 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning large language model prompts to extract scores from messy text: A shared dataset and challenge
Jan 26, 2026In some areas of computing, natural language processing and information science, progress is made by sharing datasets and challenging the community to design the best algorithm for an associated task. This article introduces a shared dataset of 1446 short texts, each of which describes a research quality score on the UK scale of 1* to 4*. This is a messy collection, with some texts not containing scores and others including invalid scores or strange formats. With this dataset there is also a description of what constitutes a valid score and a "gold standard" of the correct scores for these texts (including missing values). The challenge is to design a prompt for Large Language Models (LLMs) to extract the scores from these texts as accurately as possible. The format for the response should be a number and no other text so there are two aspects to the challenge: ensuring that the LLM returns only a number, and instructing it to deduce the correct number for the text. As part of this, the LLM prompt needs to explain when to return the missing value code, -1, instead of a number when the text does not clearly contain one. The article also provides an example of a simple prompt. The purpose of the challenge is twofold: to get an effective solution to this problem, and to increase understanding of prompt design and LLM capabilities for complex numerical tasks. The initial solution suggested has an accuracy of 72.6%, so the challenge is to beat this.
Can Small and Reasoning Large Language Models Score Journal Articles for Research Quality and Do Averaging and Few-shot Help?
Oct 25, 2025Assessing published academic journal articles is a common task for evaluations of departments and individuals. Whilst it is sometimes supported by citation data, Large Language Models (LLMs) may give more useful indications of article quality. Evidence of this capability exists for two of the largest LLM families, ChatGPT and Gemini, and the medium sized LLM Gemma3 27b, but it is unclear whether smaller LLMs and reasoning models have similar abilities. This is important because larger models may be slow and impractical in some situations, and reasoning models may perform differently. Four relevant questions are addressed with Gemma3 variants, Llama4 Scout, Qwen3, Magistral Small and DeepSeek R1, on a dataset of 2,780 medical, health and life science papers in 6 fields, with two different gold standards, one novel. The results suggest that smaller (open weights) and reasoning LLMs have similar performance to ChatGPT 4o-mini and Gemini 2.0 Flash, but that 1b parameters may often, and 4b sometimes, be too few. Moreover, averaging scores from multiple identical queries seems to be a universally successful strategy, and few-shot prompts (four examples) tended to help but the evidence was equivocal. Reasoning models did not have a clear advantage. Overall, the results show, for the first time, that smaller LLMs >4b, including reasoning models, have a substantial capability to score journal articles for research quality, especially if score averaging is used.
Can Smaller Large Language Models Evaluate Research Quality?
Aug 10, 2025
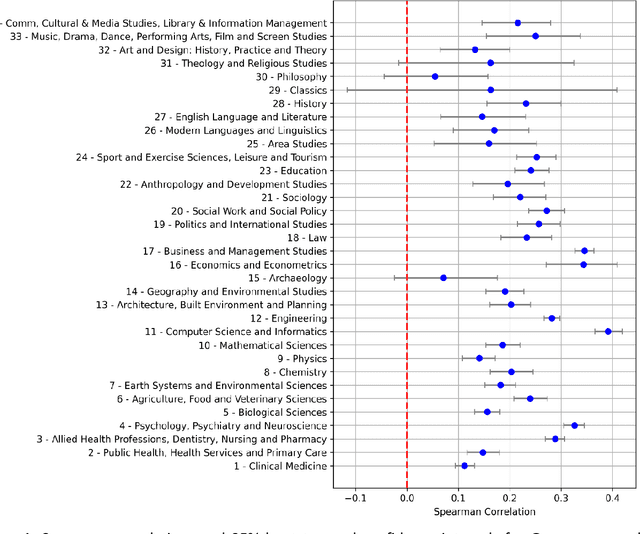
