 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(De)-Indexing and the Right to be Forgotten
Jan 07, 2025

In the digital age, the challenge of forgetfulness has emerged as a significant concern, particularly regarding the management of personal data and its accessibility online. The right to be forgotten (RTBF) allows individuals to request the removal of outdated or harmful information from public access, yet implementing this right poses substantial technical difficulties for search engines. This paper aims to introduce non-experts to the foundational concepts of information retrieval (IR) and de-indexing, which are critical for understanding how search engines can effectively "forget" certain content. We will explore various IR models, including boolean, probabilistic, vector space, and embedding-based approaches, as well as the role of Large Language Models (LLMs) in enhancing data processing capabilities. By providing this overview, we seek to highlight the complexities involved in balancing individual privacy rights with the operational challenges faced by search engines in managing information visibility.
Anomaly detection in cross-country money transfer temporal networks
Nov 24, 2023During the last decades, Anti-Financial Crime (AFC) entities and Financial Institutions have put a constantly increasing effort to reduce financial crime and detect fraudulent activities, that are changing and developing in extremely complex ways. We propose an anomaly detection approach based on network analysis to help AFC officers navigating through the high load of information that is typical of AFC data-driven scenarios. By experimenting on a large financial dataset of more than 80M cross-country wire transfers, we leverage on the properties of complex networks to develop a tool for explainable anomaly detection, that can help in identifying outliers that could be engaged in potentially malicious activities according to financial regulations. We identify a set of network centrality measures that provide useful insights on individual nodes; by keeping track of the evolution over time of the centrality-based node rankings, we are able to highlight sudden and unexpected changes in the roles of individual nodes that deserve further attention by AFC officers. Such changes can hardly be noticed by means of current AFC practices, that sometimes can lack a higher-level, global vision of the system. This approach represents a preliminary step in the automation of AFC and AML processes, serving the purpose of facilitating the work of AFC officers by providing them with a top-down view of the picture emerging from financial data.
Analyzing and Visualizing American Congress Polarization and Balance with Signed Networks
Sep 01, 2022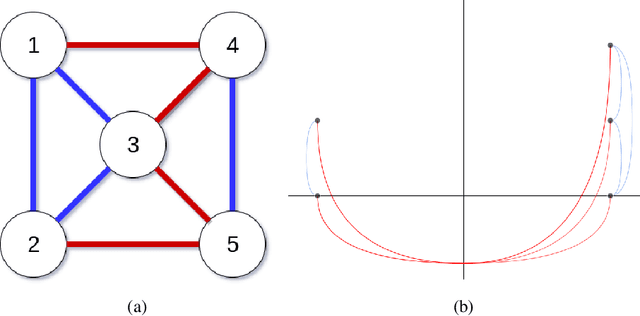
