 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECSELFMASK: Leveraging Unlabeled Text via Self-Relevance-Guided Masking for Decoder-Only Classification
Jun 09, 2026Classification tasks require annotated data, which can often be expensive, time-consuming, or even unfeasible to collect. This is the case of the medical domain, where large datasets often have few annotated examples. To address this, we propose DecSelfMask (Decoder Self-learning by Masking), an approach to enhance decoder-only performance on classification tasks. We build on common self-learning approaches by leveraging a model to create training examples from unlabeled data to propose a novel relevance-guided masking strategy. We use relevance attribution methods to determine what portions of unannotated texts are relevant for a task. We then create self-supervised training examples by masking out those portions, training the model to reconstruct them via next-token-prediction. We hypothesize that those examples convey knowledge about the structure and semantics of unannotated data that can be useful for downstream performance. We test our approach on 136 tasks from a collection of 1.9M clinical notes from an Italian hospital. We quantify DecSelfMask's impact on downstream tasks on 5 models of different scales and families, including a probing analysis. Experiments show consistent gains, outperforming standard supervised fine-tuning approaches (+19.9 points in Macro F1), synthetic label generation (+12.5), and continual pretraining (+6.3), as well as common baselines.
Small LLMs for Medical NLP: a Systematic Analysis of Few-Shot, Constraint Decoding, Fine-Tuning and Continual Pre-Training in Italian
Feb 19, 2026Large Language Models (LLMs) consistently excel in diverse medical Natural Language Processing (NLP) tasks, yet their substantial computational requirements often limit deployment in real-world healthcare settings. In this work, we investigate whether "small" LLMs (around one billion parameters) can effectively perform medical tasks while maintaining competitive accuracy. We evaluate models from three major families-Llama-3, Gemma-3, and Qwen3-across 20 clinical NLP tasks among Named Entity Recognition, Relation Extraction, Case Report Form Filling, Question Answering, and Argument Mining. We systematically compare a range of adaptation strategies, both at inference time (few-shot prompting, constraint decoding) and at training time (supervised fine-tuning, continual pretraining). Fine-tuning emerges as the most effective approach, while the combination of few-shot prompting and constraint decoding offers strong lower-resource alternatives. Our results show that small LLMs can match or even surpass larger baselines, with our best configuration based on Qwen3-1.7B achieving an average score +9.2 points higher than Qwen3-32B. We release a comprehensive collection of all the publicly available Italian medical datasets for NLP tasks, together with our top-performing models. Furthermore, we release an Italian dataset of 126M words from the Emergency Department of an Italian Hospital, and 175M words from various sources that we used for continual pre-training.
Converting Annotated Clinical Cases into Structured Case Report Forms
Jun 13, 2025Case Report Forms (CRFs) are largely used in medical research as they ensure accuracy, reliability, and validity of results in clinical studies. However, publicly available, wellannotated CRF datasets are scarce, limiting the development of CRF slot filling systems able to fill in a CRF from clinical notes. To mitigate the scarcity of CRF datasets, we propose to take advantage of available datasets annotated for information extraction tasks and to convert them into structured CRFs. We present a semi-automatic conversion methodology, which has been applied to the E3C dataset in two languages (English and Italian), resulting in a new, high-quality dataset for CRF slot filling. Through several experiments on the created dataset, we report that slot filling achieves 59.7% for Italian and 67.3% for English on a closed Large Language Models (zero-shot) and worse performances on three families of open-source models, showing that filling CRFs is challenging even for recent state-of-the-art LLMs. We release the datest at https://huggingface.co/collections/NLP-FBK/e3c-to-crf-67b9844065460cbe42f80166
Low-resource Information Extraction with the European Clinical Case Corpus
Mar 26, 2025We present E3C-3.0, a multilingual dataset in the medical domain, comprising clinical cases annotated with diseases and test-result relations. The dataset includes both native texts in five languages (English, French, Italian, Spanish and Basque) and texts translated and projected from the English source into five target languages (Greek, Italian, Polish, Slovak, and Slovenian). A semi-automatic approach has been implemented, including automatic annotation projection based on Large Language Models (LLMs) and human revision. We present several experiments showing that current state-of-the-art LLMs can benefit from being fine-tuned on the E3C-3.0 dataset. We also show that transfer learning in different languages is very effective, mitigating the scarcity of data. Finally, we compare performance both on native data and on projected data. We release the data at https://huggingface.co/collections/NLP-FBK/e3c-projected-676a7d6221608d60e4e9fd89 .
Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain
Apr 11, 2024



