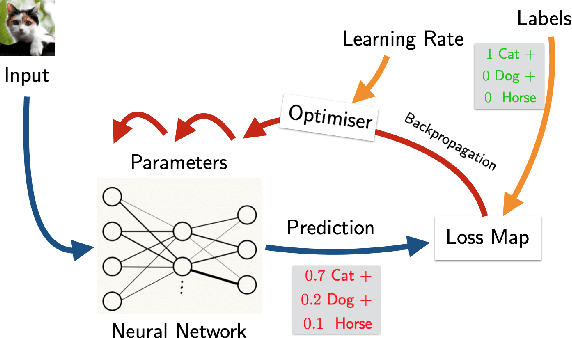
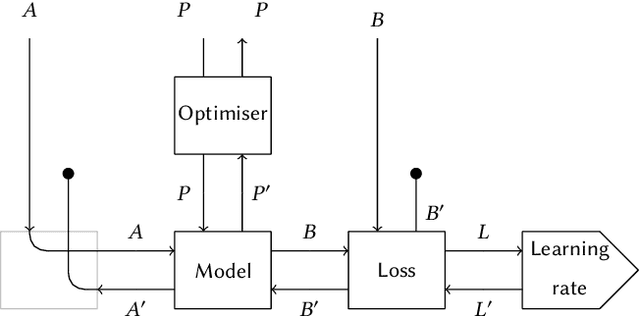
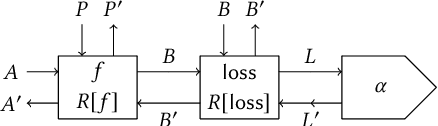
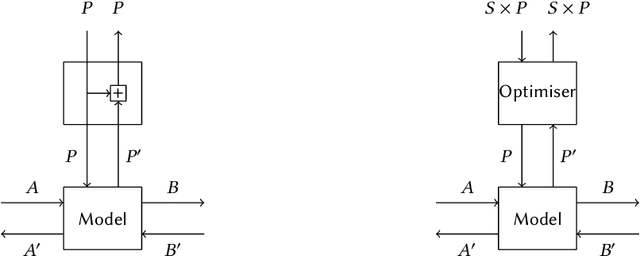
We propose a categorical foundation of gradient-based machine learning algorithms in terms of lenses, parametrised maps, and reverse derivative categories. This foundation provides a powerful explanatory and unifying framework: it encompasses a variety of gradient descent algorithms such as ADAM, AdaGrad, and Nesterov momentum, as well as a variety of loss functions such as as MSE and Softmax cross-entropy, shedding new light on their similarities and differences. Our approach also generalises beyond neural networks (modelled in categories of smooth maps), accounting for other structures relevant to gradient-based learning such as boolean circuits. Finally, we also develop a novel implementation of gradient-based learning in Python, informed by the principles introduced by our framework.
Reverse Derivative Ascent: A Categorical Approach to Learning Boolean Circuits
Jan 26, 2021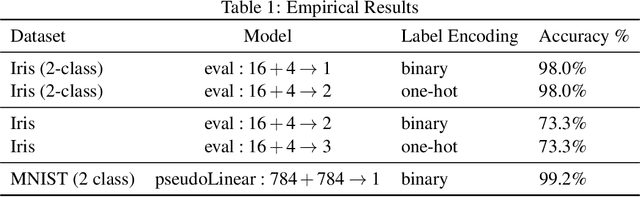
We introduce Reverse Derivative Ascent: a categorical analogue of gradient based methods for machine learning. Our algorithm is defined at the level of so-called reverse differential categories. It can be used to learn the parameters of models which are expressed as morphisms of such categories. Our motivating example is boolean circuits: we show how our algorithm can be applied to such circuits by using the theory of reverse differential categories. Note our methodology allows us to learn the parameters of boolean circuits directly, in contrast to existing binarised neural network approaches. Moreover, we demonstrate its empirical value by giving experimental results on benchmark machine learning datasets.
* In Proceedings ACT 2020, arXiv:2101.07888