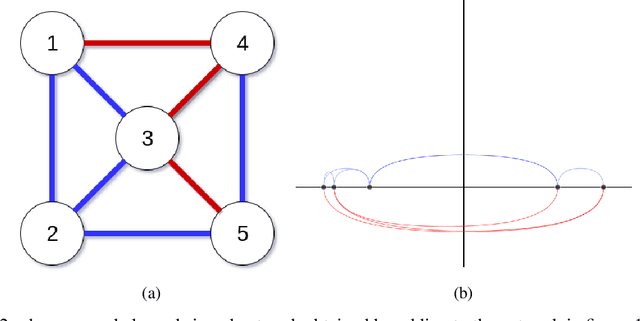
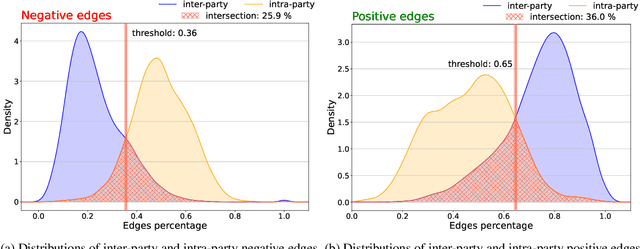
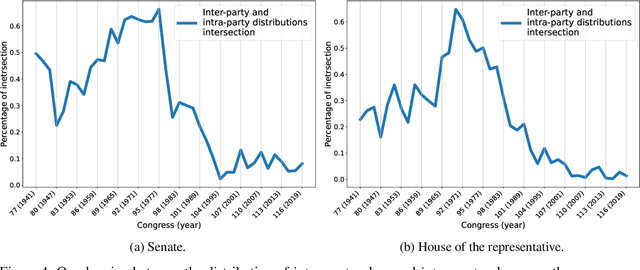
Signed networks and balance theory provide a natural setting for real-world scenarios that show polarization dynamics, positive/negative relationships, and political partisanships. For example, they have been proven effective for studying the increasing polarization of the votes in the two chambers of the American Congress from World War II on. To provide further insights into this particular case study, we propose the application of a framework to analyze and visualize a signed graph's configuration based on the exploitation of the corresponding Laplacian matrix' spectral properties. The overall methodology is comparable with others based on the frustration index, but it has at least two main advantages: first, it requires a much lower computational cost; second, it allows for a quantitative and visual assessment of how arbitrarily small subgraphs (even single nodes) contribute to the overall balance (or unbalance) of the network. The proposed pipeline allows to explore the polarization dynamics shown by the American Congress from 1945 to 2020 at different resolution scales. In fact, we are able to spot and to point out the influence of some (groups of) congressmen in the overall balance, as well as to observe and explore polarization's evolution of both chambers across the years.
Reconciling the Quality vs Popularity Dichotomy in Online Cultural Markets
Apr 28, 2022
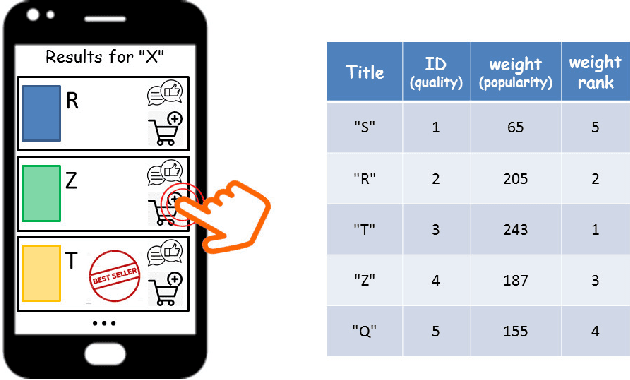
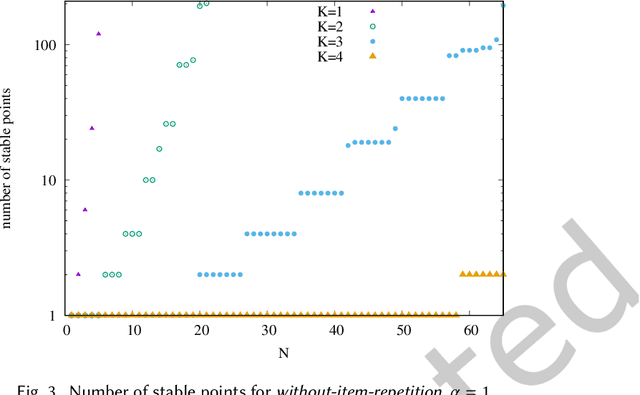
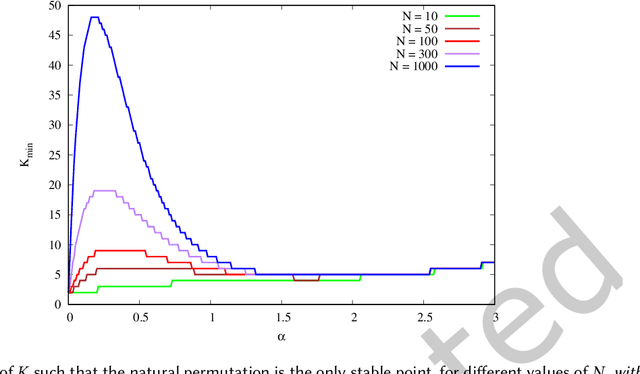
We propose a simple model of an idealized online cultural market in which $N$ items, endowed with a hidden quality metric, are recommended to users by a ranking algorithm possibly biased by the current items' popularity. Our goal is to better understand the underlying mechanisms of the well-known fact that popularity bias can prevent higher-quality items from becoming more popular than lower-quality items, producing an undesirable misalignment between quality and popularity rankings. We do so under the assumption that users, having limited time/attention, are able to discriminate the best-quality only within a random subset of the items. We discover the existence of a harmful regime in which improper use of popularity can seriously compromise the emergence of quality, and a benign regime in which wise use of popularity, coupled with a small discrimination effort on behalf of users, guarantees the perfect alignment of quality and popularity ranking. Our findings clarify the effects of algorithmic popularity bias on quality outcomes, and may inform the design of more principled mechanisms for techno-social cultural markets.
