 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Prototypical Ensembles Improve Robustness to Subpopulation Shift
May 29, 2025The subpopulationtion shift, characterized by a disparity in subpopulation distributibetween theween the training and target datasets, can significantly degrade the performance of machine learning models. Current solutions to subpopulation shift involve modifying empirical risk minimization with re-weighting strategies to improve generalization. This strategy relies on assumptions about the number and nature of subpopulations and annotations on group membership, which are unavailable for many real-world datasets. Instead, we propose using an ensemble of diverse classifiers to adaptively capture risk associated with subpopulations. Given a feature extractor network, we replace its standard linear classification layer with a mixture of prototypical classifiers, where each member is trained to classify the data while focusing on different features and samples from other members. In empirical evaluation on nine real-world datasets, covering diverse domains and kinds of subpopulation shift, our method of Diverse Prototypical Ensembles (DPEs) often outperforms the prior state-of-the-art in worst-group accuracy. The code is available at https://github.com/minhto2802/dpe4subpop
FACT: Foundation Model for Assessing Cancer Tissue Margins with Mass Spectrometry
Apr 15, 2025Purpose: Accurately classifying tissue margins during cancer surgeries is crucial for ensuring complete tumor removal. Rapid Evaporative Ionization Mass Spectrometry (REIMS), a tool for real-time intraoperative margin assessment, generates spectra that require machine learning models to support clinical decision-making. However, the scarcity of labeled data in surgical contexts presents a significant challenge. This study is the first to develop a foundation model tailored specifically for REIMS data, addressing this limitation and advancing real-time surgical margin assessment. Methods: We propose FACT, a Foundation model for Assessing Cancer Tissue margins. FACT is an adaptation of a foundation model originally designed for text-audio association, pretrained using our proposed supervised contrastive approach based on triplet loss. An ablation study is performed to compare our proposed model against other models and pretraining methods. Results: Our proposed model significantly improves the classification performance, achieving state-of-the-art performance with an AUROC of $82.4\% \pm 0.8$. The results demonstrate the advantage of our proposed pretraining method and selected backbone over the self-supervised and semi-supervised baselines and alternative models. Conclusion: Our findings demonstrate that foundation models, adapted and pretrained using our novel approach, can effectively classify REIMS data even with limited labeled examples. This highlights the viability of foundation models for enhancing real-time surgical margin assessment, particularly in data-scarce clinical environments.
TRUSWorthy: Toward Clinically Applicable Deep Learning for Confident Detection of Prostate Cancer in Micro-Ultrasound
Feb 20, 2025While deep learning methods have shown great promise in improving the effectiveness of prostate cancer (PCa) diagnosis by detecting suspicious lesions from trans-rectal ultrasound (TRUS), they must overcome multiple simultaneous challenges. There is high heterogeneity in tissue appearance, significant class imbalance in favor of benign examples, and scarcity in the number and quality of ground truth annotations available to train models. Failure to address even a single one of these problems can result in unacceptable clinical outcomes.We propose TRUSWorthy, a carefully designed, tuned, and integrated system for reliable PCa detection. Our pipeline integrates self-supervised learning, multiple-instance learning aggregation using transformers, random-undersampled boosting and ensembling: these address label scarcity, weak labels, class imbalance, and overconfidence, respectively. We train and rigorously evaluate our method using a large, multi-center dataset of micro-ultrasound data. Our method outperforms previous state-of-the-art deep learning methods in terms of accuracy and uncertainty calibration, with AUROC and balanced accuracy scores of 79.9% and 71.5%, respectively. On the top 20% of predictions with the highest confidence, we can achieve a balanced accuracy of up to 91%. The success of TRUSWorthy demonstrates the potential of integrated deep learning solutions to meet clinical needs in a highly challenging deployment setting, and is a significant step towards creating a trustworthy system for computer-assisted PCa diagnosis.
