 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Zero-Shot ACSA with Unified Meaning Representation in Chain-of-Thought Prompting
Dec 22, 2025



Aspect-Category Sentiment Analysis (ACSA) provides granular insights by identifying specific themes within reviews and their associated sentiment. While supervised learning approaches dominate this field, the scarcity and high cost of annotated data for new domains present significant barriers. We argue that leveraging large language models (LLMs) in a zero-shot setting is a practical alternative where resources for data annotation are limited. In this work, we propose a novel Chain-of-Thought (CoT) prompting technique that utilises an intermediate Unified Meaning Representation (UMR) to structure the reasoning process for the ACSA task. We evaluate this UMR-based approach against a standard CoT baseline across three models (Qwen3-4B, Qwen3-8B, and Gemini-2.5-Pro) and four diverse datasets. Our findings suggest that UMR effectiveness may be model-dependent. Whilst preliminary results indicate comparable performance for mid-sized models such as Qwen3-8B, these observations warrant further investigation, particularly regarding the potential applicability to smaller model architectures. Further research is required to establish the generalisability of these findings across different model scales.
TVS Sidekick: Challenges and Practical Insights from Deploying Large Language Models in the Enterprise
Sep 30, 2025Many enterprises are increasingly adopting Artificial Intelligence (AI) to make internal processes more competitive and efficient. In response to public concern and new regulations for the ethical and responsible use of AI, implementing AI governance frameworks could help to integrate AI within organisations and mitigate associated risks. However, the rapid technological advances and lack of shared ethical AI infrastructures creates barriers to their practical adoption in businesses. This paper presents a real-world AI application at TVS Supply Chain Solutions, reporting on the experience developing an AI assistant underpinned by large language models and the ethical, regulatory, and sociotechnical challenges in deployment for enterprise use.
Are You Sure You're Positive? Consolidating Chain-of-Thought Agents with Uncertainty Quantification for Aspect-Category Sentiment Analysis
