 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein pathways as a catalyst to directed evolution of the topology of artificial neural networks
Jun 07, 2024



In the present article, we propose a paradigm shift on evolving Artificial Neural Networks (ANNs) towards a new bio-inspired design that is grounded on the structural properties, interactions, and dynamics of protein networks (PNs): the Artificial Protein Network (APN). This introduces several advantages previously unrealized by state-of-the-art approaches in NE: (1) We can draw inspiration from how nature, thanks to millions of years of evolution, efficiently encodes protein interactions in the DNA to translate our APN to silicon DNA. This helps bridge the gap between syntax and semantics observed in current NE approaches. (2) We can learn from how nature builds networks in our genes, allowing us to design new and smarter networks through EA evolution. (3) We can perform EA crossover/mutation operations and evolution steps, replicating the operations observed in nature directly on the genotype of networks, thus exploring and exploiting the phenotypic space, such that we avoid getting trapped in sub-optimal solutions. (4) Our novel definition of APN opens new ways to leverage our knowledge about different living things and processes from biology. (5) Using biologically inspired encodings, we can model more complex demographic and ecological relationships (e.g., virus-host or predator-prey interactions), allowing us to optimise for multiple, often conflicting objectives.
Modeling Teams Performance Using Deep Representational Learning on Graphs
Jun 29, 2022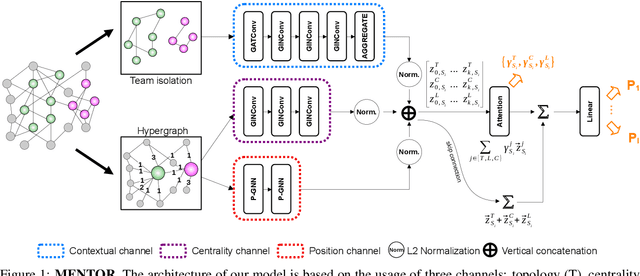
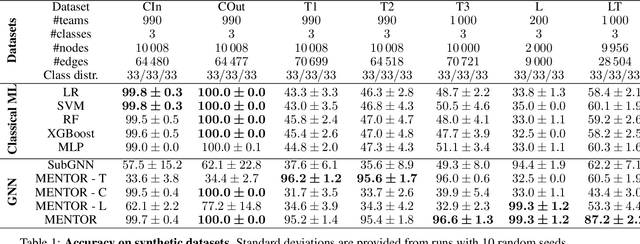
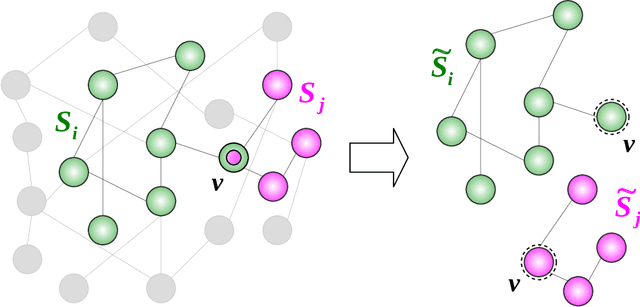
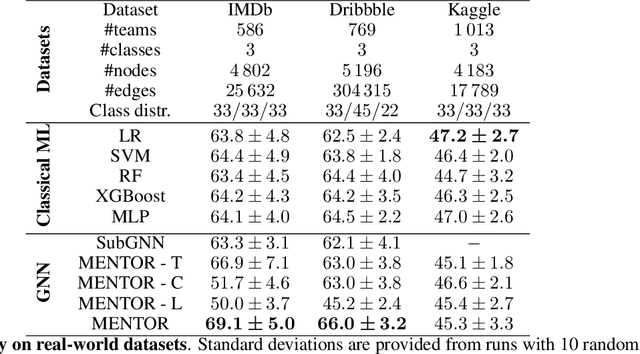
The large majority of human activities require collaborations within and across formal or informal teams. Our understanding of how the collaborative efforts spent by teams relate to their performance is still a matter of debate. Teamwork results in a highly interconnected ecosystem of potentially overlapping components where tasks are performed in interaction with team members and across other teams. To tackle this problem, we propose a graph neural network model designed to predict a team's performance while identifying the drivers that determine such an outcome. In particular, the model is based on three architectural channels: topological, centrality, and contextual which capture different factors potentially shaping teams' success. We endow the model with two attention mechanisms to boost model performance and allow interpretability. A first mechanism allows pinpointing key members inside the team. A second mechanism allows us to quantify the contributions of the three driver effects in determining the outcome performance. We test model performance on a wide range of domains outperforming most of the classical and neural baselines considered. Moreover, we include synthetic datasets specifically designed to validate how the model disentangles the intended properties on which our model vastly outperforms baselines.