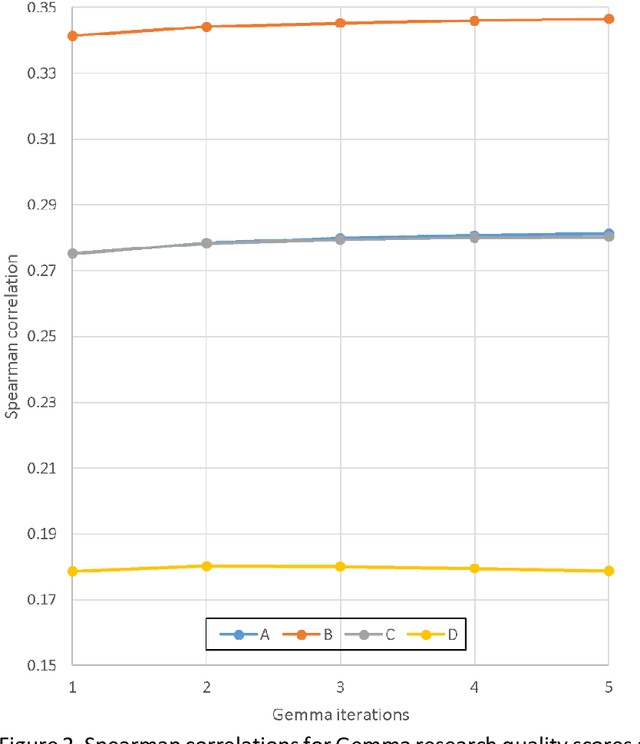

Although both Google Gemini (1.5 Flash) and ChatGPT (4o and 4o-mini) give research quality evaluation scores that correlate positively with expert scores in nearly all fields, and more strongly that citations in most, it is not known whether this is true for smaller Large Language Models (LLMs). In response, this article assesses Google's Gemma-3-27b-it, a downloadable LLM (60Gb). The results for 104,187 articles show that Gemma-3-27b-it scores correlate positively with an expert research quality score proxy for all 34 Units of Assessment (broad fields) from the UK Research Excellence Framework 2021. The Gemma-3-27b-it correlations have 83.8% of the strength of ChatGPT 4o and 94.7% of the strength of ChatGPT 4o-mini correlations. Differently from the two larger LLMs, the Gemma-3-27b-it correlations do not increase substantially when the scores are averaged across five repetitions, its scores tend to be lower, and its reports are relatively uniform in style. Overall, the results show that research quality score estimation can be conducted by offline LLMs, so this capability is not an emergent property of the largest LLMs. Moreover, score improvement through repetition is not a universal feature of LLMs. In conclusion, although the largest LLMs still have the highest research evaluation score estimation capability, smaller ones can also be used for this task, and this can be helpful for cost saving or when secure offline processing is needed.
Evaluating the Predictive Capacity of ChatGPT for Academic Peer Review Outcomes Across Multiple Platforms
Nov 14, 2024



While previous studies have demonstrated that Large Language Models (LLMs) can predict peer review outcomes to some extent, this paper builds on that by introducing two new contexts and employing a more robust method - averaging multiple ChatGPT scores. The findings that averaging 30 ChatGPT predictions, based on reviewer guidelines and using only the submitted titles and abstracts, failed to predict peer review outcomes for F1000Research (Spearman's rho=0.00). However, it produced mostly weak positive correlations with the quality dimensions of SciPost Physics (rho=0.25 for validity, rho=0.25 for originality, rho=0.20 for significance, and rho = 0.08 for clarity) and a moderate positive correlation for papers from the International Conference on Learning Representations (ICLR) (rho=0.38). Including the full text of articles significantly increased the correlation for ICLR (rho=0.46) and slightly improved it for F1000Research (rho=0.09), while it had variable effects on the four quality dimension correlations for SciPost LaTeX files. The use of chain-of-thought system prompts slightly increased the correlation for F1000Research (rho=0.10), marginally reduced it for ICLR (rho=0.37), and further decreased it for SciPost Physics (rho=0.16 for validity, rho=0.18 for originality, rho=0.18 for significance, and rho=0.05 for clarity). Overall, the results suggest that in some contexts, ChatGPT can produce weak pre-publication quality assessments. However, the effectiveness of these assessments and the optimal strategies for employing them vary considerably across different platforms, journals, and conferences. Additionally, the most suitable inputs for ChatGPT appear to differ depending on the platform.
