 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteerEval: Inference-time Interventions Strengthen Multilingual Generalization in Neural Summarization Metrics
Jan 22, 2026An increasing body of work has leveraged multilingual language models for Natural Language Generation tasks such as summarization. A major empirical bottleneck in this area is the shortage of accurate and robust evaluation metrics for many languages, which hinders progress. Recent studies suggest that multilingual language models often use English as an internal pivot language, and that misalignment with this pivot can lead to degraded downstream performance. Motivated by the hypothesis that this mismatch could also apply to multilingual neural metrics, we ask whether steering their activations toward an English pivot can improve correlation with human judgments. We experiment with encoder- and decoder-based metrics and find that test-time intervention methods are effective across the board, increasing metric effectiveness for diverse languages.
Evaluation Should Not Ignore Variation: On the Impact of Reference Set Choice on Summarization Metrics
Jun 17, 2025Human language production exhibits remarkable richness and variation, reflecting diverse communication styles and intents. However, this variation is often overlooked in summarization evaluation. While having multiple reference summaries is known to improve correlation with human judgments, the impact of using different reference sets on reference-based metrics has not been systematically investigated. This work examines the sensitivity of widely used reference-based metrics in relation to the choice of reference sets, analyzing three diverse multi-reference summarization datasets: SummEval, GUMSum, and DUC2004. We demonstrate that many popular metrics exhibit significant instability. This instability is particularly concerning for n-gram-based metrics like ROUGE, where model rankings vary depending on the reference sets, undermining the reliability of model comparisons. We also collect human judgments on LLM outputs for genre-diverse data and examine their correlation with metrics to supplement existing findings beyond newswire summaries, finding weak-to-no correlation. Taken together, we recommend incorporating reference set variation into summarization evaluation to enhance consistency alongside correlation with human judgments, especially when evaluating LLMs.
GFG -- Gender-Fair Generation: A CALAMITA Challenge
Dec 26, 2024



Gender-fair language aims at promoting gender equality by using terms and expressions that include all identities and avoid reinforcing gender stereotypes. Implementing gender-fair strategies is particularly challenging in heavily gender-marked languages, such as Italian. To address this, the Gender-Fair Generation challenge intends to help shift toward gender-fair language in written communication. The challenge, designed to assess and monitor the recognition and generation of gender-fair language in both mono- and cross-lingual scenarios, includes three tasks: (1) the detection of gendered expressions in Italian sentences, (2) the reformulation of gendered expressions into gender-fair alternatives, and (3) the generation of gender-fair language in automatic translation from English to Italian. The challenge relies on three different annotated datasets: the GFL-it corpus, which contains Italian texts extracted from administrative documents provided by the University of Brescia; GeNTE, a bilingual test set for gender-neutral rewriting and translation built upon a subset of the Europarl dataset; and Neo-GATE, a bilingual test set designed to assess the use of non-binary neomorphemes in Italian for both fair formulation and translation tasks. Finally, each task is evaluated with specific metrics: average of F1-score obtained by means of BERTScore computed on each entry of the datasets for task 1, an accuracy measured with a gender-neutral classifier, and a coverage-weighted accuracy for tasks 2 and 3.
Creating a silver standard for patent simplification
Oct 24, 2023



Patents are legal documents that aim at protecting inventions on the one hand and at making technical knowledge circulate on the other. Their complex style -- a mix of legal, technical, and extremely vague language -- makes their content hard to access for humans and machines and poses substantial challenges to the information retrieval community. This paper proposes an approach to automatically simplify patent text through rephrasing. Since no in-domain parallel simplification data exist, we propose a method to automatically generate a large-scale silver standard for patent sentences. To obtain candidates, we use a general-domain paraphrasing system; however, the process is error-prone and difficult to control. Thus, we pair it with proper filters and construct a cleaner corpus that can successfully be used to train a simplification system. Human evaluation of the synthetic silver corpus shows that it is considered grammatical, adequate, and contains simple sentences.
Summarization, Simplification, and Generation: The Case of Patents
Apr 30, 2021

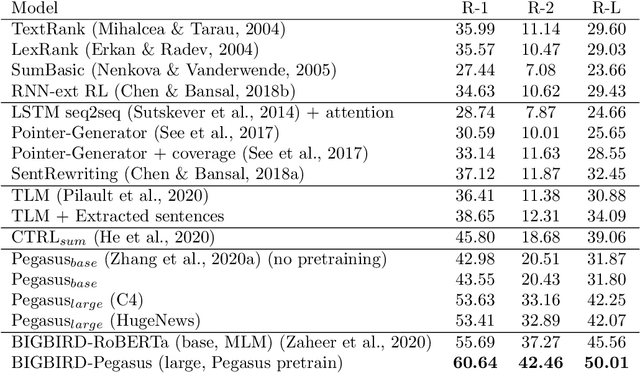
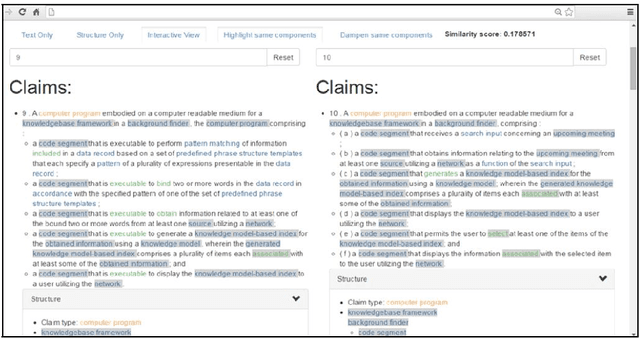
We survey Natural Language Processing (NLP) approaches to summarizing, simplifying, and generating patents' text. While solving these tasks has important practical applications - given patents' centrality in the R&D process - patents' idiosyncrasies open peculiar challenges to the current NLP state of the art. This survey aims at a) describing patents' characteristics and the questions they raise to the current NLP systems, b) critically presenting previous work and its evolution, and c) drawing attention to directions of research in which further work is needed. To the best of our knowledge, this is the first survey of generative approaches in the patent domain.