Mobile Recognition of Wikipedia Featured Sites using Deep Learning and Crowd-sourced Imagery
Nov 04, 2019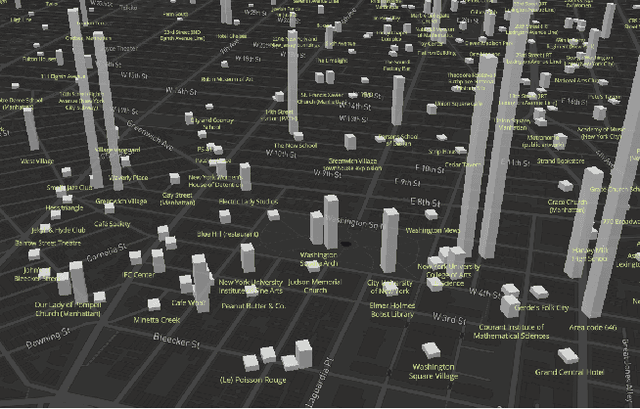
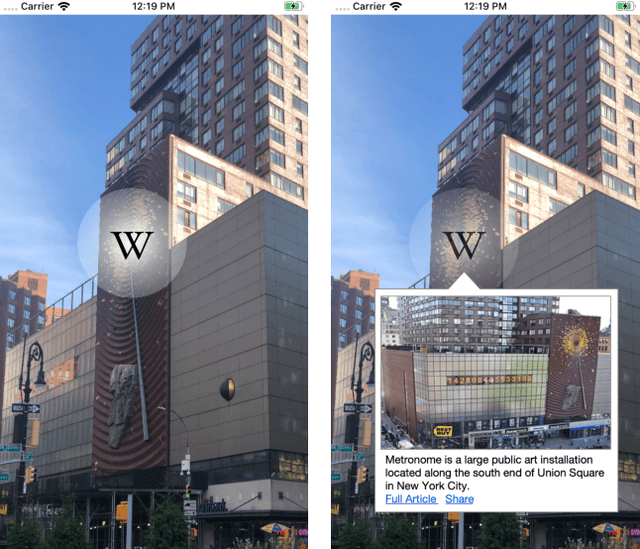
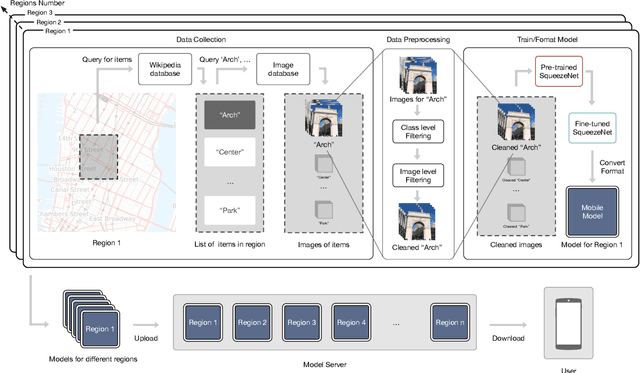
Rendering Wikipedia content through mobile and augmented reality mediums can enable new forms of interaction in urban-focused user communities facilitating learning, communication and knowledge exchange. With this objective in mind, in this work we develop a mobile application that allows for the recognition of notable sites featured on Wikipedia. The application is powered by a deep neural network that has been trained on crowd-sourced imagery describing sites of interest, such as buildings, statues, museums or other physical entities that are present and visually accessible in an urban environment. We describe an end-to-end pipeline that describes data collection, model training and evaluation of our application considering online and real world scenarios. We identify a number of challenges in the site recognition task which arise due to visual similarities amongst the classified sites as well as due to noise introduce by the surrounding built environment. We demonstrate how using mobile contextual information, such as user location, orientation and attention patterns can significantly alleviate such challenges. Moreover, we present an unsupervised learning technique to de-noise crowd-sourced imagery which improves classification performance further.