Writing about COVID-19 vaccines: Emotional profiling unravels how mainstream and alternative press framed AstraZeneca, Pfizer and vaccination campaigns
Jan 19, 2022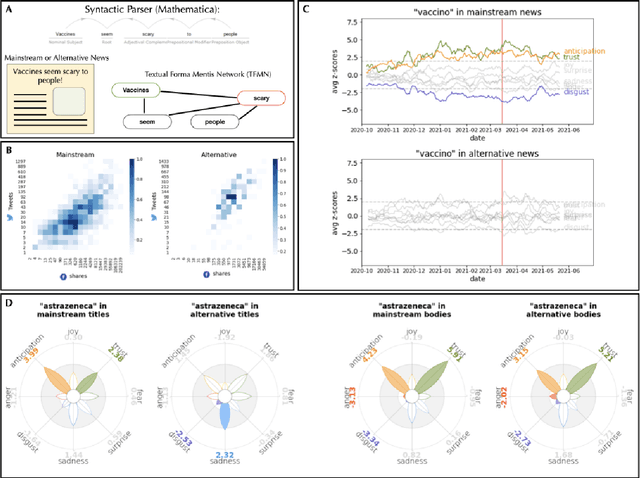
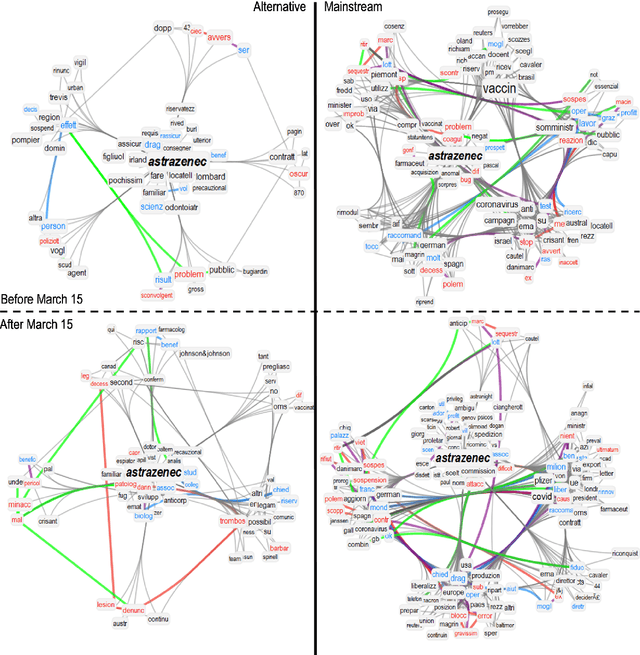
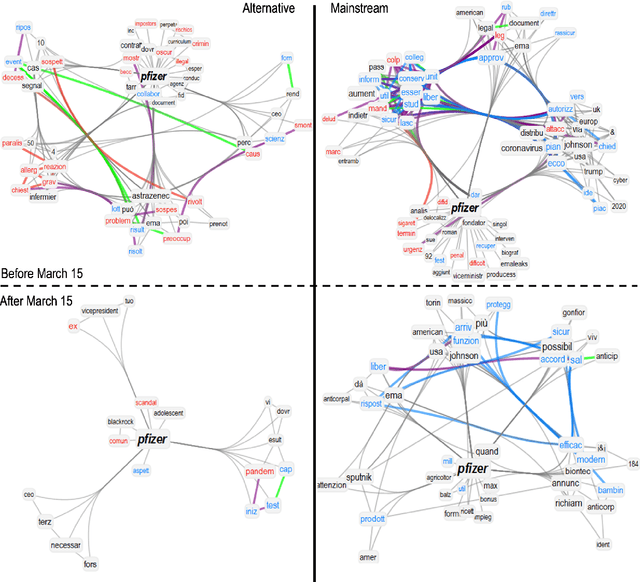
Since their announcement in November 2020, COVID-19 vaccines were largely debated by the press and social media. With most studies focusing on COVID-19 disinformation in social media, little attention has been paid to how mainstream news outlets framed COVID-19 narratives compared to alternative sources. To fill this gap, we use cognitive network science and natural language processing to reconstruct time-evolving semantic and emotional frames of 5745 Italian news, that were massively re-shared on Facebook and Twitter, about COVID-19 vaccines. We found consistently high levels of trust/anticipation and less disgust in the way mainstream sources framed the general idea of "vaccine/vaccino". These emotions were crucially missing in the ways alternative sources framed COVID-19 vaccines. More differences were found within specific instances of vaccines. Alternative news included titles framing the AstraZeneca vaccine with strong levels of sadness, absent in mainstream titles. Mainstream news initially framed "Pfizer" along more negative associations with side effects than "AstraZeneca". With the