 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiLS: A Multi-task Lexical Simplification Framework
Feb 22, 2024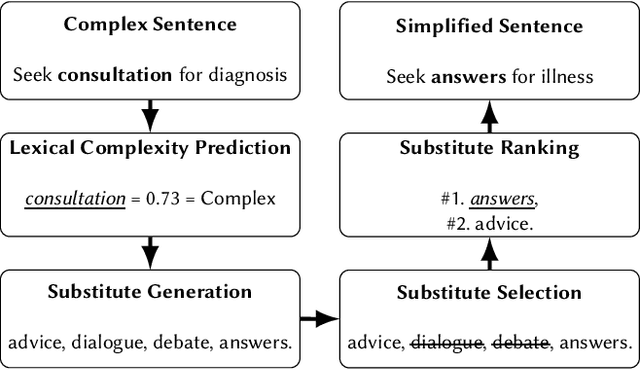

Lexical Simplification (LS) automatically replaces difficult to read words for easier alternatives while preserving a sentence's original meaning. LS is a precursor to Text Simplification with the aim of improving text accessibility to various target demographics, including children, second language learners, individuals with reading disabilities or low literacy. Several datasets exist for LS. These LS datasets specialize on one or two sub-tasks within the LS pipeline. However, as of this moment, no single LS dataset has been developed that covers all LS sub-tasks. We present MultiLS, the first LS framework that allows for the creation of a multi-task LS dataset. We also present MultiLS-PT, the first dataset to be created using the MultiLS framework. We demonstrate the potential of MultiLS-PT by carrying out all LS sub-tasks of (1). lexical complexity prediction (LCP), (2). substitute generation, and (3). substitute ranking for Portuguese. Model performances are reported, ranging from transformer-based models to more recent large language models (LLMs).
Health Text Simplification: An Annotated Corpus for Digestive Cancer Education and Novel Strategies for Reinforcement Learning
Jan 26, 2024
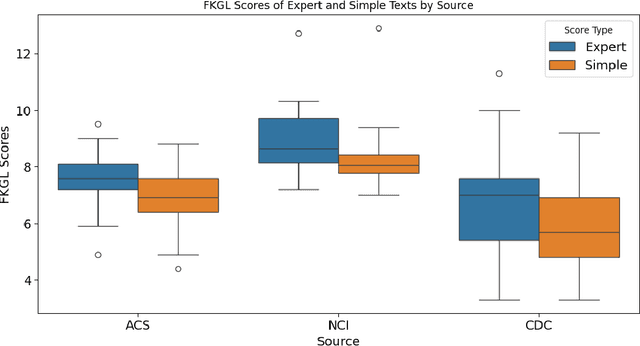
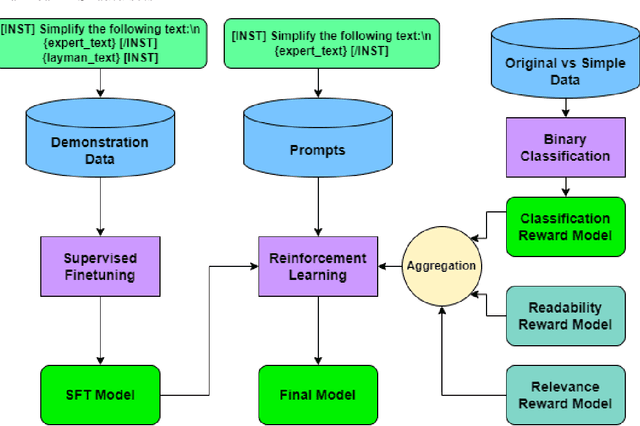
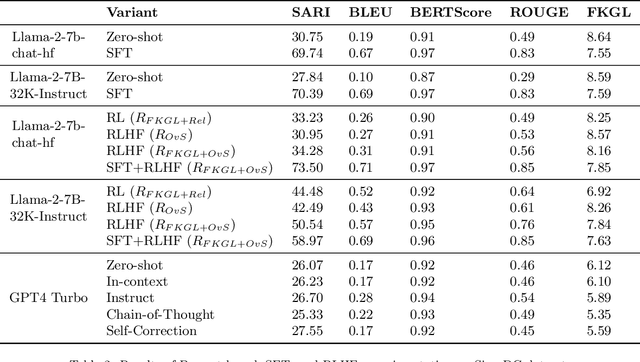
Objective: The reading level of health educational materials significantly influences information understandability and accessibility, particularly for minoritized populations. Many patient educational resources surpass the reading level and complexity of widely accepted standards. There is a critical need for high-performing text simplification models in health information to enhance dissemination and literacy. This need is particularly acute in cancer education, where effective prevention and screening education can substantially reduce morbidity and mortality. Methods: We introduce Simplified Digestive Cancer (SimpleDC), a parallel corpus of cancer education materials tailored for health text simplification research. Utilizing SimpleDC alongside the existing Med-EASi corpus, we explore Large Language Model (LLM)-based simplification methods, including fine-tuning, reinforcement learning (RL), reinforcement learning with human feedback (RLHF), domain adaptation, and prompt-based approaches. Our experimentation encompasses Llama 2 and GPT-4. A novel RLHF reward function is introduced, featuring a lightweight model adept at distinguishing between original and simplified texts, thereby enhancing the model's effectiveness with unlabeled data. Results: Fine-tuned Llama 2 models demonstrated high performance across various metrics. Our innovative RLHF reward function surpassed existing RL text simplification reward functions in effectiveness. The results underscore that RL/RLHF can augment fine-tuning, facilitating model training on unlabeled text and improving performance. Additionally, these methods effectively adapt out-of-domain text simplification models to targeted domains.
