 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ghost Annotator: a Framework to Explore Human Label Variation in Content Moderation through Conformal Prediction
Jun 01, 2026Current research primarily focuses on model performance, while comparatively less attention has been devoted to uncertainty estimation, particularly in settings where LLMs are increasingly used to generate annotated data. We introduce a framework combining conformal prediction with Collaborative Filtering-style annotators' representation to model LLM behavior in relation to human annotators and to analyze patterns of agreement and disagreement. Using Non-Conformity Scores, we introduce the Ghost Prediction metric and the Ghost Annotator representation to quantify cases in which model predictions diverge from all available human annotations. We compute cosine similarity measures to explore differences in model behavior across sociodemographic axes. We evaluated four LLMs of different size and families across four content moderation datasets. Our finding shows that while we find that all models uncertainty increases with annotator disagreement, larger models tend to be more confident in the classification of texts that are not aligned with any human annotation. Finally, the Ghost Annotator framework reveals a consistent and robust pattern of demographic misalignment, suggesting a structural bias likely rooted in pretraining corpora.
Can NLP Tackle Hate Speech in the Real World? Stakeholder-Informed Feedback and Survey on Counterspeech
Aug 06, 2025



Counterspeech, i.e. the practice of responding to online hate speech, has gained traction in NLP as a promising intervention. While early work emphasised collaboration with non-governmental organisation stakeholders, recent research trends have shifted toward automated pipelines that reuse a small set of legacy datasets, often without input from affected communities. This paper presents a systematic review of 74 NLP studies on counterspeech, analysing the extent to which stakeholder participation influences dataset creation, model development, and evaluation. To complement this analysis, we conducted a participatory case study with five NGOs specialising in online Gender-Based Violence (oGBV), identifying stakeholder-informed practices for counterspeech generation. Our findings reveal a growing disconnect between current NLP research and the needs of communities most impacted by toxic online content. We conclude with concrete recommendations for re-centring stakeholder expertise in counterspeech research.
GFG -- Gender-Fair Generation: A CALAMITA Challenge
Dec 26, 2024



Gender-fair language aims at promoting gender equality by using terms and expressions that include all identities and avoid reinforcing gender stereotypes. Implementing gender-fair strategies is particularly challenging in heavily gender-marked languages, such as Italian. To address this, the Gender-Fair Generation challenge intends to help shift toward gender-fair language in written communication. The challenge, designed to assess and monitor the recognition and generation of gender-fair language in both mono- and cross-lingual scenarios, includes three tasks: (1) the detection of gendered expressions in Italian sentences, (2) the reformulation of gendered expressions into gender-fair alternatives, and (3) the generation of gender-fair language in automatic translation from English to Italian. The challenge relies on three different annotated datasets: the GFL-it corpus, which contains Italian texts extracted from administrative documents provided by the University of Brescia; GeNTE, a bilingual test set for gender-neutral rewriting and translation built upon a subset of the Europarl dataset; and Neo-GATE, a bilingual test set designed to assess the use of non-binary neomorphemes in Italian for both fair formulation and translation tasks. Finally, each task is evaluated with specific metrics: average of F1-score obtained by means of BERTScore computed on each entry of the datasets for task 1, an accuracy measured with a gender-neutral classifier, and a coverage-weighted accuracy for tasks 2 and 3.