Aug 24, 2025Aspect-category sentiment analysis provides granular insights by identifying specific themes within product reviews that are associated with particular opinions. Supervised learning approaches dominate the field. However, data is scarce and expensive to annotate for new domains. We argue that leveraging large language models in a zero-shot setting is beneficial where the time and resources required for dataset annotation are limited. Furthermore, annotation bias may lead to strong results using supervised methods but transfer poorly to new domains in contexts that lack annotations and demand reproducibility. In our work, we propose novel techniques that combine multiple chain-of-thought agents by leveraging large language models' token-level uncertainty scores. We experiment with the 3B and 70B+ parameter size variants of Llama and Qwen models, demonstrating how these approaches can fulfil practical needs and opening a discussion on how to gauge accuracy in label-scarce conditions.
* 18 pages, 10 figures, 3 tables, Proceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025)
Simple is not Enough: Document-level Text Simplification using Readability and Coherence
Dec 24, 2024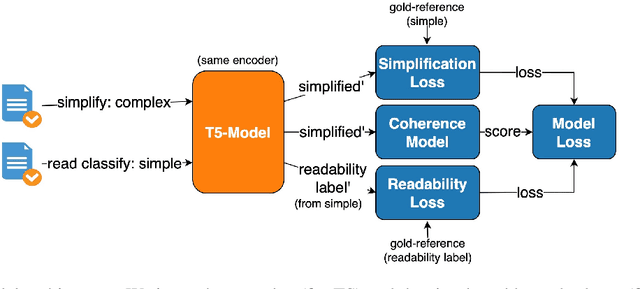

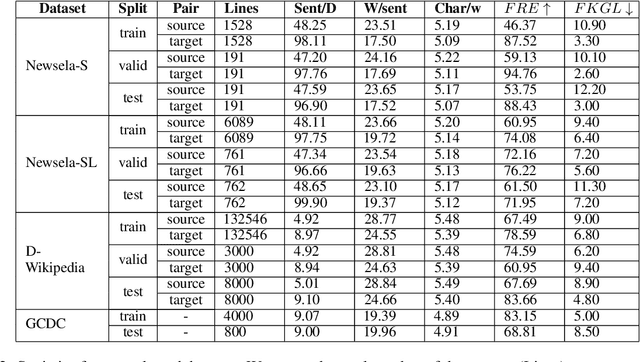
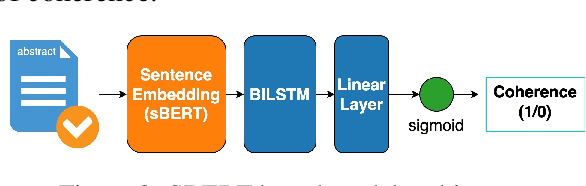
In this paper, we present the SimDoc system, a simplification model considering simplicity, readability, and discourse aspects, such as coherence. In the past decade, the progress of the Text Simplification (TS) field has been mostly shown at a sentence level, rather than considering paragraphs or documents, a setting from which most TS audiences would benefit. We propose a simplification system that is initially fine-tuned with professionally created corpora. Further, we include multiple objectives during training, considering simplicity, readability, and coherence altogether. Our contributions include the extension of professionally annotated simplification corpora by the association of existing annotations into (complex text, simple text, readability label) triples to benefit from readability during training. Also, we present a comparative analysis in which we evaluate our proposed models in a zero-shot, few-shot, and fine-tuning setting using document-level TS corpora, demonstrating novel methods for simplification. Finally, we show a detailed analysis of outputs, highlighting the difficulties of simplification at a document level.
Shifting NER into High Gear: The Auto-AdvER Approach