Offensive Language Identification in Transliterated and Code-Mixed Bangla
Nov 25, 2023Identifying offensive content in social media is vital for creating safe online communities. Several recent studies have addressed this problem by creating datasets for various languages. In this paper, we explore offensive language identification in texts with transliterations and code-mixing, linguistic phenomena common in multilingual societies, and a known challenge for NLP systems. We introduce TB-OLID, a transliterated Bangla offensive language dataset containing 5,000 manually annotated comments. We train and fine-tune machine learning models on TB-OLID, and we evaluate their results on this dataset. Our results show that English pre-trained transformer-based models, such as fBERT and HateBERT achieve the best performance on this dataset.
Findings of the VarDial Evaluation Campaign 2023
May 31, 2023This report presents the results of the shared tasks organized as part of the VarDial Evaluation Campaign 2023. The campaign is part of the tenth workshop on Natural Language Processing (NLP) for Similar Languages, Varieties and Dialects (VarDial), co-located with EACL 2023. Three separate shared tasks were included this year: Slot and intent detection for low-resource language varieties (SID4LR), Discriminating Between Similar Languages -- True Labels (DSL-TL), and Discriminating Between Similar Languages -- Speech (DSL-S). All three tasks were organized for the first time this year.
Deep Learning Approaches to Lexical Simplification: A Survey
May 19, 2023Lexical Simplification (LS) is the task of replacing complex for simpler words in a sentence whilst preserving the sentence's original meaning. LS is the lexical component of Text Simplification (TS) with the aim of making texts more accessible to various target populations. A past survey (Paetzold and Specia, 2017) has provided a detailed overview of LS. Since this survey, however, the AI/NLP community has been taken by storm by recent advances in deep learning, particularly with the introduction of large language models (LLM) and prompt learning. The high performance of these models sparked renewed interest in LS. To reflect these recent advances, we present a comprehensive survey of papers published between 2017 and 2023 on LS and its sub-tasks with a special focus on deep learning. We also present benchmark datasets for the future development of LS systems.