O-Dang! The Ontology of Dangerous Speech Messages
Jul 13, 2022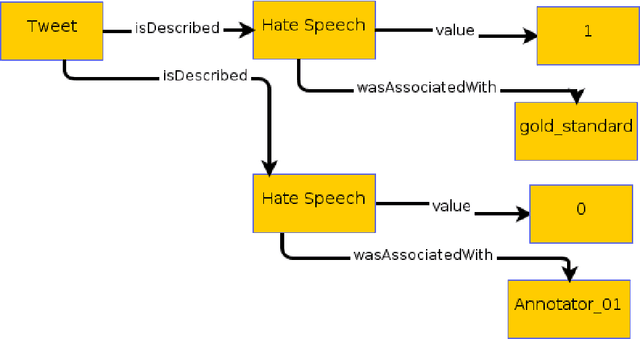
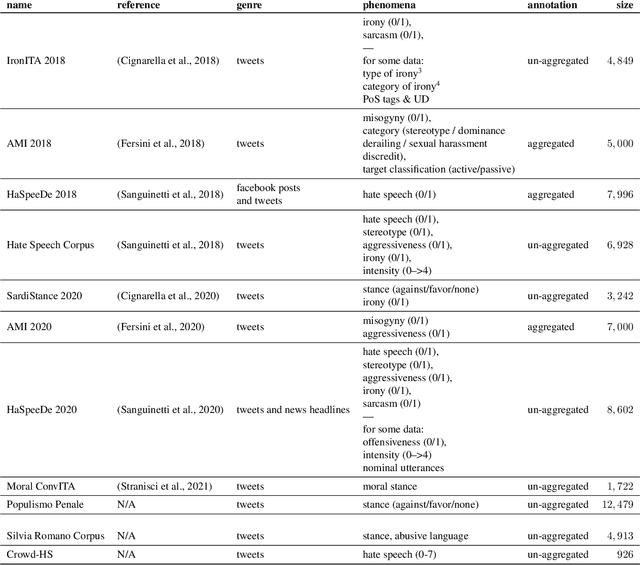
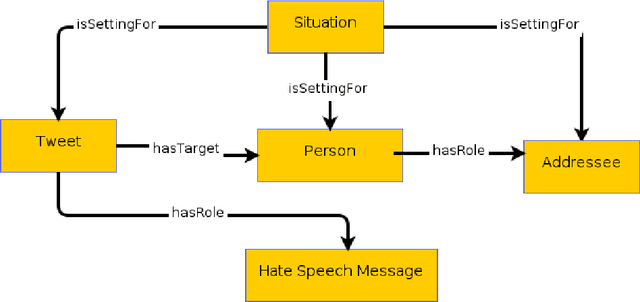
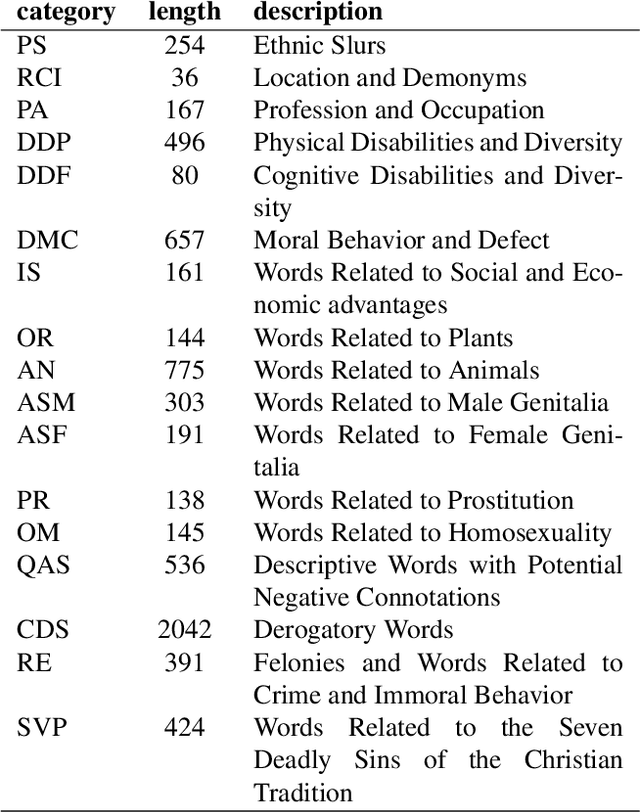
Inside the NLP community there is a considerable amount of language resources created, annotated and released every day with the aim of studying specific linguistic phenomena. Despite a variety of attempts in order to organize such resources has been carried on, a lack of systematic methods and of possible interoperability between resources are still present. Furthermore, when storing linguistic information, still nowadays, the most common practice is the concept of "gold standard", which is in contrast with recent trends in NLP that aim at stressing the importance of different subjectivities and points of view when training machine learning and deep learning methods. In this paper we present O-Dang!: The Ontology of Dangerous Speech Messages, a systematic and interoperable Knowledge Graph (KG) for the collection of linguistic annotated data. O-Dang! is designed to gather and organize Italian datasets into a structured KG, according to the principles shared within the Linguistic Linked Open Data community. The ontology has also been designed to account for a perspectivist approach, since it provides a model for encoding both gold standard and single-annotator labels in the KG. The paper is structured as follows. In Section 1 the motivations of our work are outlined. Section 2 describes the O-Dang! Ontology, that provides a common semantic model for the integration of datasets in the KG. The Ontology Population stage with information about corpora, users, and annotations is presented in Section 3. Finally, in Section 4 an analysis of offensiveness across corpora is provided as a first case study for the resource.
