 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ghost Annotator: a Framework to Explore Human Label Variation in Content Moderation through Conformal Prediction
Jun 01, 2026Current research primarily focuses on model performance, while comparatively less attention has been devoted to uncertainty estimation, particularly in settings where LLMs are increasingly used to generate annotated data. We introduce a framework combining conformal prediction with Collaborative Filtering-style annotators' representation to model LLM behavior in relation to human annotators and to analyze patterns of agreement and disagreement. Using Non-Conformity Scores, we introduce the Ghost Prediction metric and the Ghost Annotator representation to quantify cases in which model predictions diverge from all available human annotations. We compute cosine similarity measures to explore differences in model behavior across sociodemographic axes. We evaluated four LLMs of different size and families across four content moderation datasets. Our finding shows that while we find that all models uncertainty increases with annotator disagreement, larger models tend to be more confident in the classification of texts that are not aligned with any human annotation. Finally, the Ghost Annotator framework reveals a consistent and robust pattern of demographic misalignment, suggesting a structural bias likely rooted in pretraining corpora.
O-Dang! The Ontology of Dangerous Speech Messages
Jul 13, 2022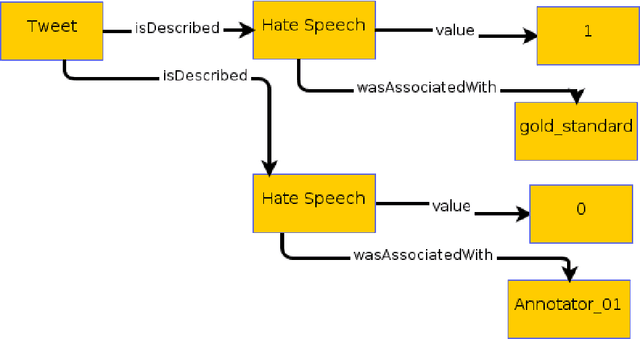
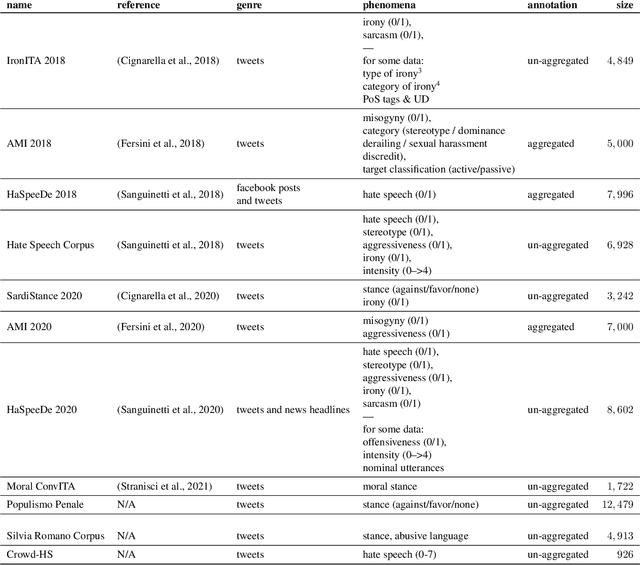
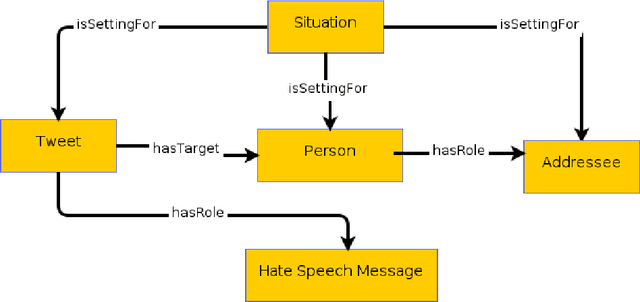
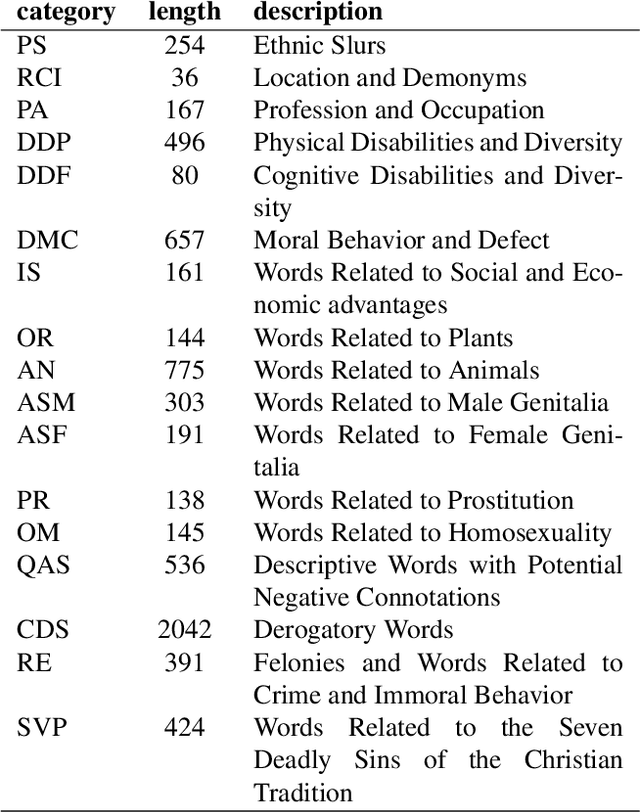
Inside the NLP community there is a considerable amount of language resources created, annotated and released every day with the aim of studying specific linguistic phenomena. Despite a variety of attempts in order to organize such resources has been carried on, a lack of systematic methods and of possible interoperability between resources are still present. Furthermore, when storing linguistic information, still nowadays, the most common practice is the concept of "gold standard", which is in contrast with recent trends in NLP that aim at