 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the TSAR-2022 Shared Task on Multilingual Lexical Simplification
Feb 06, 2023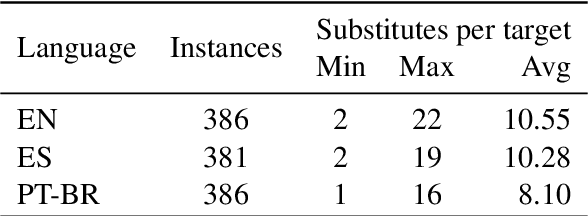
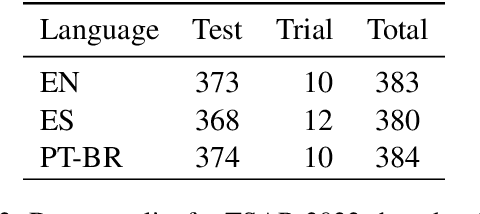
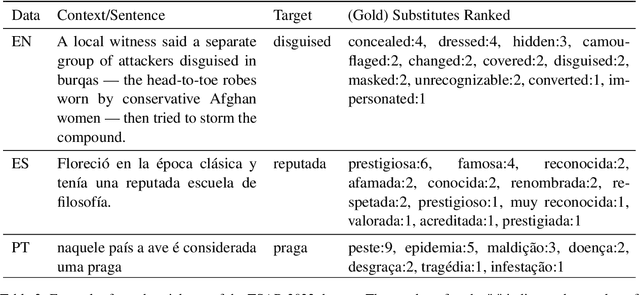
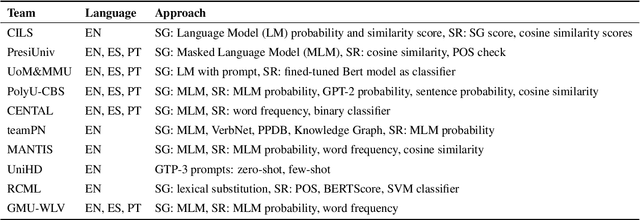
We report findings of the TSAR-2022 shared task on multilingual lexical simplification, organized as part of the Workshop on Text Simplification, Accessibility, and Readability TSAR-2022 held in conjunction with EMNLP 2022. The task called the Natural Language Processing research community to contribute with methods to advance the state of the art in multilingual lexical simplification for English, Portuguese, and Spanish. A total of 14 teams submitted the results of their lexical simplification systems for the provided test data. Results of the shared task indicate new benchmarks in Lexical Simplification with English lexical simplification quantitative results noticeably higher than those obtained for Spanish and (Brazilian) Portuguese.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Benchmarking Automatic Detection of Psycholinguistic Characteristics for Better Human-Computer Interaction
Jan 13, 2021
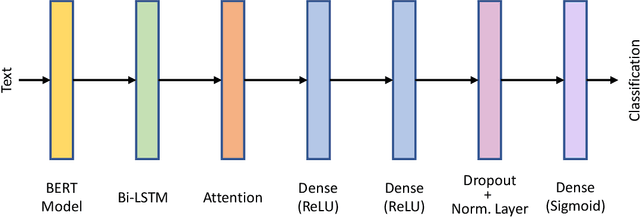

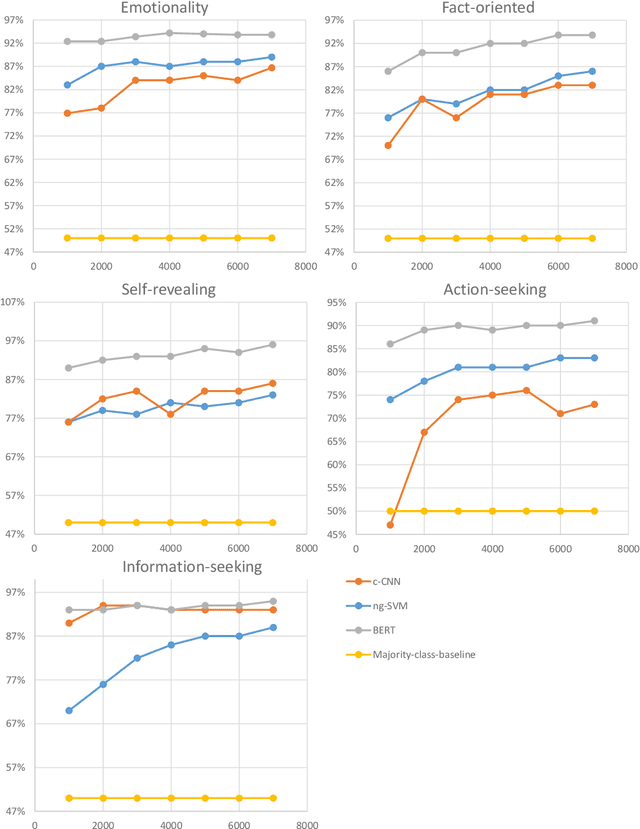
When two people pay attention to each other and are interested in what the other has to say or write, they almost instantly adapt their writing/speaking style to match the other. For a successful interaction with a user, chatbots and dialogue systems should be able to do the same. We propose a framework consisting of five psycholinguistic textual characteristics for better human-computer interaction. We describe the annotation processes used for collecting the data, and benchmark five binary classification tasks, experimenting with different training sizes and model architectures. We perform experiments in English, Spanish, German, Chinese, and Arabic. The best architectures noticeably outperform several baselines and achieve macro-averaged F1-scores between 72% and 96% depending on the language and the task. Similar results are achieved even with a small amount of training data. The proposed framework proved to be fairly easy to model for various languages even with small amount of manually annotated data if right architectures are used. At the same time, it showed potential for improving user satisfaction if applied in existing commercial chatbots.