APPReddit: a Corpus of Reddit Posts Annotated for Appraisal
May 31, 2022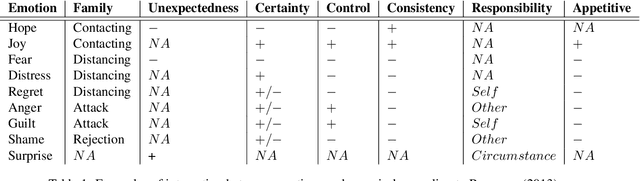
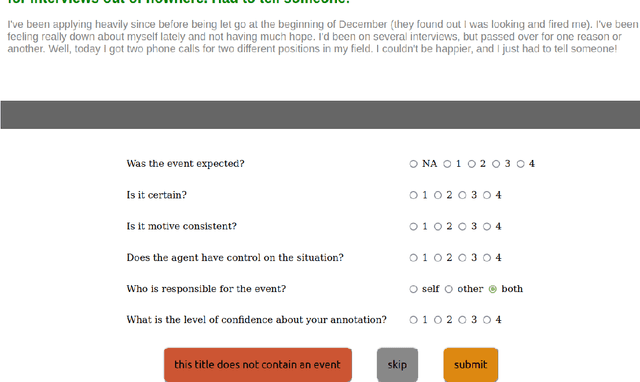

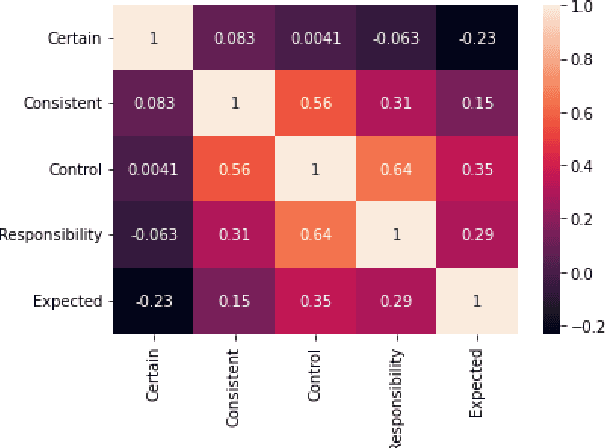
Despite the large number of computational resources for emotion recognition, there is a lack of data sets relying on appraisal models. According to Appraisal theories, emotions are the outcome of a multi-dimensional evaluation of events. In this paper, we present APPReddit, the first corpus of non-experimental data annotated according to this theory. After describing its development, we compare our resource with enISEAR, a corpus of events created in an experimental setting and annotated for appraisal. Results show that the two corpora can be mapped notwithstanding different typologies of data and annotations schemes. A SVM model trained on APPReddit predicts four appraisal dimensions without significant loss. Merging both corpora in a single training set increases the prediction of 3 out of 4 dimensions. Such findings pave the way to a better performing classification model for appraisal prediction.