 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset and Benchmarks for Atrial Fibrillation Detection from Electrocardiograms of Intensive Care Unit Patients
Dec 19, 2025Objective: Atrial fibrillation (AF) is the most common cardiac arrhythmia experienced by intensive care unit (ICU) patients and can cause adverse health effects. In this study, we publish a labelled ICU dataset and benchmarks for AF detection. Methods: We compared machine learning models across three data-driven artificial intelligence (AI) approaches: feature-based classifiers, deep learning (DL), and ECG foundation models (FMs). This comparison addresses a critical gap in the literature and aims to pinpoint which AI approach is best for accurate AF detection. Electrocardiograms (ECGs) from a Canadian ICU and the 2021 PhysioNet/Computing in Cardiology Challenge were used to conduct the experiments. Multiple training configurations were tested, ranging from zero-shot inference to transfer learning. Results: On average and across both datasets, ECG FMs performed best, followed by DL, then feature-based classifiers. The model that achieved the top F1 score on our ICU test set was ECG-FM through a transfer learning strategy (F1=0.89). Conclusion: This study demonstrates promising potential for using AI to build an automatic patient monitoring system. Significance: By publishing our labelled ICU dataset (LinkToBeAdded) and performance benchmarks, this work enables the research community to continue advancing the state-of-the-art in AF detection in the ICU.
ProstNFound+: A Prospective Study using Medical Foundation Models for Prostate Cancer Detection
Oct 30, 2025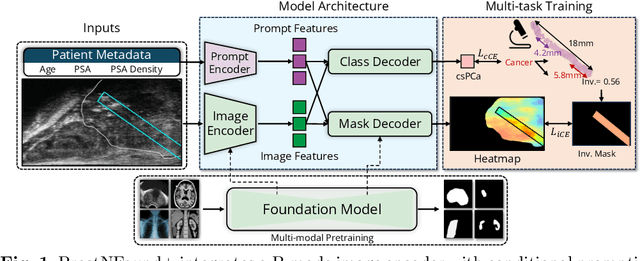
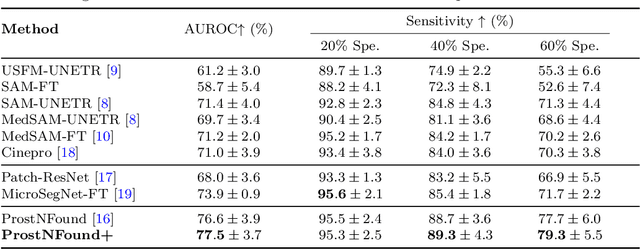
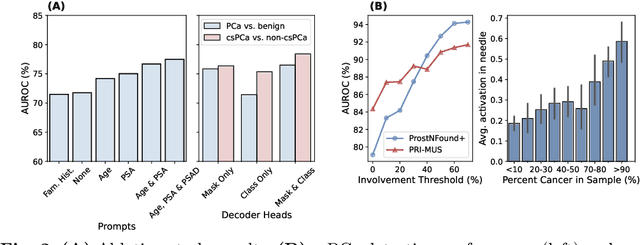
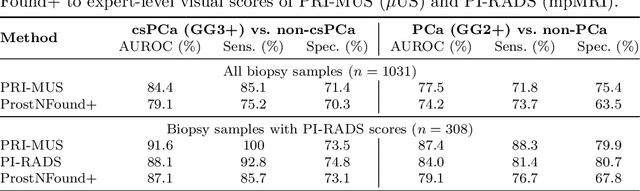
Purpose: Medical foundation models (FMs) offer a path to build high-performance diagnostic systems. However, their application to prostate cancer (PCa) detection from micro-ultrasound ({\mu}US) remains untested in clinical settings. We present ProstNFound+, an adaptation of FMs for PCa detection from {\mu}US, along with its first prospective validation. Methods: ProstNFound+ incorporates a medical FM, adapter tuning, and a custom prompt encoder that embeds PCa-specific clinical biomarkers. The model generates a cancer heatmap and a risk score for clinically significant PCa. Following training on multi-center retrospective data, the model is prospectively evaluated on data acquired five years later from a new clinical site. Model predictions are benchmarked against standard clinical scoring protocols (PRI-MUS and PI-RADS). Results: ProstNFound+ shows strong generalization to the prospective data, with no performance degradation compared to retrospective evaluation. It aligns closely with clinical scores and produces interpretable heatmaps consistent with biopsy-confirmed lesions. Conclusion: The results highlight its potential for clinical deployment, offering a scalable and interpretable alternative to expert-driven protocols.
