 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multilingual Human Annotated Corpus of Original and Easy-to-Read Texts to Support Access to Democratic Participatory Processes
Mar 05, 2026Being able to understand information is a key factor for a self-determined life and society. It is also very important for participating in democratic processes. The study of automatic text simplification is often limited by the availability of high quality material for the training and evaluation on automatic simplifiers. This is true for English, but more so for less resourced languages like Spanish, Catalan and Italian. In order to fill this gap, we present a corpus of original texts for these 3 languages, with high quality simplification produced by human experts in text simplification. It was developed within the iDEM project to assess the impact of Easy-to-Read (E2R) language for democratic participation. The original texts were compiled from domains related to this topic. The corpus includes different text types, selected based on relevance, copyright availability, and ethical standards. All texts were simplified to E2R level. The corpus is particularity valuable because it includes the first annotated corpus of its kind for the Catalan language. It also represents a noteworthy contribution for Spanish and Italian, offering high-quality, human-annotated language resources that are rarely available in these domains. The corpus will be made freely accessible to the public.
MultiLS-SP/CA: Lexical Complexity Prediction and Lexical Simplification Resources for Catalan and Spanish
Apr 11, 2024



Automatic lexical simplification is a task to substitute lexical items that may be unfamiliar and difficult to understand with easier and more common words. This paper presents MultiLS-SP/CA, a novel dataset for lexical simplification in Spanish and Catalan. This dataset represents the first of its kind in Catalan and a substantial addition to the sparse data on automatic lexical simplification which is available for Spanish. Specifically, MultiLS-SP is the first dataset for Spanish which includes scalar ratings of the understanding difficulty of lexical items. In addition, we describe experiments with this dataset, which can serve as a baseline for future work on the same data.
A Novel Dataset for Financial Education Text Simplification in Spanish
Dec 15, 2023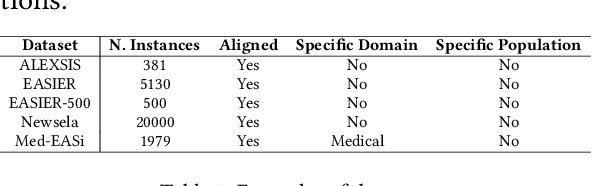
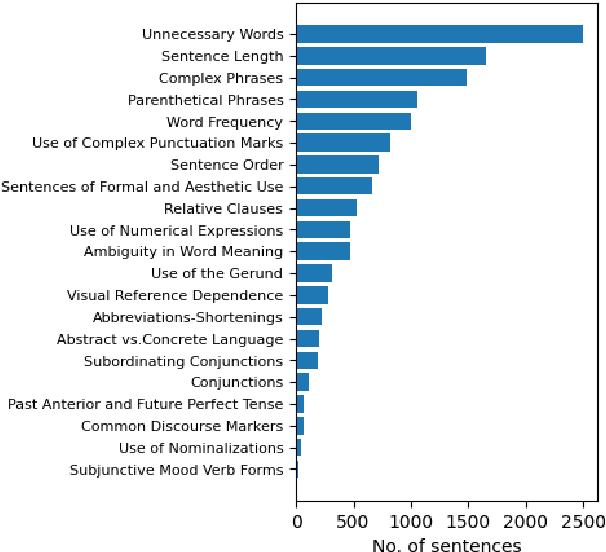
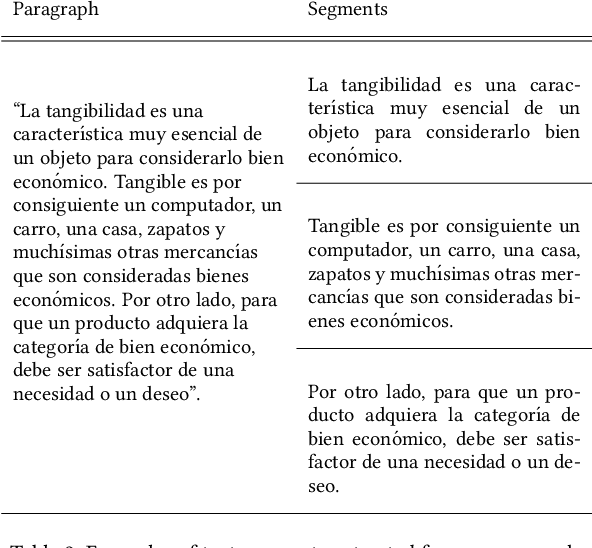
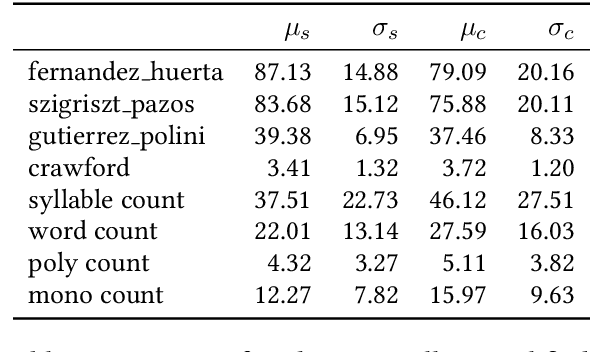