Multimodal Social Media Analysis for Gang Violence Prevention
Jul 23, 2018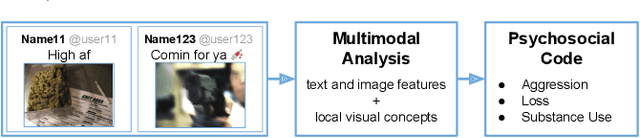
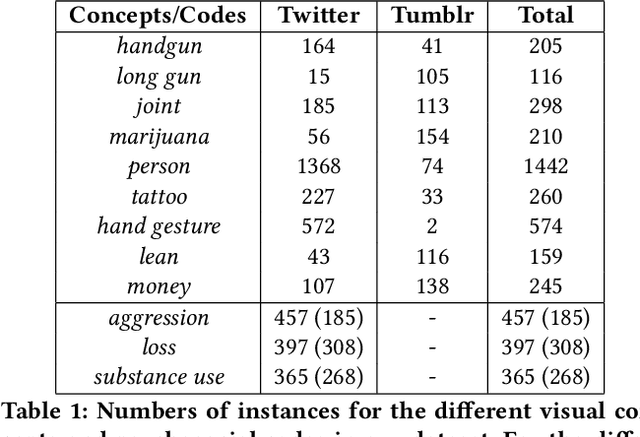

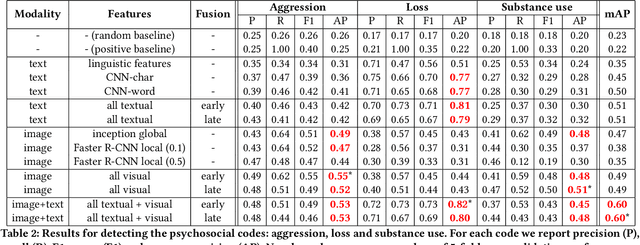
Gang violence is a severe issue in major cities across the U.S. and recent studies [Patton et al. 2017] have found evidence of social media communications that can be linked to such violence in communities with high rates of exposure to gang activity. In this paper we partnered computer scientists with social work researchers, who have domain expertise in gang violence, to analyze how public tweets with images posted by youth who mention gang associations on Twitter can be leveraged to automatically detect psychosocial factors and conditions that could potentially assist social workers and violence outreach workers in prevention and early intervention programs. To this end, we developed a rigorous methodology for collecting and annotating tweets. We gathered 1,851 tweets and accompanying annotations related to visual concepts and the psychosocial codes: aggression, loss, and substance use. These codes are relevant to social work interventions, as they represent possible pathways to violence on social media. We compare various methods for classifying tweets into these three classes, using only the text of the tweet, only the image of the tweet, or both modalities as input to the classifier. In particular, we analyze the usefulness of mid-level visual concepts and the role of different modalities for this tweet classification task. Our experiments show that individually, text information dominates classification performance of the loss class, while image information dominates the aggression and substance use classes. Our multimodal approach provides a very promising improvement (18% relative in mean average precision) over the best single modality approach. Finally, we also illustrate the complexity of understanding social media data and elaborate on open challenges.
Beautiful and damned. Combined effect of content quality and social ties on user engagement
Nov 01, 2017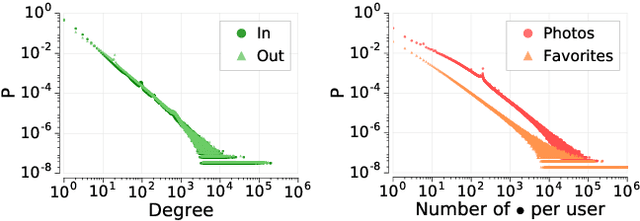
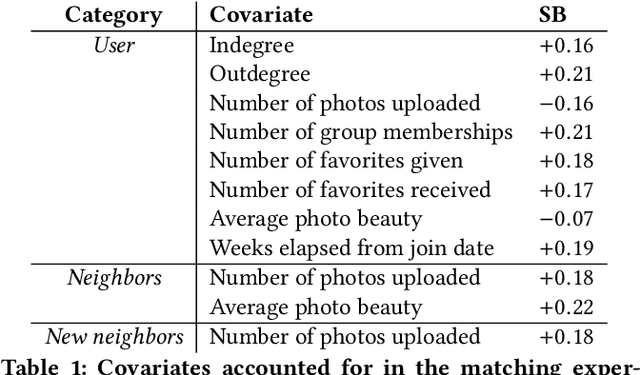
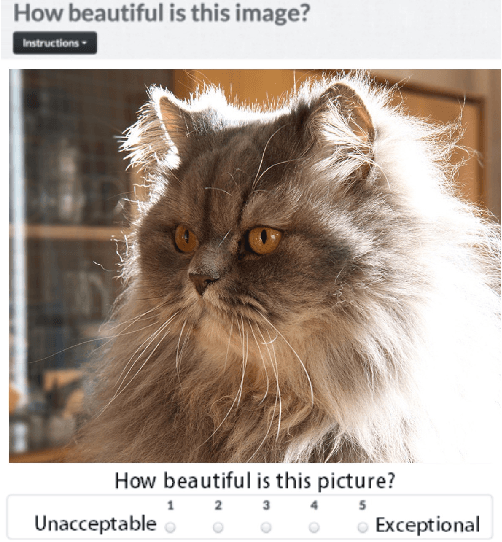
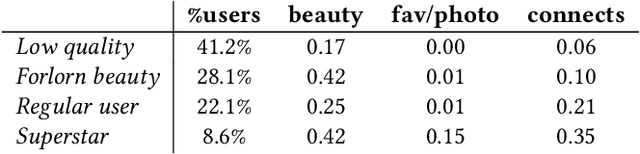
User participation in online communities is driven by the intertwinement of the social network structure with the crowd-generated content that flows along its links. These aspects are rarely explored jointly and at scale. By looking at how users generate and access pictures of varying beauty on Flickr, we investigate how the production of quality impacts the dynamics of online social systems. We develop a deep learning computer vision model to score images according to their aesthetic value and we validate its output through crowdsourcing. By applying it to over 15B Flickr photos, we study for the first time how image beauty is distributed over a large-scale social system. Beautiful images are evenly distributed in the network, although only a small core of people get social recognition for them. To study the impact of exposure to quality on user engagement, we set up matching experiments aimed at detecting causality from observational data. Exposure to beauty is double-edged: following people who produce high-quality content increases one's probability of uploading better photos; however, an excessive imbalance between the quality generated by a user and the user's neighbors leads to a decline in engagement. Our analysis has practical implications for improving link recommender systems.