temporary suspension of the latter, on March 15th 2021, we identified a semantic/emotional shift: Even mainstream article titles framed "AstraZeneca" as semantically richer in negative associations with side effects, while "Pfizer" underwent a positive shift in valence, mostly related to its higher efficacy. "Thrombosis" entered the frame of vaccines together with fearful conceptual associations, while "death" underwent an emotional shift, steering towards fear in alternative titles and losing its hopeful connotation in mainstream titles. Our findings expose crucial aspects of the emotional narratives around COVID-19 vaccines adopted by the press, highlighting the need to understand how alternative and mainstream media report vaccination news.
Surveying the Research on Fake News in Social Media: a Tale of Networks and Language
Sep 13, 2021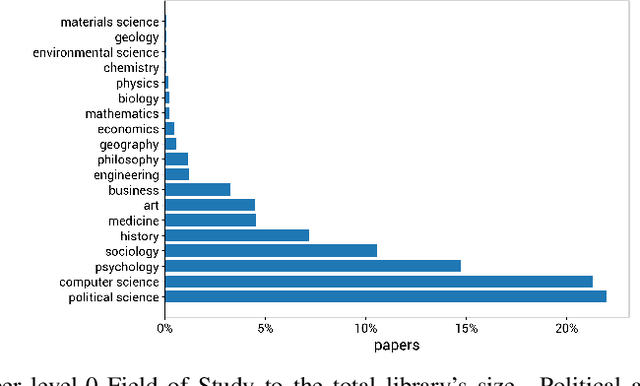
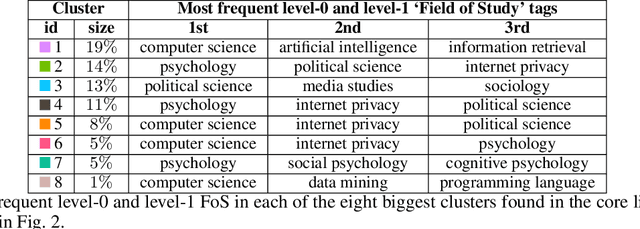
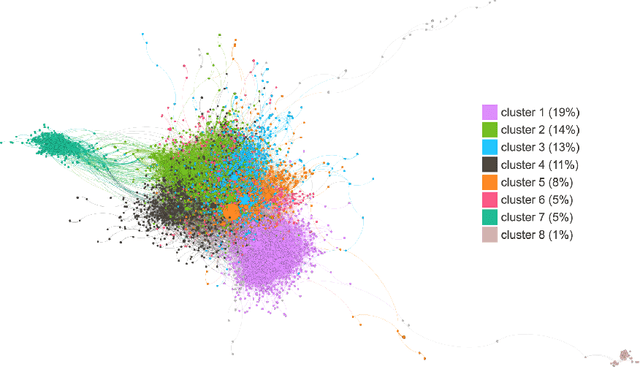
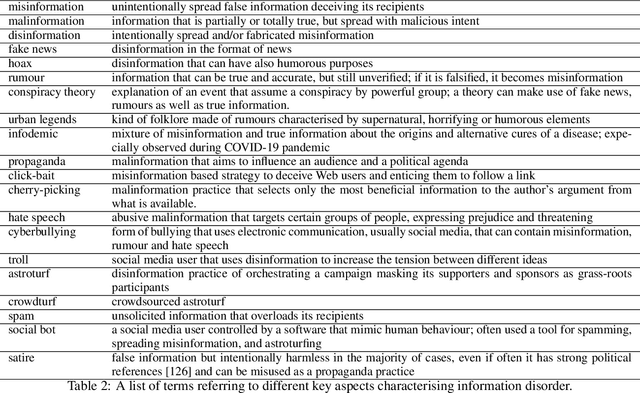
The history of journalism and news diffusion is tightly coupled with the effort to dispel hoaxes, misinformation, propaganda, unverified rumours, poor reporting, and messages containing hate and divisions. With the explosive growth of online social media and billions of individuals engaged with consuming, creating, and sharing news, this ancient problem has surfaced with a renewed intensity threatening our democracies, public health, and news outlets credibility. This has triggered many researchers to develop new methods for studying, understanding, detecting, and preventing fake-news diffusion; as a consequence, thousands of scientific papers have been published in a relatively short period, making researchers of different disciplines to struggle in search of open problems and most relevant trends. The aim of this survey is threefold: first, we want to provide the researchers interested in this multidisciplinary and challenging area with a network-based analysis of the existing literature to assist them with a visual exploration of papers that can be of interest; second, we present a selection of the main results achieved so far adopting the network as an unifying framework to represent and make sense of data, to model diffusion processes, and to evaluate different debunking strategies. Finally, we present an outline of the most relevant research trends focusing on the moving target of fake-news, bots, and trolls identification by means of data mining and text technologies; despite scholars working on computational linguistics and networks traditionally belong to different scientific communities, we expect that forthcoming computational approaches to prevent fake news from polluting the social media must be developed using hybrid and up-to-date methodologies.