Dec 07, 2024This paper presents a case study on the development of Auto-AdvER, a specialised named entity recognition schema and dataset for text in the car advertisement genre. Developed with industry needs in mind, Auto-AdvER is designed to enhance text mining analytics in this domain and contributes a linguistically unique NER dataset. We present a schema consisting of three labels: "Condition", "Historic" and "Sales Options". We outline the guiding principles for annotation, describe the methodology for schema development, and show the results of an annotation study demonstrating inter-annotator agreement of 92% F1-Score. Furthermore, we compare the performance by using encoder-only models: BERT, DeBERTaV3 and decoder-only open and closed source Large Language Models (LLMs): Llama, Qwen, GPT-4 and Gemini. Our results show that the class of LLMs outperforms the smaller encoder-only models. However, the LLMs are costly and far from perfect for this task. We present this work as a stepping stone toward more fine-grained analysis and discuss Auto-AdvER's potential impact on advertisement analytics and customer insights, including applications such as the analysis of market dynamics and data-driven predictive maintenance. Our schema, as well as our associated findings, are suitable for both private and public entities considering named entity recognition in the automotive domain, or other specialist domains.
Overview of the BioLaySumm 2024 Shared Task on the Lay Summarization of Biomedical Research Articles
Aug 16, 2024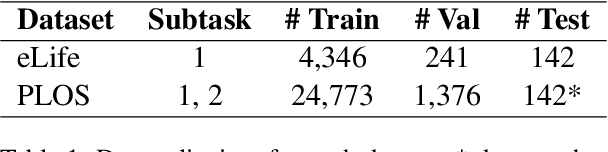
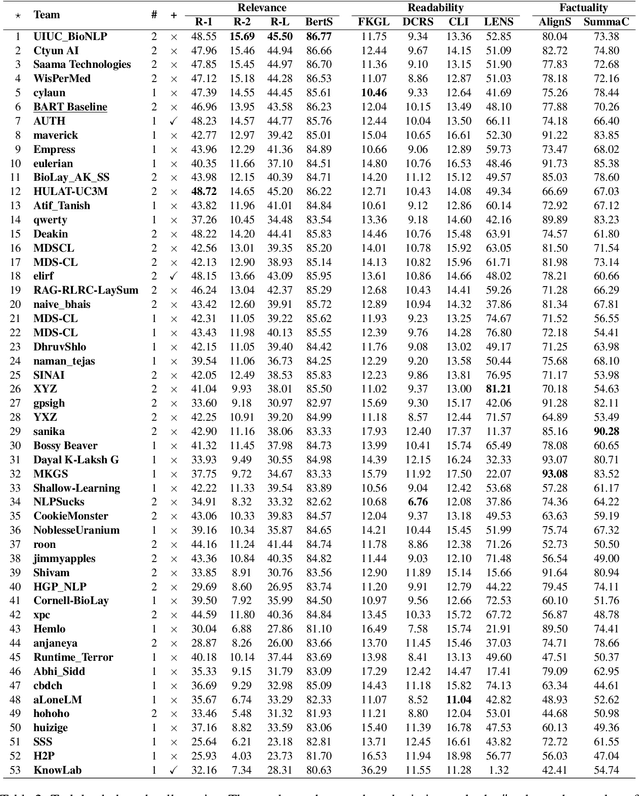
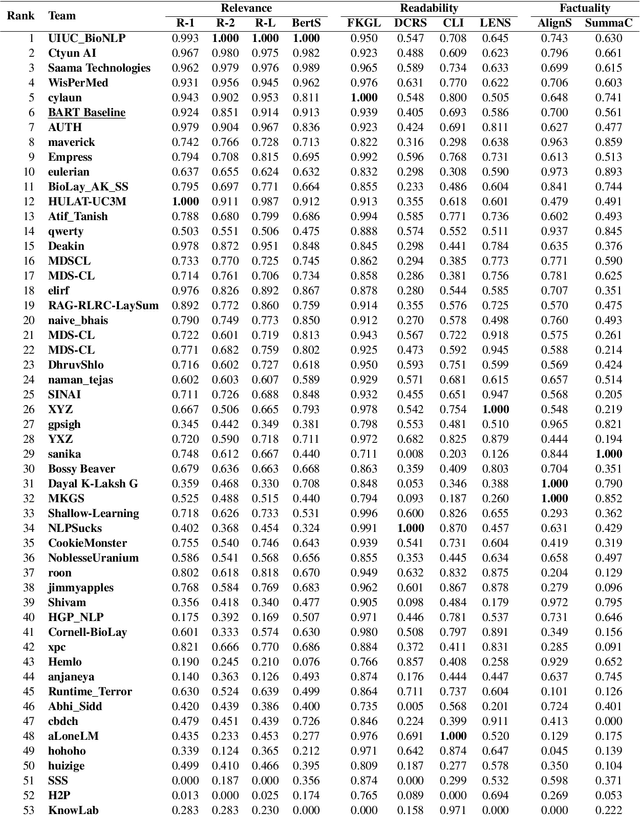
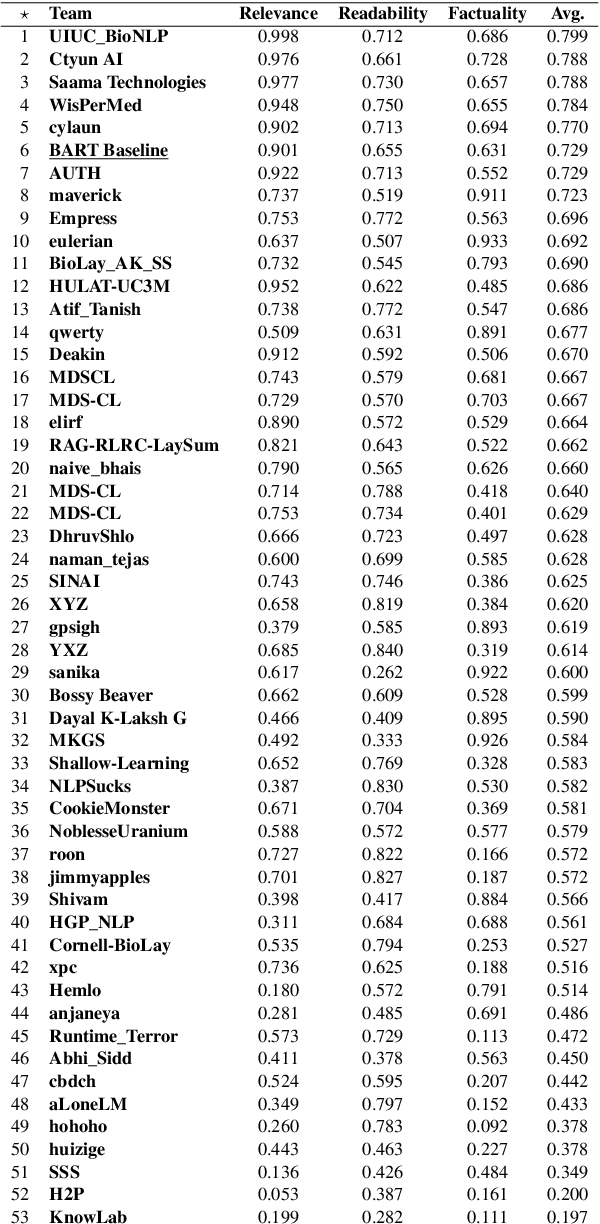
This paper presents the setup and results of the second edition of the BioLaySumm shared task on the Lay Summarisation of Biomedical Research Articles, hosted at the BioNLP Workshop at ACL 2024. In this task edition, we aim to build on the first edition's success by further increasing research interest in this important task and encouraging participants to explore novel approaches that will help advance the state-of-the-art. Encouragingly, we found research interest in the task to be high, with this edition of the task attracting a total of 53 participating teams, a significant increase in engagement from the previous edition. Overall, our results show that a broad range of innovative approaches were adopted by task participants, with a predictable shift towards the use of Large Language Models (LLMs).
BeeManc at the PLABA Track of TAC-2023: Investigating LLMs and Controllable Attributes for Improving Biomedical Text Readability
