 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiLS: A Multi-task Lexical Simplification Framework
Paper and Code
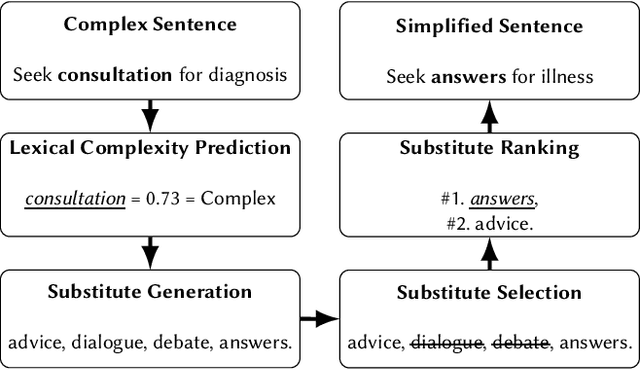
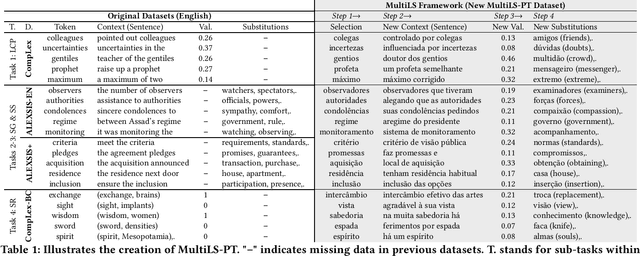

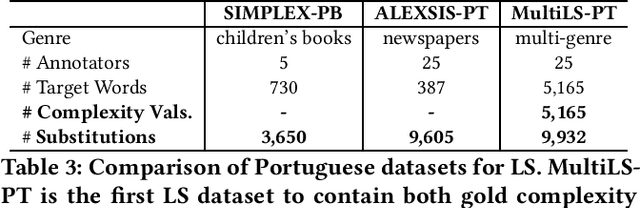
Lexical Simplification (LS) automatically replaces difficult to read words for easier alternatives while preserving a sentence's original meaning. LS is a precursor to Text Simplification with the aim of improving text accessibility to various target demographics, including children, second language learners, individuals with reading disabilities or low literacy. Several datasets exist for LS. These LS datasets specialize on one or two sub-tasks within the LS pipeline. However, as of this moment, no single LS dataset has been developed that covers all LS sub-tasks. We present MultiLS, the first LS framework that allows for the creation of a multi-task LS dataset. We also present MultiLS-PT, the first dataset to be created using the MultiLS framework. We demonstrate the potential of MultiLS-PT by carrying out all LS sub-tasks of (1). lexical complexity prediction (LCP), (2). substitute generation, and (3). substitute ranking for Portuguese. Model performances are reported, ranging from transformer-based models to more recent large language models (LLMs).