stressing the importance of different subjectivities and points of view when training machine learning and deep learning methods. In this paper we present O-Dang!: The Ontology of Dangerous Speech Messages, a systematic and interoperable Knowledge Graph (KG) for the collection of linguistic annotated data. O-Dang! is designed to gather and organize Italian datasets into a structured KG, according to the principles shared within the Linguistic Linked Open Data community. The ontology has also been designed to account for a perspectivist approach, since it provides a model for encoding both gold standard and single-annotator labels in the KG. The paper is structured as follows. In Section 1 the motivations of our work are outlined. Section 2 describes the O-Dang! Ontology, that provides a common semantic model for the integration of datasets in the KG. The Ontology Population stage with information about corpora, users, and annotations is presented in Section 3. Finally, in Section 4 an analysis of offensiveness across corpora is provided as a first case study for the resource.
#Brexit: Leave or Remain? The Role of User's Community and Diachronic Evolution on Stance Detection
Jul 29, 2020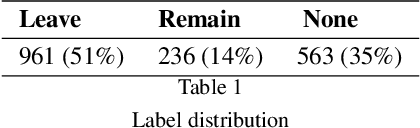
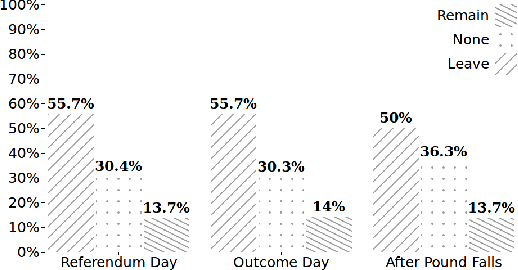
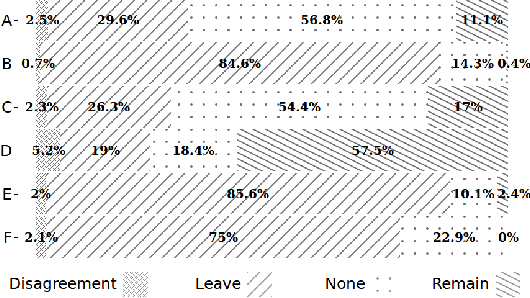
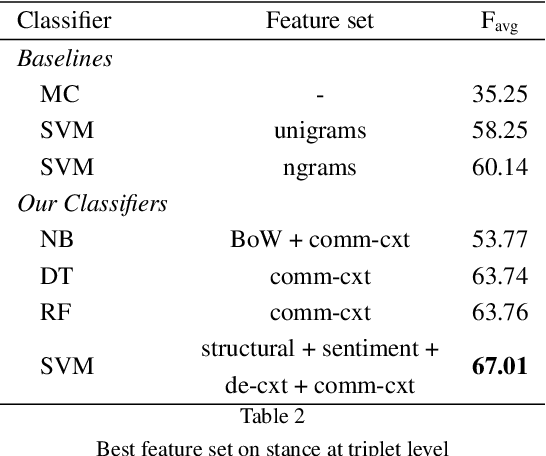
Interest has grown around the classification of stance that users assume within online debates in recent years. Stance has been usually addressed by considering users posts in isolation, while social studies highlight that social communities may contribute to influence users' opinion. Furthermore, stance should be studied in a diachronic perspective, since it could help to shed light on users' opinion shift dynamics that can be recorded during the debate. We analyzed the political discussion in UK about the BREXIT referendum on Twitter, proposing a novel approach and annotation schema for stance detection, with the main aim of investigating the role of features related to social network community and diachronic stance evolution. Classification experiments show that such features provide very useful clues for detecting stance.