Evaluating the quality of published medical research with ChatGPT
Nov 04, 2024



Evaluating the quality of published research is time-consuming but important for departmental evaluations, appointments, and promotions. Previous research has shown that ChatGPT can score articles for research quality, with the results correlating positively with an indicator of quality in all fields except Clinical Medicine. This article investigates this anomaly with the largest dataset yet and a more detailed analysis. The results showed that ChatGPT 4o-mini scores for articles submitted to the UK's Research Excellence Framework (REF) 2021 Unit of Assessment (UoA) 1 Clinical Medicine correlated positively (r=0.134, n=9872) with departmental mean REF scores, against a theoretical maximum correlation of r=0.226 (due to the departmental averaging involved). At the departmental level, mean ChatGPT scores correlated more strongly with departmental mean REF scores (r=0.395, n=31). For the 100 journals with the most articles in UoA 1, their mean ChatGPT score correlated strongly with their REF score (r=0.495) but negatively with their citation rate (r=-0.148). Journal and departmental anomalies in these results point to ChatGPT being ineffective at assessing the quality of research in prestigious medical journals or research directly affecting human health, or both. Nevertheless, the results give evidence of ChatGPT's ability to assess research quality overall for Clinical Medicine, so now there is evidence of its ability in all academic fields.
Assessing the societal influence of academic research with ChatGPT: Impact case study evaluations
Oct 25, 2024



Academics and departments are sometimes judged by how their research has benefitted society. For example, the UK Research Excellence Framework (REF) assesses Impact Case Studies (ICS), which are five-page evidence-based claims of societal impacts. This study investigates whether ChatGPT can evaluate societal impact claims and therefore potentially support expert human assessors. For this, various parts of 6,220 public ICS from REF2021 were fed to ChatGPT 4o-mini along with the REF2021 evaluation guidelines, comparing the results with published departmental average ICS scores. The results suggest that the optimal strategy for high correlations with expert scores is to input the title and summary of an ICS but not the remaining text, and to modify the original REF guidelines to encourage a stricter evaluation. The scores generated by this approach correlated positively with departmental average scores in all 34 Units of Assessment (UoAs), with values between 0.18 (Economics and Econometrics) and 0.56 (Psychology, Psychiatry and Neuroscience). At the departmental level, the corresponding correlations were higher, reaching 0.71 for Sport and Exercise Sciences, Leisure and Tourism. Thus, ChatGPT-based ICS evaluations are simple and viable to support or cross-check expert judgments, although their value varies substantially between fields.