Touching the tumor boundary: A pilot study on ultrasound based virtual fixtures for breast-conserving surgery
Oct 01, 2025Purpose: Delineating tumor boundaries during breast-conserving surgery is challenging as tumors are often highly mobile, non-palpable, and have irregularly shaped borders. To address these challenges, we introduce a cooperative robotic guidance system that applies haptic feedback for tumor localization. In this pilot study, we aim to assess if and how this system can be successfully integrated into breast cancer care. Methods: A small haptic robot is retrofitted with an electrocautery blade to operate as a cooperatively controlled surgical tool. Ultrasound and electromagnetic navigation are used to identify the tumor boundaries and position. A forbidden region virtual fixture is imposed when the surgical tool collides with the tumor boundary. We conducted a study where users were asked to resect tumors from breast simulants both with and without the haptic guidance. We then assess the results of these simulated resections both qualitatively and quantitatively. Results: Virtual fixture guidance is shown to improve resection margins. On average, users find the task to be less mentally demanding, frustrating, and effort intensive when haptic feedback is available. We also discovered some unanticipated impacts on surgical workflow that will guide design adjustments and training protocol moving forward. Conclusion: Our results suggest that virtual fixtures can help localize tumor boundaries in simulated breast-conserving surgery. Future work will include an extensive user study to further validate these results and fine-tune our guidance system.
DualTrack: Sensorless 3D Ultrasound needs Local and Global Context
Sep 11, 2025Three-dimensional ultrasound (US) offers many clinical advantages over conventional 2D imaging, yet its widespread adoption is limited by the cost and complexity of traditional 3D systems. Sensorless 3D US, which uses deep learning to estimate a 3D probe trajectory from a sequence of 2D US images, is a promising alternative. Local features, such as speckle patterns, can help predict frame-to-frame motion, while global features, such as coarse shapes and anatomical structures, can situate the scan relative to anatomy and help predict its general shape. In prior approaches, global features are either ignored or tightly coupled with local feature extraction, restricting the ability to robustly model these two complementary aspects. We propose DualTrack, a novel dual-encoder architecture that leverages decoupled local and global encoders specialized for their respective scales of feature extraction. The local encoder uses dense spatiotemporal convolutions to capture fine-grained features, while the global encoder utilizes an image backbone (e.g., a 2D CNN or foundation model) and temporal attention layers to embed high-level anatomical features and long-range dependencies. A lightweight fusion module then combines these features to estimate the trajectory. Experimental results on a large public benchmark show that DualTrack achieves state-of-the-art accuracy and globally consistent 3D reconstructions, outperforming previous methods and yielding an average reconstruction error below 5 mm.
Domain Knowledge is Power: Leveraging Physiological Priors for Self Supervised Representation Learning in Electrocardiography
Sep 09, 2025Objective: Electrocardiograms (ECGs) play a crucial role in diagnosing heart conditions; however, the effectiveness of artificial intelligence (AI)-based ECG analysis is often hindered by the limited availability of labeled data. Self-supervised learning (SSL) can address this by leveraging large-scale unlabeled data. We introduce PhysioCLR (Physiology-aware Contrastive Learning Representation for ECG), a physiology-aware contrastive learning framework that incorporates domain-specific priors to enhance the generalizability and clinical relevance of ECG-based arrhythmia classification. Methods: During pretraining, PhysioCLR learns to bring together embeddings of samples that share similar clinically relevant features while pushing apart those that are dissimilar. Unlike existing methods, our method integrates ECG physiological similarity cues into contrastive learning, promoting the learning of clinically meaningful representations. Additionally, we introduce ECG- specific augmentations that preserve the ECG category post augmentation and propose a hybrid loss function to further refine the quality of learned representations. Results: We evaluate PhysioCLR on two public ECG datasets, Chapman and Georgia, for multilabel ECG diagnoses, as well as a private ICU dataset labeled for binary classification. Across the Chapman, Georgia, and private cohorts, PhysioCLR boosts the mean AUROC by 12% relative to the strongest baseline, underscoring its robust cross-dataset generalization. Conclusion: By embedding physiological knowledge into contrastive learning, PhysioCLR enables the model to learn clinically meaningful and transferable ECG eatures. Significance: PhysioCLR demonstrates the potential of physiology-informed SSL to offer a promising path toward more effective and label-efficient ECG diagnostics.