Cinepro: Robust Training of Foundation Models for Cancer Detection in Prostate Ultrasound Cineloops
Jan 21, 2025



Prostate cancer (PCa) detection using deep learning (DL) models has shown potential for enhancing real-time guidance during biopsies. However, prostate ultrasound images lack pixel-level cancer annotations, introducing label noise. Current approaches often focus on limited regions of interest (ROIs), disregarding anatomical context necessary for accurate diagnosis. Foundation models can overcome this limitation by analyzing entire images to capture global spatial relationships; however, they still encounter challenges stemming from the weak labels associated with coarse pathology annotations in ultrasound data. We introduce Cinepro, a novel framework that strengthens foundation models' ability to localize PCa in ultrasound cineloops. Cinepro adapts robust training by integrating the proportion of cancer tissue reported by pathology in a biopsy core into its loss function to address label noise, providing a more nuanced supervision. Additionally, it leverages temporal data across multiple frames to apply robust augmentations, enhancing the model's ability to learn stable cancer-related features. Cinepro demonstrates superior performance on a multi-center prostate ultrasound dataset, achieving an AUROC of 77.1% and a balanced accuracy of 83.8%, surpassing current benchmarks. These findings underscore Cinepro's promise in advancing foundation models for weakly labeled ultrasound data.
Calibrated Diverse Ensemble Entropy Minimization for Robust Test-Time Adaptation in Prostate Cancer Detection
Jul 17, 2024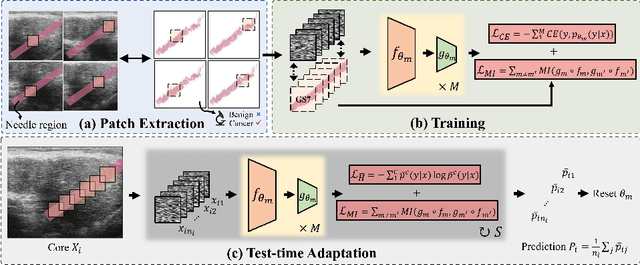
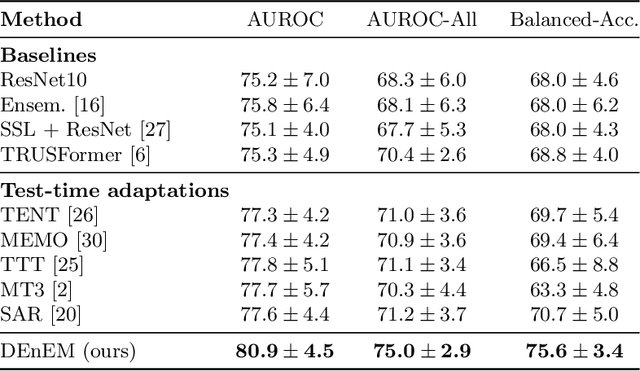

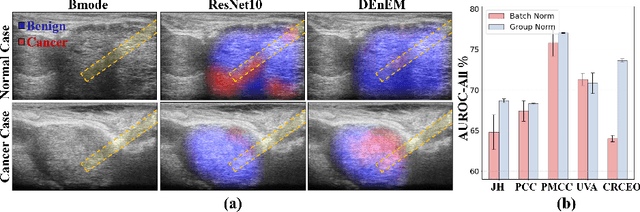
High resolution micro-ultrasound has demonstrated promise in real-time prostate cancer detection, with deep learning becoming a prominent tool for learning complex tissue properties reflected on ultrasound. However, a significant roadblock to real-world deployment remains, which prior works often overlook: model performance suffers when applied to data from different clinical centers due to variations in data distribution. This distribution shift significantly impacts the model's robustness, posing major challenge to clinical deployment. Domain adaptation and specifically its test-time adaption (TTA) variant offer a promising solution to address this challenge. In a setting designed to reflect real-world conditions, we compare existing methods to state-of-the-art TTA approaches adopted for cancer detection, demonstrating the lack of robustness to distribution shifts in the former. We then propose Diverse Ensemble Entropy Minimization (DEnEM), questioning the effectiveness of current TTA methods on ultrasound data. We show that these methods, although outperforming baselines, are suboptimal due to relying on neural networks output probabilities, which could be uncalibrated, or relying on data augmentation, which is not straightforward to define on ultrasound data. Our results show a significant improvement of $5\%$ to $7\%$ in AUROC over the existing methods and $3\%$ to $5\%$ over TTA methods, demonstrating the advantage of DEnEM in addressing distribution shift. \keywords{Ultrasound Imaging \and Prostate Cancer \and Computer-aided Diagnosis \and Distribution Shift Robustness \and Test-time Adaptation.}
Benchmarking Image Transformers for Prostate Cancer Detection from Ultrasound Data
Mar 27, 2024PURPOSE: Deep learning methods for classifying prostate cancer (PCa) in ultrasound images typically employ convolutional networks (CNNs) to detect cancer in small regions of interest (ROI) along a needle trace region. However, this approach suffers from weak labelling, since the ground-truth histopathology labels do not describe the properties of individual ROIs. Recently, multi-scale approaches have sought to mitigate this issue by combining the context awareness of transformers with a CNN feature extractor to detect cancer from multiple ROIs using multiple-instance learning (MIL). In this work, we present a detailed study of several image transformer architectures for both ROI-scale and multi-scale classification, and a comparison of the performance of CNNs and transformers for ultrasound-based prostate cancer classification. We also design a novel multi-objective learning strategy that combines both ROI and core predictions to further mitigate label noise. METHODS: We evaluate 3 image transformers on ROI-scale cancer classification, then use the strongest model to tune a multi-scale classifier with MIL. We train our MIL models using our novel multi-objective learning strategy and compare our results to existing baselines. RESULTS: We find that for both ROI-scale and multi-scale PCa detection, image transformer backbones lag behind their CNN counterparts. This deficit in performance is even more noticeable for larger models. When using multi-objective learning, we can improve performance of MIL, with a 77.9% AUROC, a sensitivity of 75.9%, and a specificity of 66.3%. CONCLUSION: Convolutional networks are better suited for modelling sparse datasets of prostate ultrasounds, producing more robust features than transformers in PCa detection. Multi-scale methods remain the best architecture for this task, with multi-objective learning presenting an effective way to improve performance.
