 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorical Foundations of Gradient-Based Learning
Mar 02, 2021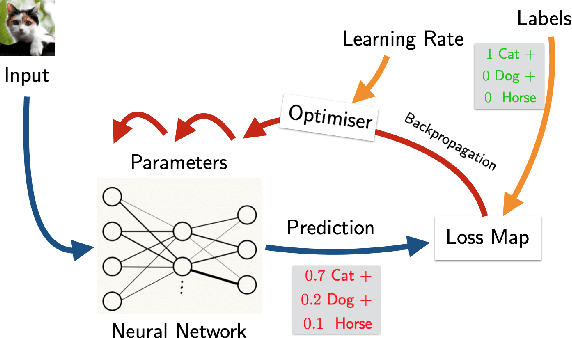
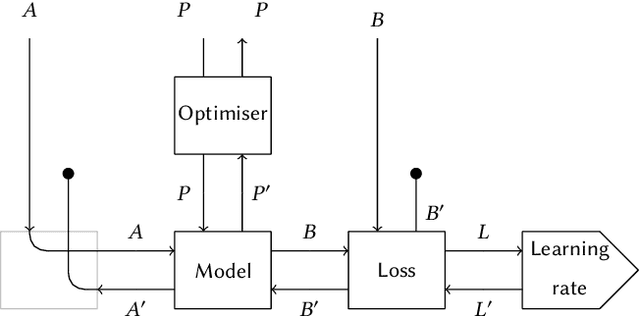
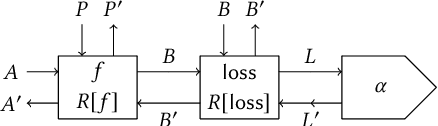
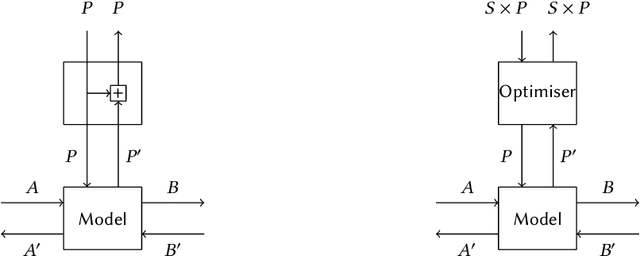
We propose a categorical foundation of gradient-based machine learning algorithms in terms of lenses, parametrised maps, and reverse derivative categories. This foundation provides a powerful explanatory and unifying framework: it encompasses a variety of gradient descent algorithms such as ADAM, AdaGrad, and Nesterov momentum, as well as a variety of loss functions such as as MSE and Softmax cross-entropy, shedding new light on their similarities and differences. Our approach also generalises beyond neural networks (modelled in categories of smooth maps), accounting for other structures relevant to gradient-based learning such as boolean circuits. Finally, we also develop a novel implementation of gradient-based learning in Python, informed by the principles introduced by our framework.