 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongEval at CLEF 2025: Longitudinal Evaluation of IR Model Performance
Mar 11, 2025
This paper presents the third edition of the LongEval Lab, part of the CLEF 2025 conference, which continues to explore the challenges of temporal persistence in Information Retrieval (IR). The lab features two tasks designed to provide researchers with test data that reflect the evolving nature of user queries and document relevance over time. By evaluating how model performance degrades as test data diverge temporally from training data, LongEval seeks to advance the understanding of temporal dynamics in IR systems. The 2025 edition aims to engage the IR and NLP communities in addressing the development of adaptive models that can maintain retrieval quality over time in the domains of web search and scientific retrieval.
CORE-GPT: Combining Open Access research and large language models for credible, trustworthy question answering
Jul 06, 2023
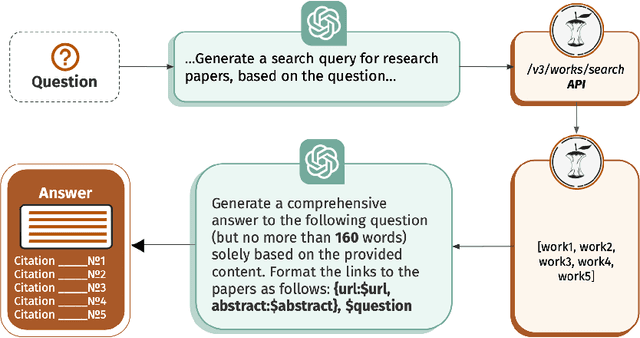

In this paper, we present CORE-GPT, a novel question-answering platform that combines GPT-based language models and more than 32 million full-text open access scientific articles from CORE. We first demonstrate that GPT3.5 and GPT4 cannot be relied upon to provide references or citations for generated text. We then introduce CORE-GPT which delivers evidence-based answers to questions, along with citations and links to the cited papers, greatly increasing the trustworthiness of the answers and reducing the risk of hallucinations. CORE-GPT's performance was evaluated on a dataset of 100 questions covering the top 20 scientific domains in CORE, resulting in 100 answers and links to 500 relevant articles. The quality of the provided answers and and relevance of the links were assessed by two annotators. Our results demonstrate that CORE-GPT can produce comprehensive and trustworthy answers across the majority of scientific domains, complete with links to genuine, relevant scientific articles.
Predicting article quality scores with machine learning: The UK Research Excellence Framework
Dec 11, 2022National research evaluation initiatives and incentive schemes have previously chosen between simplistic quantitative indicators and time-consuming peer review, sometimes supported by bibliometrics. Here we assess whether artificial intelligence (AI) could provide a third alternative, estimating article quality using more multiple bibliometric and metadata inputs. We investigated this using provisional three-level REF2021 peer review scores for 84,966 articles submitted to the UK Research Excellence Framework 2021, matching a Scopus record 2014-18 and with a substantial abstract. We found that accuracy is highest in the medical and physical sciences Units of Assessment (UoAs) and economics, reaching 42% above the baseline (72% overall) in the best case. This is based on 1000 bibliometric inputs and half of the articles used for training in each UoA. Prediction accuracies above the baseline for the social science, mathematics, engineering, arts, and humanities UoAs were much lower or close to zero. The Random Forest Classifier (standard or ordinal) and Extreme Gradient Boosting Classifier algorithms performed best from the 32 tested. Accuracy was lower if UoAs were merged or replaced by Scopus broad categories. We increased accuracy with an active learning strategy and by selecting articles with higher prediction probabilities, as estimated by the algorithms, but this substantially reduced the number of scores predicted.