Aug 07, 2024



In this system report, we describe the models and methods we used for our participation in the PLABA2023 task on biomedical abstract simplification, part of the TAC 2023 tracks. The system outputs we submitted come from the following three categories: 1) domain fine-tuned T5-like models including Biomedical-T5 and Lay-SciFive; 2) fine-tuned BARTLarge model with controllable attributes (via tokens) BART-w-CTs; 3) ChatGPTprompting. We also present the work we carried out for this task on BioGPT finetuning. In the official automatic evaluation using SARI scores, BeeManc ranks 2nd among all teams and our model LaySciFive ranks 3rd among all 13 evaluated systems. In the official human evaluation, our model BART-w-CTs ranks 2nd on Sentence-Simplicity (score 92.84), 3rd on Term-Simplicity (score 82.33) among all 7 evaluated systems; It also produced a high score 91.57 on Fluency in comparison to the highest score 93.53. In the second round of submissions, our team using ChatGPT-prompting ranks the 2nd in several categories including simplified term accuracy score 92.26 and completeness score 96.58, and a very similar score on faithfulness score 95.3 to re-evaluated PLABA-base-1 (95.73) via human evaluations. Our codes, fine-tuned models, prompts, and data splits from the system development stage will be available at https://github.com/ HECTA-UoM/PLABA-MU
MultiLS: A Multi-task Lexical Simplification Framework
Feb 22, 2024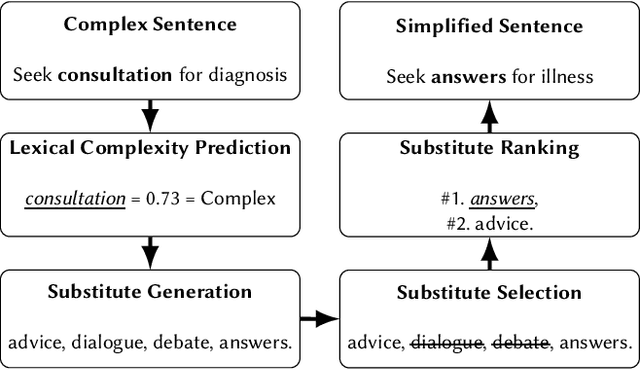
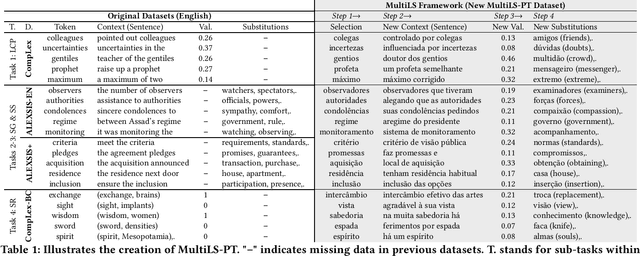

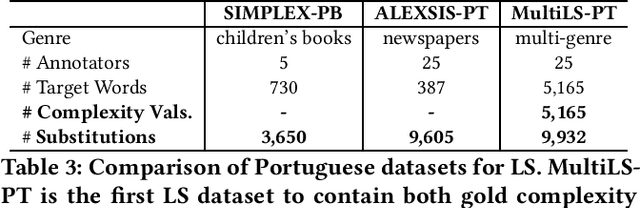
Lexical Simplification (LS) automatically replaces difficult to read words for easier alternatives while preserving a sentence's original meaning. LS is a precursor to Text Simplification with the aim of improving text accessibility to various target demographics, including children, second language learners, individuals with reading disabilities or low literacy. Several datasets exist for LS. These LS datasets specialize on one or two sub-tasks within the LS pipeline. However, as of this moment, no single LS dataset has been developed that covers all LS sub-tasks. We present MultiLS, the first LS framework that allows for the creation of a multi-task LS dataset. We also present MultiLS-PT, the first dataset to be created using the MultiLS framework. We demonstrate the potential of MultiLS-PT by carrying out all LS sub-tasks of (1). lexical complexity prediction (LCP), (2). substitute generation, and (3). substitute ranking for Portuguese. Model performances are reported, ranging from transformer-based models to more recent large language models (LLMs).