CLASS-M: Adaptive stain separation-based contrastive learning with pseudo-labeling for histopathological image classification
Jan 04, 2024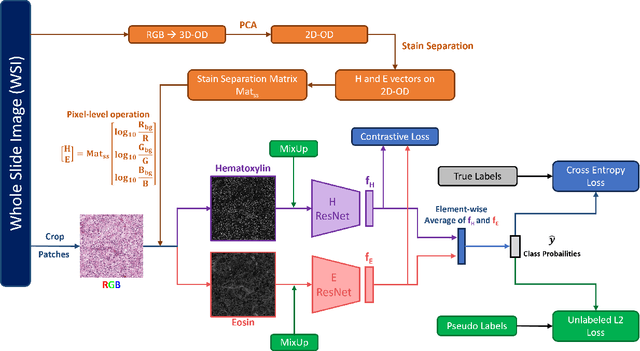
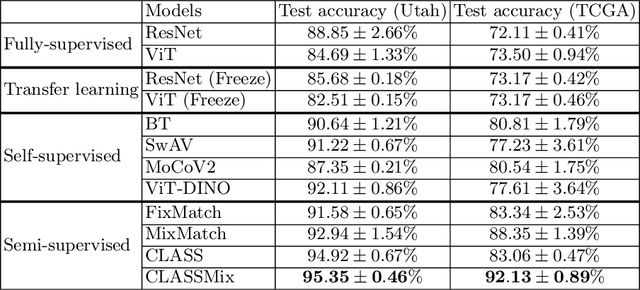
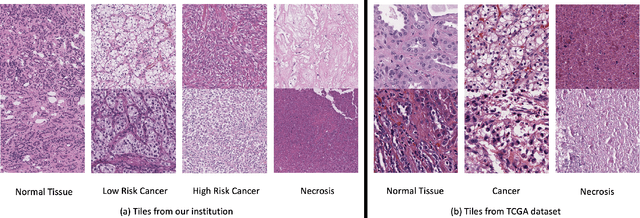
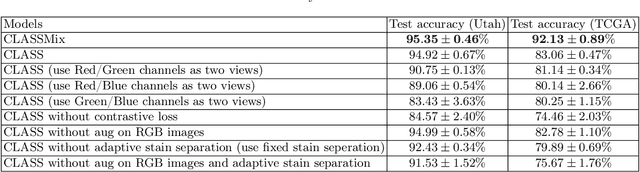
Histopathological image classification is an important task in medical image analysis. Recent approaches generally rely on weakly supervised learning due to the ease of acquiring case-level labels from pathology reports. However, patch-level classification is preferable in applications where only a limited number of cases are available or when local prediction accuracy is critical. On the other hand, acquiring extensive datasets with localized labels for training is not feasible. In this paper, we propose a semi-supervised patch-level histopathological image classification model, named CLASS-M, that does not require extensively labeled datasets. CLASS-M is formed by two main parts: a contrastive learning module that uses separated Hematoxylin and Eosin images generated through an adaptive stain separation process, and a module with pseudo-labels using MixUp. We compare our model with other state-of-the-art models on two clear cell renal cell carcinoma datasets. We demonstrate that our CLASS-M model has the best performance on both datasets. Our code is available at github.com/BzhangURU/Paper_CLASS-M/tree/main
Manifold DivideMix: A Semi-Supervised Contrastive Learning Framework for Severe Label Noise
Aug 13, 2023



Deep neural networks have proven to be highly effective when large amounts of data with clean labels are available. However, their performance degrades when training data contains noisy labels, leading to poor generalization on the test set. Real-world datasets contain noisy label samples that either have similar visual semantics to other classes (in-distribution) or have no semantic relevance to any class (out-of-distribution) in the dataset. Most state-of-the-art methods leverage ID labeled noisy samples as unlabeled data for semi-supervised learning, but OOD labeled noisy samples cannot be used in this way because they do not belong to any class within the dataset. Hence, in this paper, we propose incorporating the information from all the training data by leveraging the benefits of self-supervised training. Our method aims to extract a meaningful and generalizable embedding space for each sample regardless of its label. Then, we employ a simple yet effective K-nearest neighbor method to remove portions of out-of-distribution samples. By discarding these samples, we propose an iterative "Manifold DivideMix" algorithm to find clean and noisy samples, and train our model in a semi-supervised way. In addition, we propose "MixEMatch", a new algorithm for the semi-supervised step that involves mixup augmentation at the input and final hidden representations of the model. This will extract better representations by interpolating both in the input and manifold spaces. Extensive experiments on multiple synthetic-noise image benchmarks and real-world web-crawled datasets demonstrate the effectiveness of our proposed framework. Code is available at https://github.com/Fahim-F/ManifoldDivideMix.
TRUSformer: Improving Prostate Cancer Detection from Micro-Ultrasound Using Attention and Self-Supervision