Research on language technology for the development of medical applications is currently a hot topic in Natural Language Understanding and Generation. Thus, a number of large language models (LLMs) have recently been adapted to the medical domain, so that they can be used as a tool for mediating in human-AI interaction. While these LLMs display competitive performance on automated medical texts benchmarks, they have been pre-trained and evaluated with a focus on a single language (English mostly). This is particularly true of text-to-text models, which typically require large amounts of domain-specific pre-training data, often not easily accessible for many languages. In this paper, we address these shortcomings by compiling, to the best of our knowledge, the largest multilingual corpus for the medical domain in four languages, namely English, French, Italian and Spanish. This new corpus has been used to train Medical mT5, the first open-source text-to-text multilingual model for the medical domain. Additionally, we present two new evaluation benchmarks for all four languages with the aim of facilitating multilingual research in this domain. A comprehensive evaluation shows that Medical mT5 outperforms both encoders and similarly sized text-to-text models for the Spanish, French, and Italian benchmarks, while being competitive with current state-of-the-art LLMs in English.
Creating a silver standard for patent simplification
Oct 24, 2023



Patents are legal documents that aim at protecting inventions on the one hand and at making technical knowledge circulate on the other. Their complex style -- a mix of legal, technical, and extremely vague language -- makes their content hard to access for humans and machines and poses substantial challenges to the information retrieval community. This paper proposes an approach to automatically simplify patent text through rephrasing. Since no in-domain parallel simplification data exist, we propose a method to automatically generate a large-scale silver standard for patent sentences. To obtain candidates, we use a general-domain paraphrasing system; however, the process is error-prone and difficult to control. Thus, we pair it with proper filters and construct a cleaner corpus that can successfully be used to train a simplification system. Human evaluation of the synthetic silver corpus shows that it is considered grammatical, adequate, and contains simple sentences.
Summarization, Simplification, and Generation: The Case of Patents
Apr 30, 2021

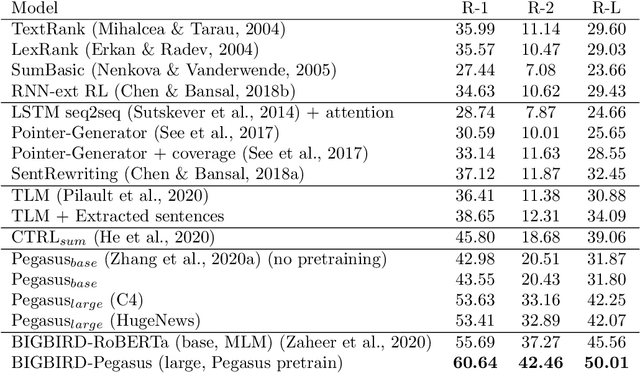
We survey Natural Language Processing (NLP) approaches to summarizing, simplifying, and generating patents' text. While solving these tasks has important practical applications - given patents' centrality in the R&D process - patents' idiosyncrasies open peculiar challenges to the current NLP state of the art. This survey aims at a) describing patents' characteristics and the questions they raise to the current NLP systems, b) critically presenting previous work and its evolution, and c) drawing attention to directions of research in which further work is needed. To the best of our knowledge, this is the first survey of generative approaches in the patent domain.
Natural Language Processing of Clinical Notes on Chronic Diseases: Systematic Review
Aug 15, 2019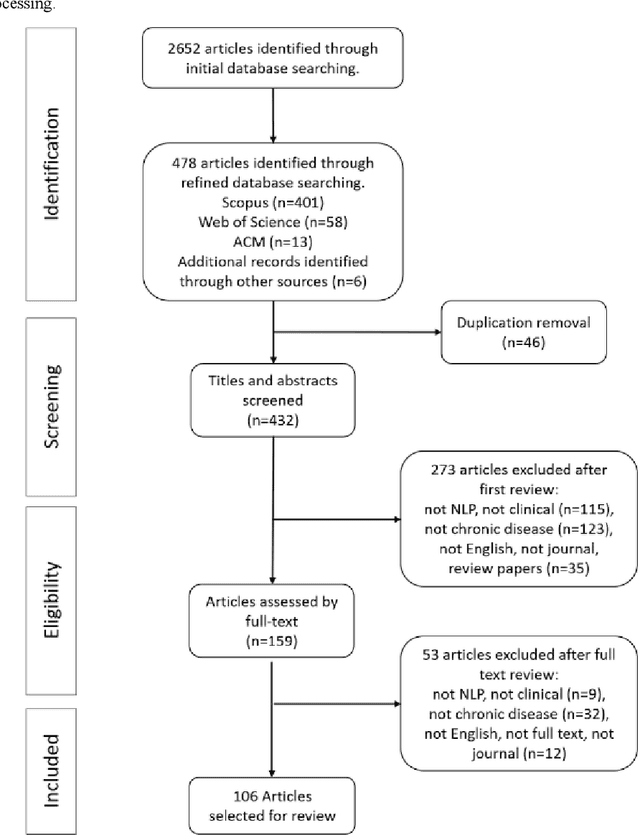