Diverse Prototypical Ensembles Improve Robustness to Subpopulation Shift
May 29, 2025The subpopulationtion shift, characterized by a disparity in subpopulation distributibetween theween the training and target datasets, can significantly degrade the performance of machine learning models. Current solutions to subpopulation shift involve modifying empirical risk minimization with re-weighting strategies to improve generalization. This strategy relies on assumptions about the number and nature of subpopulations and annotations on group membership, which are unavailable for many real-world datasets. Instead, we propose using an ensemble of diverse classifiers to adaptively capture risk associated with subpopulations. Given a feature extractor network, we replace its standard linear classification layer with a mixture of prototypical classifiers, where each member is trained to classify the data while focusing on different features and samples from other members. In empirical evaluation on nine real-world datasets, covering diverse domains and kinds of subpopulation shift, our method of Diverse Prototypical Ensembles (DPEs) often outperforms the prior state-of-the-art in worst-group accuracy. The code is available at https://github.com/minhto2802/dpe4subpop
FACT: Foundation Model for Assessing Cancer Tissue Margins with Mass Spectrometry
Apr 15, 2025Purpose: Accurately classifying tissue margins during cancer surgeries is crucial for ensuring complete tumor removal. Rapid Evaporative Ionization Mass Spectrometry (REIMS), a tool for real-time intraoperative margin assessment, generates spectra that require machine learning models to support clinical decision-making. However, the scarcity of labeled data in surgical contexts presents a significant challenge. This study is the first to develop a foundation model tailored specifically for REIMS data, addressing this limitation and advancing real-time surgical margin assessment. Methods: We propose FACT, a Foundation model for Assessing Cancer Tissue margins. FACT is an adaptation of a foundation model originally designed for text-audio association, pretrained using our proposed supervised contrastive approach based on triplet loss. An ablation study is performed to compare our proposed model against other models and pretraining methods. Results: Our proposed model significantly improves the classification performance, achieving state-of-the-art performance with an AUROC of $82.4\% \pm 0.8$. The results demonstrate the advantage of our proposed pretraining method and selected backbone over the self-supervised and semi-supervised baselines and alternative models. Conclusion: Our findings demonstrate that foundation models, adapted and pretrained using our novel approach, can effectively classify REIMS data even with limited labeled examples. This highlights the viability of foundation models for enhancing real-time surgical margin assessment, particularly in data-scarce clinical environments.
TRUSWorthy: Toward Clinically Applicable Deep Learning for Confident Detection of Prostate Cancer in Micro-Ultrasound
Feb 20, 2025While deep learning methods have shown great promise in improving the effectiveness of prostate cancer (PCa) diagnosis by detecting suspicious lesions from trans-rectal ultrasound (TRUS), they must overcome multiple simultaneous challenges. There is high heterogeneity in tissue appearance, significant class imbalance in favor of benign examples, and scarcity in the number and quality of ground truth annotations available to train models. Failure to address even a single one of these problems can result in unacceptable clinical outcomes.We propose TRUSWorthy, a carefully designed, tuned, and integrated system for reliable PCa detection. Our pipeline integrates self-supervised learning, multiple-instance learning aggregation using transformers, random-undersampled boosting and ensembling: these address label scarcity, weak labels, class imbalance, and overconfidence, respectively. We train and rigorously evaluate our method using a large, multi-center dataset of micro-ultrasound data. Our method outperforms previous state-of-the-art deep learning methods in terms of accuracy and uncertainty calibration, with AUROC and balanced accuracy scores of 79.9% and 71.5%, respectively. On the top 20% of predictions with the highest confidence, we can achieve a balanced accuracy of up to 91%. The success of TRUSWorthy demonstrates the potential of integrated deep learning solutions to meet clinical needs in a highly challenging deployment setting, and is a significant step towards creating a trustworthy system for computer-assisted PCa diagnosis.