Text simplification, crucial in natural language processing, aims to make texts more comprehensible, particularly for specific groups like visually impaired Spanish speakers, a less-represented language in this field. In Spanish, there are few datasets that can be used to create text simplification systems. Our research has the primary objective to develop a Spanish financial text simplification dataset. We created a dataset with 5,314 complex and simplified sentence pairs using established simplification rules. We also compared our dataset with the simplifications generated from GPT-3, Tuner, and MT5, in order to evaluate the feasibility of data augmentation using these systems. In this manuscript we present the characteristics of our dataset and the findings of the comparisons with other systems. The dataset is available at Hugging face, saul1917/FEINA.
Creating a silver standard for patent simplification
Oct 24, 2023



Patents are legal documents that aim at protecting inventions on the one hand and at making technical knowledge circulate on the other. Their complex style -- a mix of legal, technical, and extremely vague language -- makes their content hard to access for humans and machines and poses substantial challenges to the information retrieval community. This paper proposes an approach to automatically simplify patent text through rephrasing. Since no in-domain parallel simplification data exist, we propose a method to automatically generate a large-scale silver standard for patent sentences. To obtain candidates, we use a general-domain paraphrasing system; however, the process is error-prone and difficult to control. Thus, we pair it with proper filters and construct a cleaner corpus that can successfully be used to train a simplification system. Human evaluation of the synthetic silver corpus shows that it is considered grammatical, adequate, and contains simple sentences.
Multilingual Controllable Transformer-Based Lexical Simplification
Jul 05, 2023



Text is by far the most ubiquitous source of knowledge and information and should be made easily accessible to as many people as possible; however, texts often contain complex words that hinder reading comprehension and accessibility. Therefore, suggesting simpler alternatives for complex words without compromising meaning would help convey the information to a broader audience. This paper proposes mTLS, a multilingual controllable Transformer-based Lexical Simplification (LS) system fined-tuned with the T5 model. The novelty of this work lies in the use of language-specific prefixes, control tokens, and candidates extracted from pre-trained masked language models to learn simpler alternatives for complex words. The evaluation results on three well-known LS datasets -- LexMTurk, BenchLS, and NNSEval -- show that our model outperforms the previous state-of-the-art models like LSBert and ConLS. Moreover, further evaluation of our approach on the part of the recent TSAR-2022 multilingual LS shared-task dataset shows that our model performs competitively when compared with the participating systems for English LS and even outperforms the GPT-3 model on several metrics. Moreover, our model obtains performance gains also for Spanish and Portuguese.