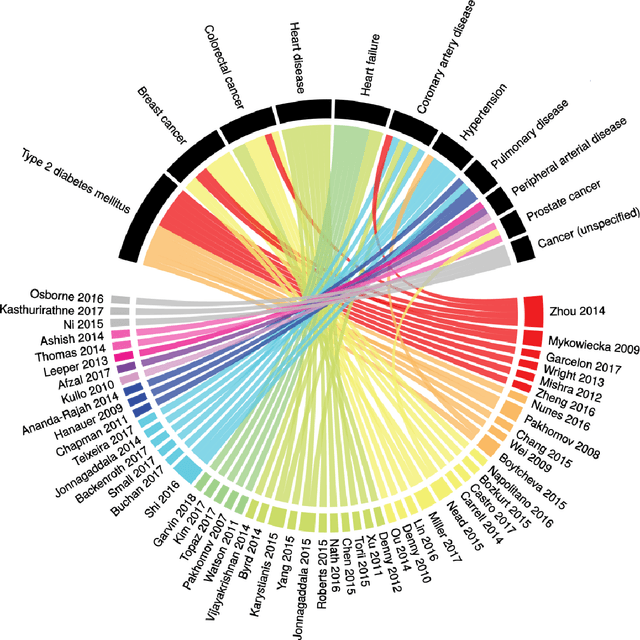

Of the 2652 articles considered, 106 met the inclusion criteria. Review of the included papers resulted in identification of 43 chronic diseases, which were then further classified into 10 disease categories using ICD-10. The majority of studies focused on diseases of the circulatory system (n=38) while endocrine and metabolic diseases were fewest (n=14). This was due to the structure of clinical records related to metabolic diseases, which typically contain much more structured data, compared with medical records for diseases of the circulatory system, which focus more on unstructured data and consequently have seen a stronger focus of NLP. The review has shown that there is a significant increase in the use of machine learning methods compared to rule-based approaches; however, deep learning methods remain emergent (n=3). Consequently, the majority of works focus on classification of disease phenotype with only a handful of papers addressing extraction of comorbidities from the free text or integration of clinical notes with structured data. There is a notable use of relatively simple methods, such as shallow classifiers (or combination with rule-based methods), due to the interpretability of predictions, which still represents a significant issue for more complex methods. Finally, scarcity of publicly available data may also have contributed to insufficient development of more advanced methods, such as extraction of word embeddings from clinical notes. Further efforts are still required to improve (1) progression of clinical NLP methods from extraction toward understanding; (2) recognition of relations among entities rather than entities in isolation; (3) temporal extraction to understand past, current, and future clinical events; (4) exploitation of alternative sources of clinical knowledge; and (5) availability of large-scale, de-identified clinical corpora.
* Supplementary material detailing articles reviewed, classification of diseases and associated algorithms, can be found at: http://venetosmani.com/research/publications.html