A Report on the Complex Word Identification Shared Task 2018
Apr 24, 2018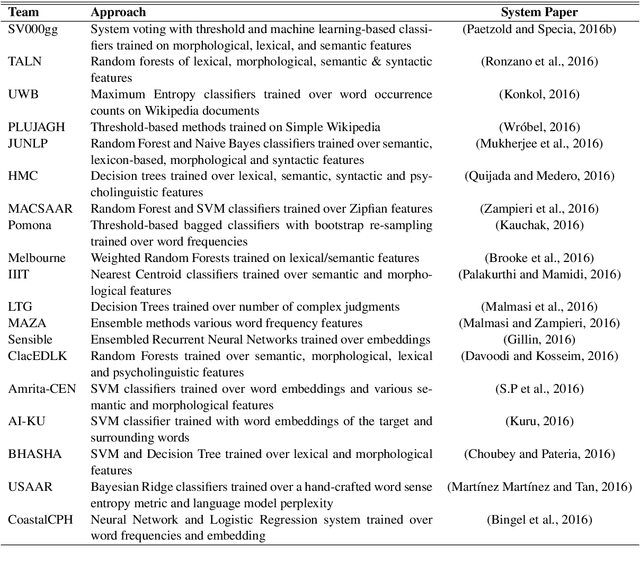
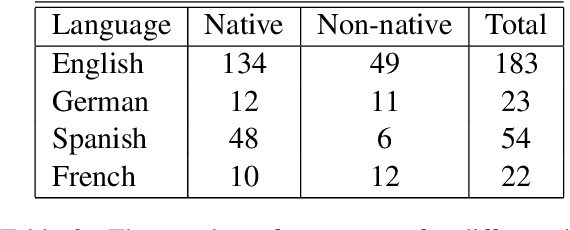
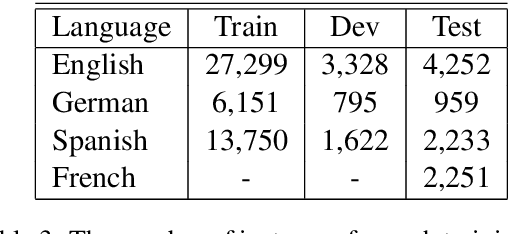
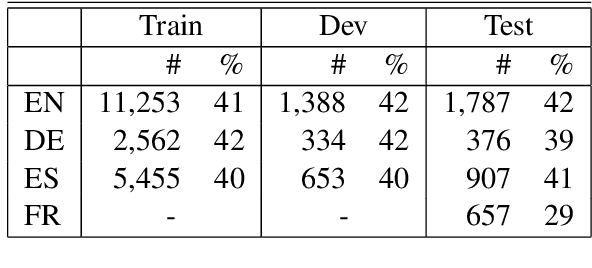
We report the findings of the second Complex Word Identification (CWI) shared task organized as part of the BEA workshop co-located with NAACL-HLT'2018. The second CWI shared task featured multilingual and multi-genre datasets divided into four tracks: English monolingual, German monolingual, Spanish monolingual, and a multilingual track with a French test set, and two tasks: binary classification and probabilistic classification. A total of 12 teams submitted their results in different task/track combinations and 11 of them wrote system description papers that are referred to in this report and appear in the BEA workshop proceedings.