BODEGA: Benchmark for Adversarial Example Generation in Credibility Assessment
Mar 14, 2023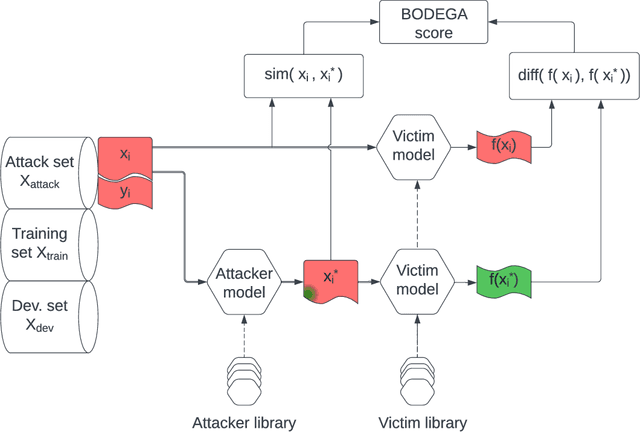
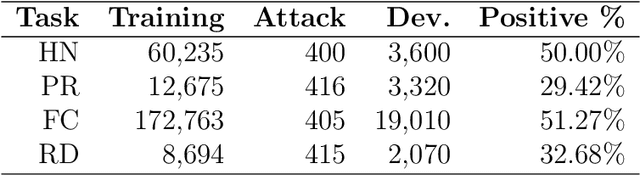

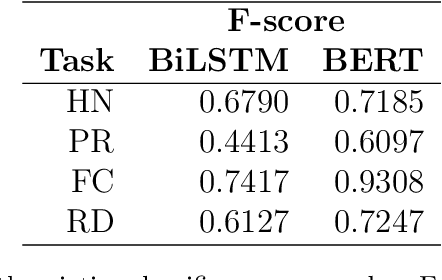
Text classification methods have been widely investigated as a way to detect content of low credibility: fake news, social media bots, propaganda, etc. Quite accurate models (likely based on deep neural networks) help in moderating public electronic platforms and often cause content creators to face rejection of their submissions or removal of already published texts. Having the incentive to evade further detection, content creators try to come up with a slightly modified version of the text (known as an attack with an adversarial example) that exploit the weaknesses of classifiers and result in a different output. Here we introduce BODEGA: a benchmark for testing both victim models and attack methods on four misinformation detection tasks in an evaluation framework designed to simulate real use-cases of content moderation. We also systematically test the robustness of popular text classifiers against available attacking techniques and discover that, indeed, in some cases barely significant changes in input text can mislead the models. We openly share the BODEGA code and data in hope of enhancing the comparability and replicability of further research in this area.
Findings of the TSAR-2022 Shared Task on Multilingual Lexical Simplification
Feb 06, 2023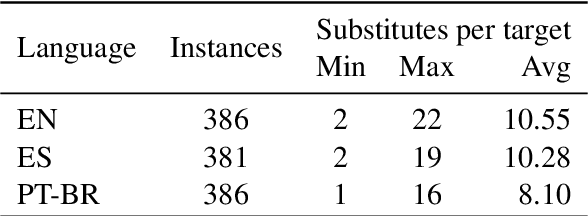
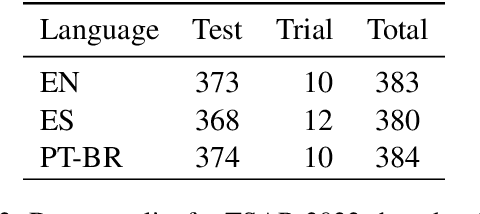
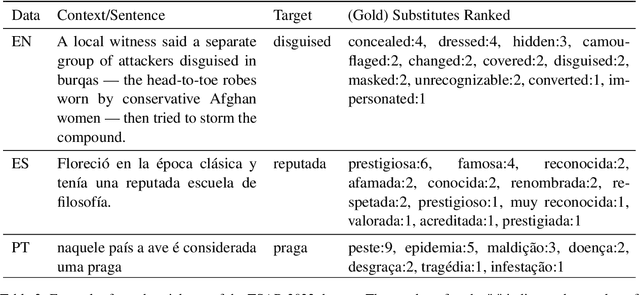
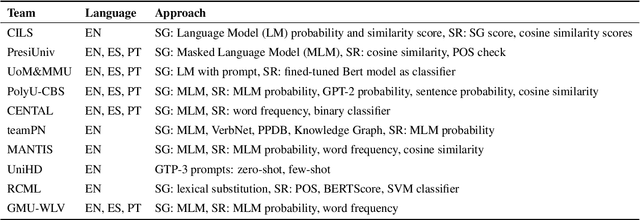
We report findings of the TSAR-2022 shared task on multilingual lexical simplification, organized as part of the Workshop on Text Simplification, Accessibility, and Readability TSAR-2022 held in conjunction with EMNLP 2022. The task called the Natural Language Processing research community to contribute with methods to advance the state of the art in multilingual lexical simplification for English, Portuguese, and Spanish. A total of 14 teams submitted the results of their lexical simplification systems for the provided test data. Results of the shared task indicate new benchmarks in Lexical Simplification with English lexical simplification quantitative results noticeably higher than those obtained for Spanish and (Brazilian) Portuguese.