PyPlutchik: visualising and comparing emotion-annotated corpora
Apr 19, 2021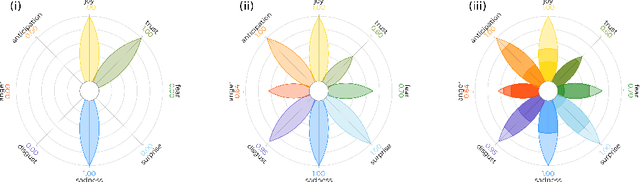
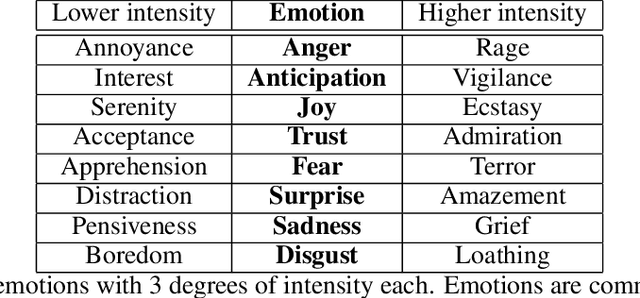
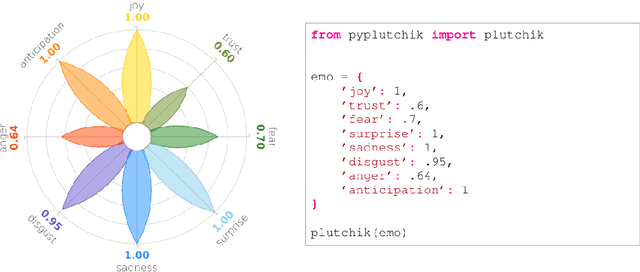
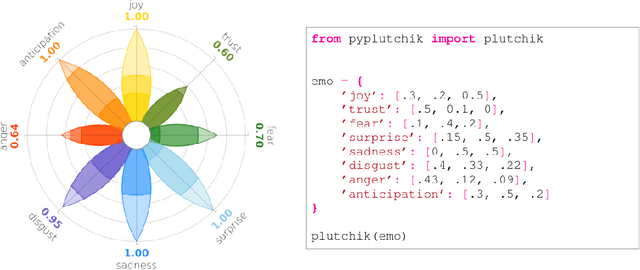
The increasing availability of textual corpora and data fetched from social networks is fuelling a huge production of works based on the model proposed by psychologist Robert Plutchik, often referred simply as the ``Plutchik Wheel''. Related researches range from annotation tasks description to emotions detection tools. Visualisation of such emotions is traditionally carried out using the most popular layouts, as bar plots or tables, which are however sub-optimal. The classic representation of the Plutchik's wheel follows the principles of proximity and opposition between pairs of emotions: spatial proximity in this model is also a semantic proximity, as adjacent emotions elicit a complex emotion (a primary dyad) when triggered together; spatial opposition is a semantic opposition as well, as positive emotions are opposite to negative emotions. The most common layouts fail to preserve both features, not to mention the need of visually allowing comparisons between different corpora in a blink of an eye, that is hard with basic design solutions. We introduce PyPlutchik, a Python library specifically designed for the visualisation of Plutchik's emotions in texts or in corpora. PyPlutchik draws the Plutchik's flower with each emotion petal sized after how much that emotion is detected or annotated in the corpus, also representing three degrees of intensity for each of them. Notably, PyPlutchik allows users to display also primary, secondary, tertiary and opposite dyads in a compact, intuitive way. We substantiate our claim that PyPlutchik outperforms other classic visualisations when displaying Plutchik emotions and we showcase a few examples that display our library's most compelling features.