Friends and Enemies of Clinton and Trump: Using Context for Detecting Stance in Political Tweets
Feb 26, 2017
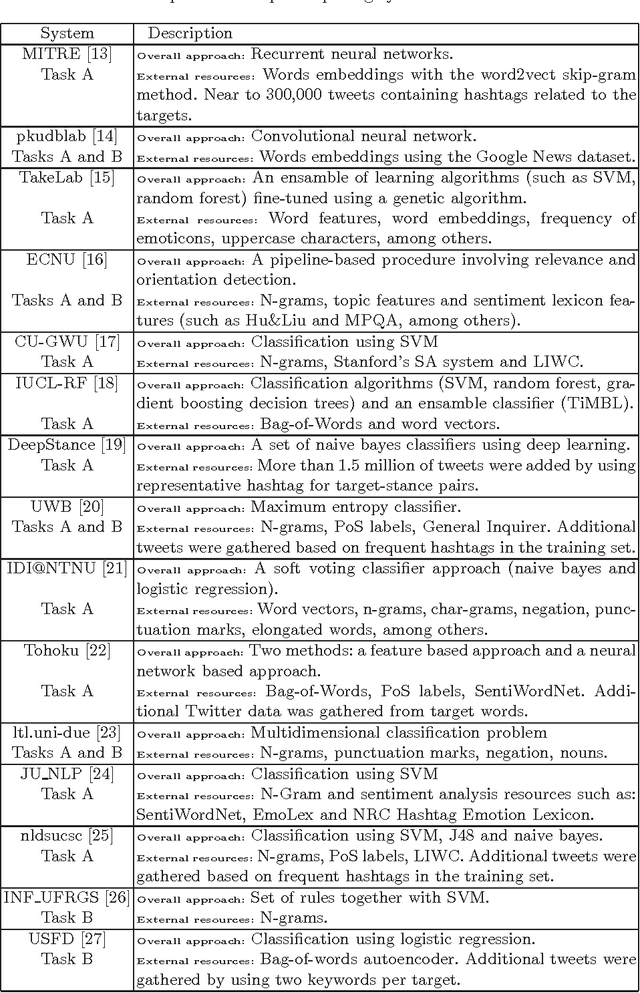

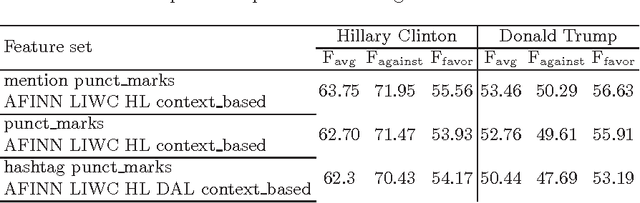
Stance detection, the task of identifying the speaker's opinion towards a particular target, has attracted the attention of researchers. This paper describes a novel approach for detecting stance in Twitter. We define a set of features in order to consider the context surrounding a target of interest with the final aim of training a model for predicting the stance towards the mentioned targets. In particular, we are interested in investigating political debates in social media. For this reason we evaluated our approach focusing on two targets of the SemEval-2016 Task6 on Detecting stance in tweets, which are related to the political campaign for the 2016 U.S. presidential elections: Hillary Clinton vs. Donald Trump. For the sake of comparison with the state of the art, we evaluated our model against the dataset released in the SemEval-2016 Task 6 shared task competition. Our results outperform the best ones obtained by participating teams, and show that information about enemies and friends of politicians help in detecting stance towards them.