Cinepro: Robust Training of Foundation Models for Cancer Detection in Prostate Ultrasound Cineloops
Jan 21, 2025



Prostate cancer (PCa) detection using deep learning (DL) models has shown potential for enhancing real-time guidance during biopsies. However, prostate ultrasound images lack pixel-level cancer annotations, introducing label noise. Current approaches often focus on limited regions of interest (ROIs), disregarding anatomical context necessary for accurate diagnosis. Foundation models can overcome this limitation by analyzing entire images to capture global spatial relationships; however, they still encounter challenges stemming from the weak labels associated with coarse pathology annotations in ultrasound data. We introduce Cinepro, a novel framework that strengthens foundation models' ability to localize PCa in ultrasound cineloops. Cinepro adapts robust training by integrating the proportion of cancer tissue reported by pathology in a biopsy core into its loss function to address label noise, providing a more nuanced supervision. Additionally, it leverages temporal data across multiple frames to apply robust augmentations, enhancing the model's ability to learn stable cancer-related features. Cinepro demonstrates superior performance on a multi-center prostate ultrasound dataset, achieving an AUROC of 77.1% and a balanced accuracy of 83.8%, surpassing current benchmarks. These findings underscore Cinepro's promise in advancing foundation models for weakly labeled ultrasound data.
Calibrated Diverse Ensemble Entropy Minimization for Robust Test-Time Adaptation in Prostate Cancer Detection
Jul 17, 2024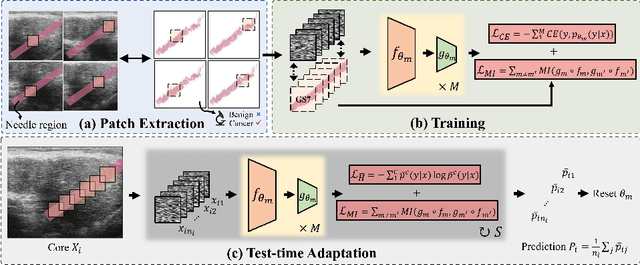
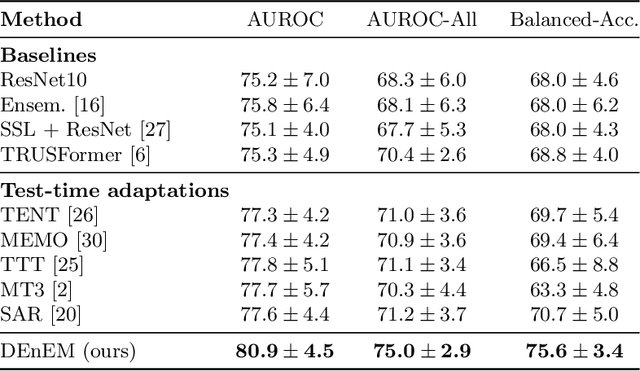

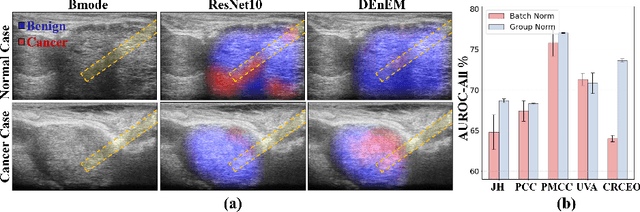
High resolution micro-ultrasound has demonstrated promise in real-time prostate cancer detection, with deep learning becoming a prominent tool for learning complex tissue properties reflected on ultrasound. However, a significant roadblock to real-world deployment remains, which prior works often overlook: model performance suffers when applied to data from different clinical centers due to variations in data distribution. This distribution shift significantly impacts the model's robustness, posing major challenge to clinical deployment. Domain adaptation and specifically its test-time adaption (TTA) variant offer a promising solution to address this challenge. In a setting designed to reflect real-world conditions, we compare existing methods to state-of-the-art TTA approaches adopted for cancer detection, demonstrating the lack of robustness to distribution shifts in the former. We then propose Diverse Ensemble Entropy Minimization (DEnEM), questioning the effectiveness of current TTA methods on ultrasound data. We show that these methods, although outperforming baselines, are suboptimal due to relying on neural networks output probabilities, which could be uncalibrated, or relying on data augmentation, which is not straightforward to define on ultrasound data. Our results show a significant improvement of $5\%$ to $7\%$ in AUROC over the existing methods and $3\%$ to $5\%$ over TTA methods, demonstrating the advantage of DEnEM in addressing distribution shift. \keywords{Ultrasound Imaging \and Prostate Cancer \and Computer-aided Diagnosis \and Distribution Shift Robustness \and Test-time Adaptation.}