#Brexit: Leave or Remain? The Role of User's Community and Diachronic Evolution on Stance Detection
Jul 29, 2020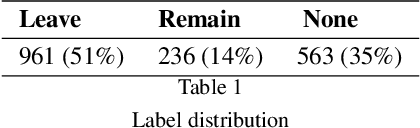
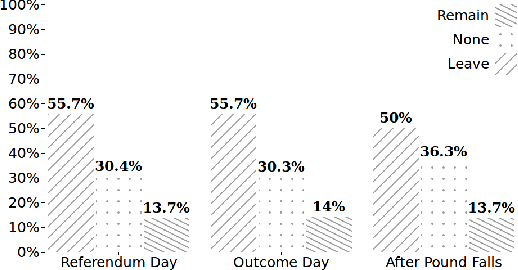
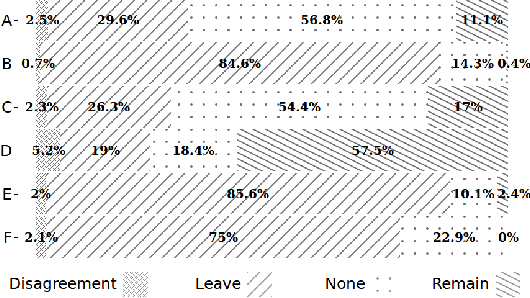
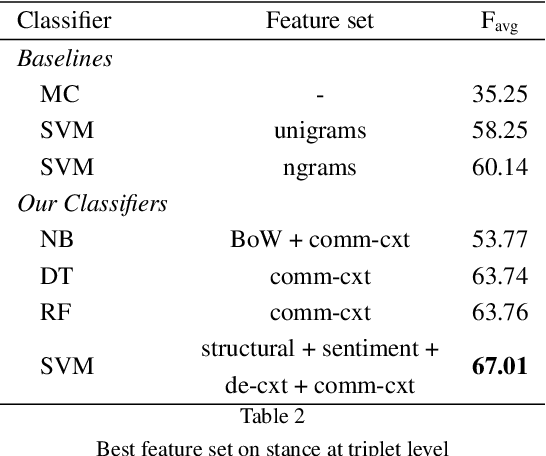
Interest has grown around the classification of stance that users assume within online debates in recent years. Stance has been usually addressed by considering users posts in isolation, while social studies highlight that social communities may contribute to influence users' opinion. Furthermore, stance should be studied in a diachronic perspective, since it could help to shed light on users' opinion shift dynamics that can be recorded during the debate. We analyzed the political discussion in UK about the BREXIT referendum on Twitter, proposing a novel approach and annotation schema for stance detection, with the main aim of investigating the role of features related to social network community and diachronic stance evolution. Classification experiments show that such features provide very useful clues for detecting stance.
Learning Real Estate Automated Valuation Models from Heterogeneous Data Sources
Sep 02, 2019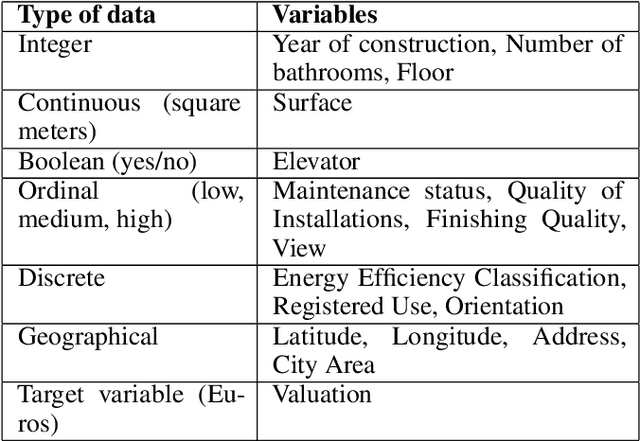
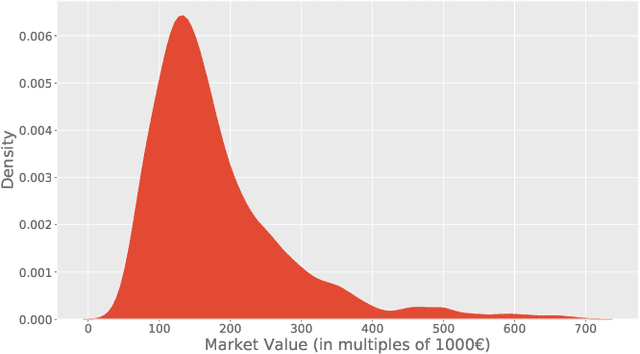
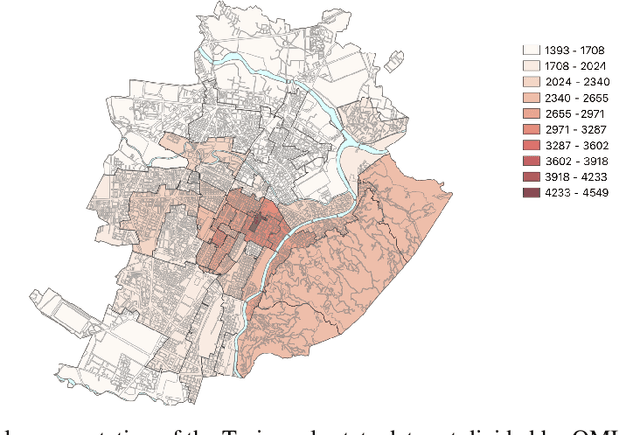
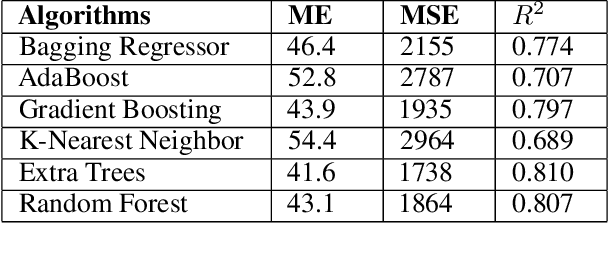
Real estate appraisal is a complex and important task, that can be made more precise and faster with the help of automated valuation tools. Usually the value of some property is determined by taking into account both structural and geographical characteristics. However, while geographical information is easily found, obtaining significant structural information requires the intervention of a real estate expert, a professional appraiser. In this paper we propose a Web data acquisition methodology, and a Machine Learning model, that can be used to automatically evaluate real estate