Controllable Lexical Simplification for English
Feb 06, 2023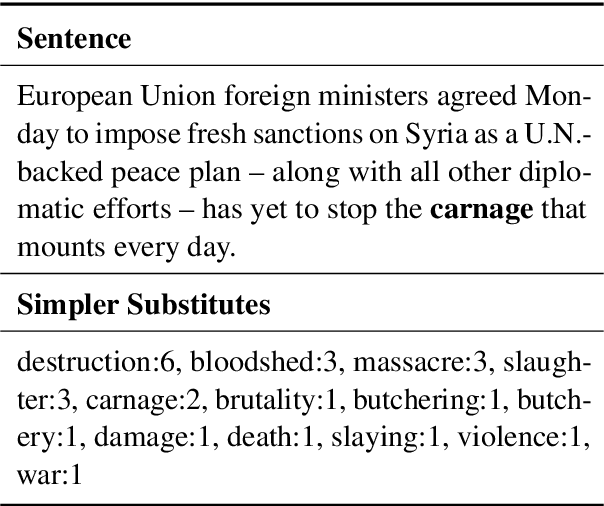

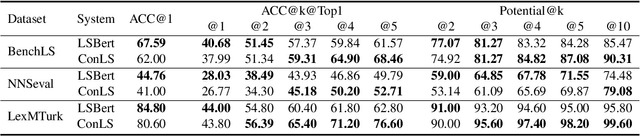
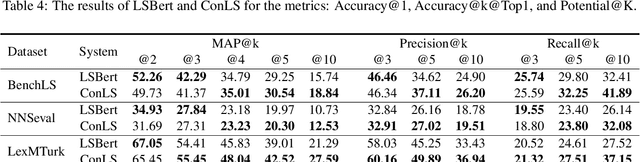
Fine-tuning Transformer-based approaches have recently shown exciting results on sentence simplification task. However, so far, no research has applied similar approaches to the Lexical Simplification (LS) task. In this paper, we present ConLS, a Controllable Lexical Simplification system fine-tuned with T5 (a Transformer-based model pre-trained with a BERT-style approach and several other tasks). The evaluation results on three datasets (LexMTurk, BenchLS, and NNSeval) have shown that our model performs comparable to LSBert (the current state-of-the-art) and even outperforms it in some cases. We also conducted a detailed comparison on the effectiveness of control tokens to give a clear view of how each token contributes to the model.
Lexical Simplification Benchmarks for English, Portuguese, and Spanish
Sep 12, 2022
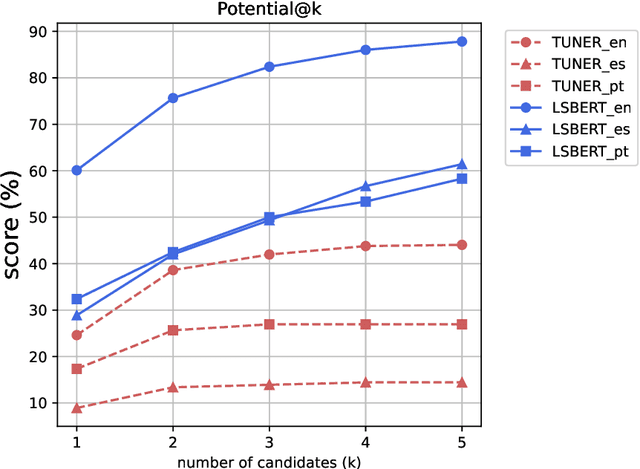
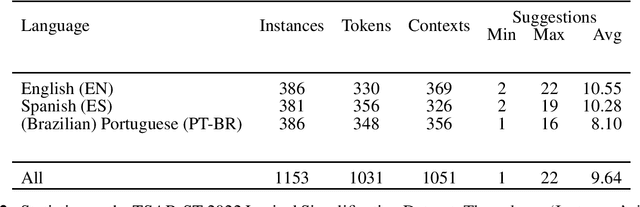
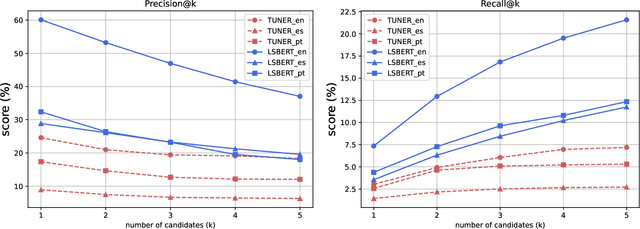
Even in highly-developed countries, as many as 15-30\% of the population can only understand texts written using a basic vocabulary. Their understanding of everyday texts is limited, which prevents them from taking an active role in society and making informed decisions regarding healthcare, legal representation, or democratic choice. Lexical simplification is a natural language processing task that aims to make text understandable to everyone by replacing complex vocabulary and expressions with simpler ones, while preserving the original meaning. It has attracted considerable attention in the last 20 years, and fully automatic lexical simplification systems have been proposed for various languages. The main obstacle for the progress of the field is the absence of high-quality datasets for building and evaluating lexical simplification systems. We present a new benchmark dataset for lexical simplification