Mar 03, 2023A large body of previous machine learning methods for ultrasound-based prostate cancer detection classify small regions of interest (ROIs) of ultrasound signals that lie within a larger needle trace corresponding to a prostate tissue biopsy (called biopsy core). These ROI-scale models suffer from weak labeling as histopathology results available for biopsy cores only approximate the distribution of cancer in the ROIs. ROI-scale models do not take advantage of contextual information that are normally considered by pathologists, i.e. they do not consider information about surrounding tissue and larger-scale trends when identifying cancer. We aim to improve cancer detection by taking a multi-scale, i.e. ROI-scale and biopsy core-scale, approach. Methods: Our multi-scale approach combines (i) an "ROI-scale" model trained using self-supervised learning to extract features from small ROIs and (ii) a "core-scale" transformer model that processes a collection of extracted features from multiple ROIs in the needle trace region to predict the tissue type of the corresponding core. Attention maps, as a byproduct, allow us to localize cancer at the ROI scale. We analyze this method using a dataset of micro-ultrasound acquired from 578 patients who underwent prostate biopsy, and compare our model to baseline models and other large-scale studies in the literature. Results and Conclusions: Our model shows consistent and substantial performance improvements compared to ROI-scale-only models. It achieves 80.3% AUROC, a statistically significant improvement over ROI-scale classification. We also compare our method to large studies on prostate cancer detection, using other imaging modalities. Our code is publicly available at www.github.com/med-i-lab/TRUSFormer
Self-Supervised Learning with Limited Labeled Data for Prostate Cancer Detection in High Frequency Ultrasound
Nov 01, 2022Deep learning-based analysis of high-frequency, high-resolution micro-ultrasound data shows great promise for prostate cancer detection. Previous approaches to analysis of ultrasound data largely follow a supervised learning paradigm. Ground truth labels for ultrasound images used for training deep networks often include coarse annotations generated from the histopathological analysis of tissue samples obtained via biopsy. This creates inherent limitations on the availability and quality of labeled data, posing major challenges to the success of supervised learning methods. On the other hand, unlabeled prostate ultrasound data are more abundant. In this work, we successfully apply self-supervised representation learning to micro-ultrasound data. Using ultrasound data from 1028 biopsy cores of 391 subjects obtained in two clinical centres, we demonstrate that feature representations learnt with this method can be used to classify cancer from non-cancer tissue, obtaining an AUROC score of 91% on an independent test set. To the best of our knowledge, this is the first successful end-to-end self-supervised learning approach for prostate cancer detection using ultrasound data. Our method outperforms baseline supervised learning approaches, generalizes well between different data centers, and scale well in performance as more unlabeled data are added, making it a promising approach for future research using large volumes of unlabeled data.