properties. This method uses data from previous appraisal documents, from the advertised prices of similar properties found via Web crawling, and from open data describing the characteristics of a corresponding geographical area. We describe a case study, applicable to the whole Italian territory, and initially trained on a data set of individual homes located in the city of Turin, and analyze prediction and practical applicability.
People are Strange when you're a Stranger: Impact and Influence of Bots on Social Networks
Jul 30, 2014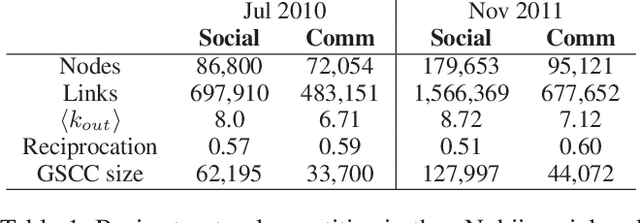
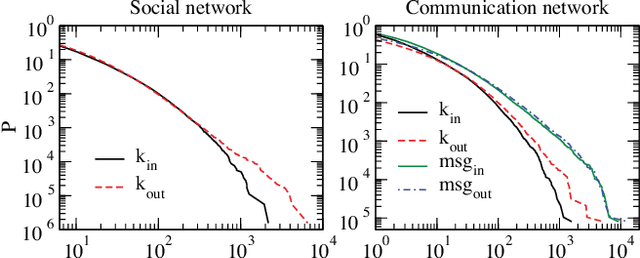
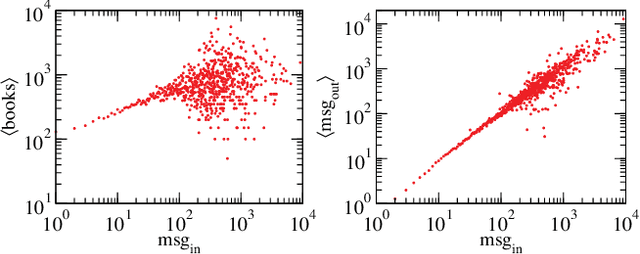

Bots are, for many Web and social media users, the source of many dangerous attacks or the carrier of unwanted messages, such as spam. Nevertheless, crawlers and software agents are a precious tool for analysts, and they are continuously executed to collect data or to test distributed applications. However, no one knows which is the real potential of a bot whose purpose is to control a community, to manipulate consensus, or to influence user behavior. It is commonly believed that the better an agent simulates human behavior in a social network, the more it can succeed to generate an impact in that community. We contribute to shed light on this issue through an online social experiment aimed to study to what extent a bot with no trust, no profile, and no aims to reproduce human behavior, can become popular and influential in a social media. Results show that a basic social probing activity can be used to acquire social relevance on the network and that the so-acquired popularity can be effectively leveraged to drive users in their social connectivity choices. We also register that our bot activity unveiled hidden social polarization patterns in the community and triggered an emotional response of individuals that brings to light subtle privacy hazards perceived by the user base.