BLESS: Benchmarking Large Language Models on Sentence Simplification
Oct 24, 2023



We present BLESS, a comprehensive performance benchmark of the most recent state-of-the-art large language models (LLMs) on the task of text simplification (TS). We examine how well off-the-shelf LLMs can solve this challenging task, assessing a total of 44 models, differing in size, architecture, pre-training methods, and accessibility, on three test sets from different domains (Wikipedia, news, and medical) under a few-shot setting. Our analysis considers a suite of automatic metrics as well as a large-scale quantitative investigation into the types of common edit operations performed by the different models. Furthermore, we perform a manual qualitative analysis on a subset of model outputs to better gauge the quality of the generated simplifications. Our evaluation indicates that the best LLMs, despite not being trained on TS, perform comparably with state-of-the-art TS baselines. Additionally, we find that certain LLMs demonstrate a greater range and diversity of edit operations. Our performance benchmark will be available as a resource for the development of future TS methods and evaluation metrics.
Overview of the BioLaySumm 2023 Shared Task on Lay Summarization of Biomedical Research Articles
Sep 29, 2023



This paper presents the results of the shared task on Lay Summarisation of Biomedical Research Articles (BioLaySumm), hosted at the BioNLP Workshop at ACL 2023. The goal of this shared task is to develop abstractive summarisation models capable of generating "lay summaries" (i.e., summaries that are comprehensible to non-technical audiences) in both a controllable and non-controllable setting. There are two subtasks: 1) Lay Summarisation, where the goal is for participants to build models for lay summary generation only, given the full article text and the corresponding abstract as input; and 2) Readability-controlled Summarisation, where the goal is for participants to train models to generate both the technical abstract and the lay summary, given an article's main text as input. In addition to overall results, we report on the setup and insights from the BioLaySumm shared task, which attracted a total of 20 participating teams across both subtasks.
* Published at BioNLP@ACL2023