Lexical Complexity Prediction: An Overview
Mar 08, 2023

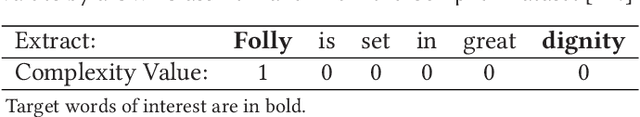

The occurrence of unknown words in texts significantly hinders reading comprehension. To improve accessibility for specific target populations, computational modelling has been applied to identify complex words in texts and substitute them for simpler alternatives. In this paper, we present an overview of computational approaches to lexical complexity prediction focusing on the work carried out on English data. We survey relevant approaches to this problem which include traditional machine learning classifiers (e.g. SVMs, logistic regression) and deep neural networks as well as a variety of features, such as those inspired by literature in psycholinguistics as well as word frequency, word length, and many others. Furthermore, we introduce readers to past competitions and available datasets created on this topic. Finally, we include brief sections on applications of lexical complexity prediction, such as readability and text simplification, together with related studies on languages other than English.
Language Variety Identification with True Labels
Mar 02, 2023



Language identification is an important first step in many IR and NLP applications. Most publicly available language identification datasets, however, are compiled under the assumption that the gold label of each instance is determined by where texts are retrieved from. Research has shown that this is a problematic assumption, particularly in the case of very similar languages (e.g., Croatian and Serbian) and national language varieties (e.g., Brazilian and European Portuguese), where texts may contain no distinctive marker of the particular language or variety. To overcome this important limitation, this paper presents DSL True Labels (DSL-TL), the first human-annotated multilingual dataset for language variety identification. DSL-TL contains a total of 12,900 instances in Portuguese, split between European Portuguese and Brazilian Portuguese; Spanish, split between Argentine Spanish and Castilian Spanish; and English, split between American English and British English. We trained multiple models to discriminate between these language varieties, and we present the results in detail. The data and models presented in this paper provide a reliable benchmark toward the development of robust and fairer language variety identification systems. We make DSL-TL freely available to the research community.
Findings of the TSAR-2022 Shared Task on Multilingual Lexical Simplification
Feb 06, 2023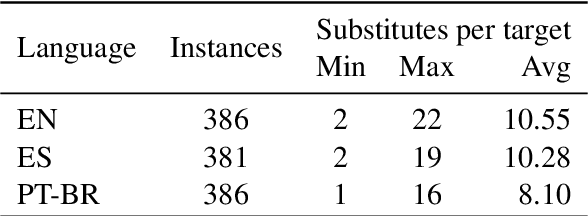
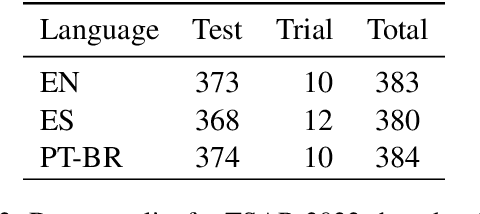
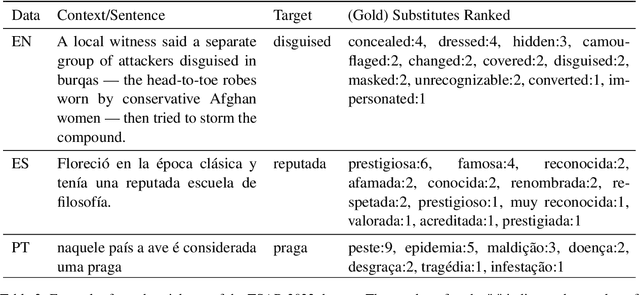
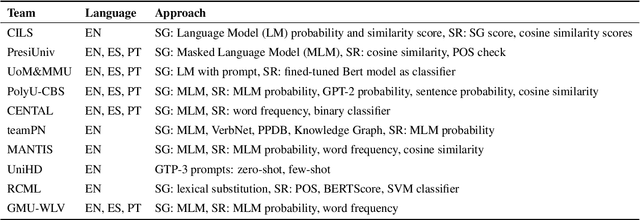
We report findings of the TSAR-2022 shared task on multilingual lexical simplification, organized as part of the Workshop on Text Simplification, Accessibility, and Readability TSAR-2022 held in conjunction with EMNLP 2022. The task called the Natural Language Processing research community to contribute with methods to advance the state of the art in multilingual lexical simplification for English, Portuguese, and Spanish. A total of 14 teams submitted the results of their lexical simplification systems for the provided test data. Results of the shared task indicate new benchmarks in Lexical Simplification with English lexical simplification quantitative results noticeably higher than those obtained for Spanish and (Brazilian) Portuguese.