in English, Spanish, and (Brazilian) Portuguese, and provide details about data selection and annotation procedures. This is the first dataset that offers a direct comparison of lexical simplification systems for three languages. To showcase the usability of the dataset, we adapt two state-of-the-art lexical simplification systems with differing architectures (neural vs.\ non-neural) to all three languages (English, Spanish, and Brazilian Portuguese) and evaluate their performances on our new dataset. For a fairer comparison, we use several evaluation measures which capture varied aspects of the systems' efficacy, and discuss their strengths and weaknesses. We find a state-of-the-art neural lexical simplification system outperforms a state-of-the-art non-neural lexical simplification system in all three languages. More importantly, we find that the state-of-the-art neural lexical simplification systems perform significantly better for English than for Spanish and Portuguese.
Recognizing Musical Entities in User-generated Content
Apr 01, 2019
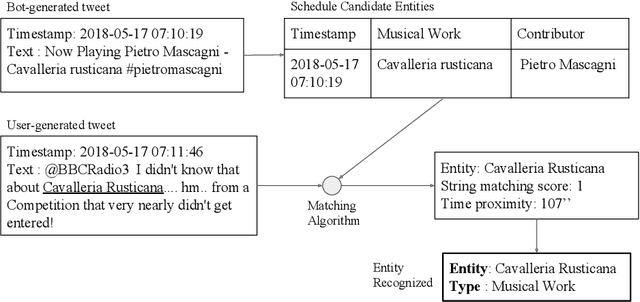

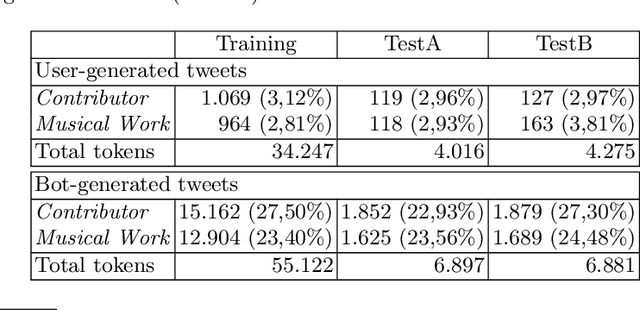
Recognizing Musical Entities is important for Music Information Retrieval (MIR) since it can improve the performance of several tasks such as music recommendation, genre classification or artist similarity. However, most entity recognition systems in the music domain have concentrated on formal texts (e.g. artists' biographies, encyclopedic articles, etc.), ignoring rich and noisy user-generated content. In this work, we present a novel method to recognize musical entities in Twitter content generated by users following a classical music radio channel. Our approach takes advantage of both formal radio schedule and users' tweets to improve entity recognition. We instantiate several machine learning algorithms to perform entity recognition combining task-specific and corpus-based features. We also show how to improve recognition results by jointly considering formal and user-generated content