Evaluating Research Quality with Large Language Models: An Analysis of ChatGPT's Effectiveness with Different Settings and Inputs
Aug 13, 2024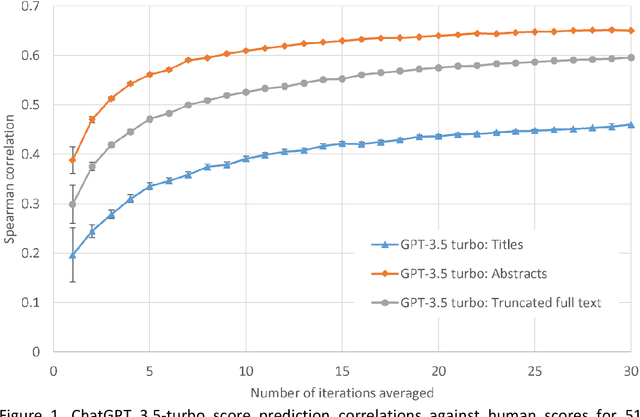
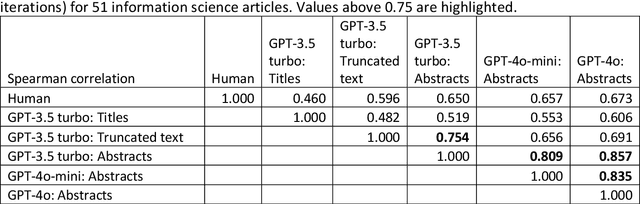

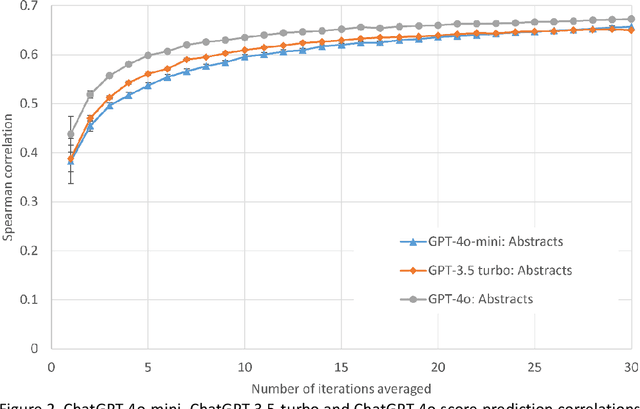
Evaluating the quality of academic journal articles is a time consuming but critical task for national research evaluation exercises, appointments and promotion. It is therefore important to investigate whether Large Language Models (LLMs) can play a role in this process. This article assesses which ChatGPT inputs (full text without tables, figures and references; title and abstract; title only) produce better quality score estimates, and the extent to which scores are affected by ChatGPT models and system prompts. The results show that the optimal input is the article title and abstract, with average ChatGPT scores based on these (30 iterations on a dataset of 51 papers) correlating at 0.67 with human scores, the highest ever reported. ChatGPT 4o is slightly better than 3.5-turbo (0.66), and 4o-mini (0.66). The results suggest that article full texts might confuse LLM research quality evaluations, even though complex system instructions for the task are more effective than simple ones. Thus, whilst abstracts contain insufficient information for a thorough assessment of rigour, they may contain strong pointers about originality and significance. Finally, linear regression can be used to convert the model scores into the human scale scores, which is 31% more accurate than guessing.
Can ChatGPT evaluate research quality?
Feb 08, 2024
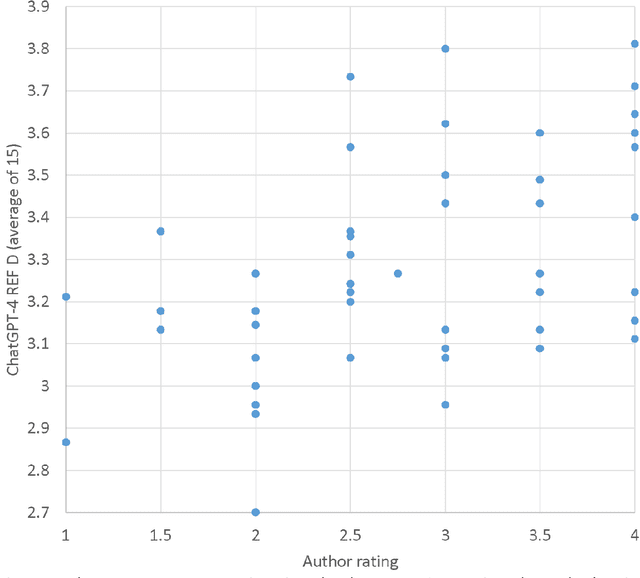
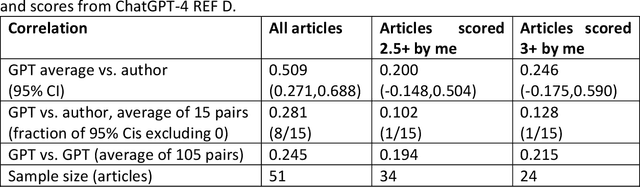
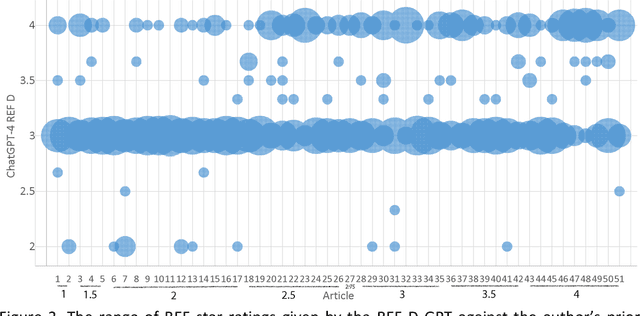
Purpose: Assess whether ChatGPT 4.0 is accurate enough to perform research evaluations on journal articles to automate this time-consuming task. Design/methodology/approach: Test the extent to which ChatGPT-4 can assess the quality of journal articles using a case study of the published scoring guidelines of the UK Research Excellence Framework (REF) 2021 to create a research evaluation ChatGPT. This was applied to 51 of my own articles and compared against my own quality judgements. Findings: ChatGPT-4 can produce plausible document summaries and quality evaluation rationales that match the REF criteria. Its overall scores have weak correlations with my self-evaluation scores of the same documents (averaging r=0.281 over 15 iterations, with 8 being statistically significantly different from 0). In contrast, the average scores from the 15 iterations produced a statistically significant positive correlation of 0.509. Thus, averaging scores from multiple