Overview of the HASOC Subtrack at FIRE 2022: Offensive Language Identification in Marathi
Nov 18, 2022



The widespread of offensive content online has become a reason for great concern in recent years, motivating researchers to develop robust systems capable of identifying such content automatically. With the goal of carrying out a fair evaluation of these systems, several international competitions have been organized, providing the community with important benchmark data and evaluation methods for various languages. Organized since 2019, the HASOC (Hate Speech and Offensive Content Identification) shared task is one of these initiatives. In its fourth iteration, HASOC 2022 included three subtracks for English, Hindi, and Marathi. In this paper, we report the results of the HASOC 2022 Marathi subtrack which provided participants with a dataset containing data from Twitter manually annotated using the popular OLID taxonomy. The Marathi track featured three additional subtracks, each corresponding to one level of the taxonomy: Task A - offensive content identification (offensive vs. non-offensive); Task B - categorization of offensive types (targeted vs. untargeted), and Task C - offensive target identification (individual vs. group vs. others). Overall, 59 runs were submitted by 10 teams. The best systems obtained an F1 of 0.9745 for Subtrack 3A, an F1 of 0.9207 for Subtrack 3B, and F1 of 0.9607 for Subtrack 3C. The best performing algorithms were a mixture of traditional and deep learning approaches.
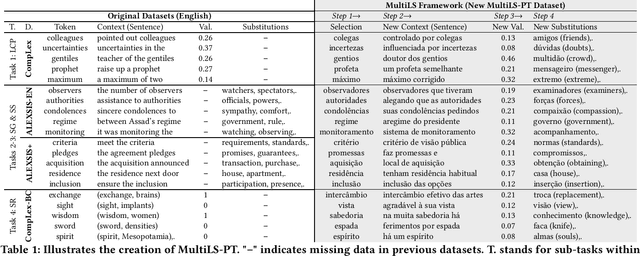
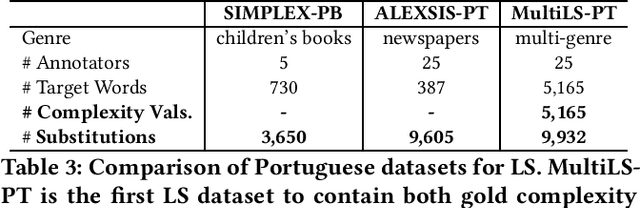
ALEXSIS-PT: A New Resource for Portuguese Lexical Simplification
Sep 19, 2022



Lexical simplification (LS) is the task of automatically replacing complex words for easier ones making texts more accessible to various target populations (e.g. individuals with low literacy, individuals with learning disabilities, second language learners). To train and test models, LS systems usually require corpora that feature complex words in context along with their candidate substitutions. To continue improving the performance of LS systems we introduce ALEXSIS-PT, a novel multi-candidate dataset for Brazilian Portuguese LS containing 9,605 candidate substitutions for 387 complex words. ALEXSIS-PT has been compiled following the ALEXSIS protocol for Spanish opening exciting new avenues for cross-lingual models. ALEXSIS-PT is the first LS multi-candidate dataset that contains Brazilian newspaper articles. We evaluated four models for substitute generation on this dataset, namely mDistilBERT, mBERT, XLM-R, and BERTimbau. BERTimbau achieved the highest performance across all evaluation metrics.