ChatGPT-4 rounds seems more effective than individual scores. The positive correlation may be due to ChatGPT being able to extract the author's significance, rigour, and originality claims from inside each paper. If my weakest articles are removed, then the correlation with average scores (r=0.200) falls below statistical significance, suggesting that ChatGPT struggles to make fine-grained evaluations. Research limitations: The data is self-evaluations of a convenience sample of articles from one academic in one field. Practical implications: Overall, ChatGPT does not yet seem to be accurate enough to be trusted for any formal or informal research quality evaluation tasks. Research evaluators, including journal editors, should therefore take steps to control its use. Originality/value: This is the first published attempt at post-publication expert review accuracy testing for ChatGPT.
Can REF output quality scores be assigned by AI? Experimental evidence
Dec 11, 2022This document describes strategies for using Artificial Intelligence (AI) to predict some journal article scores in future research assessment exercises. Five strategies have been assessed.
Predicting article quality scores with machine learning: The UK Research Excellence Framework
Dec 11, 2022National research evaluation initiatives and incentive schemes have previously chosen between simplistic quantitative indicators and time-consuming peer review, sometimes supported by bibliometrics. Here we assess whether artificial intelligence (AI) could provide a third alternative, estimating article quality using more multiple bibliometric and metadata inputs. We investigated this using provisional three-level REF2021 peer review scores for 84,966 articles submitted to the UK Research Excellence Framework 2021, matching a Scopus record 2014-18 and with a substantial abstract. We found that accuracy is highest in the medical and physical sciences Units of Assessment (UoAs) and economics, reaching 42% above the baseline (72% overall) in the best case. This is based on 1000 bibliometric inputs and half of the articles used for training in each UoA. Prediction accuracies above the baseline for the social science, mathematics, engineering, arts, and humanities UoAs were much lower or close to zero. The Random Forest Classifier (standard or ordinal) and Extreme Gradient Boosting Classifier algorithms performed best from the 32 tested. Accuracy was lower if UoAs were merged or replaced by Scopus broad categories. We increased accuracy with an active learning strategy and by selecting articles with higher prediction probabilities, as estimated by the algorithms, but this substantially reduced the number of scores predicted.