Detecting Sarcasm in Multimodal Social Platforms
Aug 08, 2016

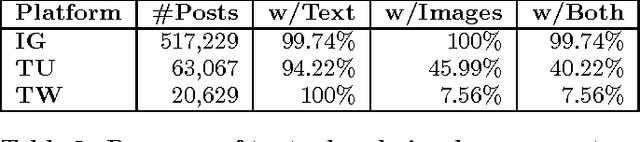

Sarcasm is a peculiar form of sentiment expression, where the surface sentiment differs from the implied sentiment. The detection of sarcasm in social media platforms has been applied in the past mainly to textual utterances where lexical indicators (such as interjections and intensifiers), linguistic markers, and contextual information (such as user profiles, or past conversations) were used to detect the sarcastic tone. However, modern social media platforms allow to create multimodal messages where audiovisual content is integrated with the text, making the analysis of a mode in isolation partial. In our work, we first study the relationship between the textual and visual aspects in multimodal posts from three major social media platforms, i.e., Instagram, Tumblr and Twitter, and we run a crowdsourcing task to quantify the extent to which images are perceived as necessary by human annotators. Moreover, we propose two different computational frameworks to detect sarcasm that integrate the textual and visual modalities. The first approach exploits visual semantics trained on an external dataset, and concatenates the semantics features with state-of-the-art textual features. The second method adapts a visual neural network initialized with parameters trained on ImageNet to multimodal sarcastic posts. Results show the positive effect of combining modalities for the detection of sarcasm across platforms and methods.
An Image is Worth More than a Thousand Favorites: Surfacing the Hidden Beauty of Flickr Pictures
May 15, 2015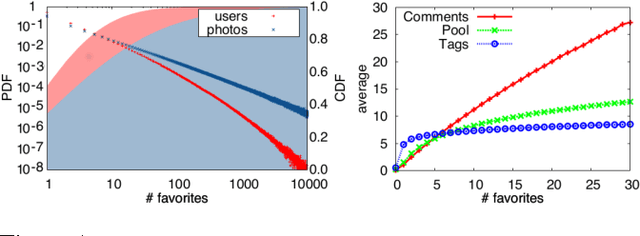


The dynamics of attention in social media tend to obey power laws. Attention concentrates on a relatively small number of popular items and neglecting the vast majority of content produced by the crowd. Although popularity can be an indication of the perceived value of an item within its community, previous research has hinted to the fact that popularity is distinct from intrinsic quality. As a result, content with low visibility but high quality lurks in the tail of the popularity distribution. This phenomenon can be particularly evident in the case of photo-sharing communities, where valuable photographers who are not highly engaged in online social interactions contribute with high-quality pictures that remain unseen. We propose to use a computer vision method to surface beautiful pictures from the immense pool of near-zero-popularity items, and we test it on a large dataset of creative-commons photos on Flickr. By gathering a large crowdsourced ground truth of aesthetics scores for Flickr images, we show that our method retrieves photos whose median perceived beauty score is equal to the most popular ones, and whose average is lower by only 1.5%.
6 Seconds of Sound and Vision: Creativity in Micro-Videos
Nov 14, 2014

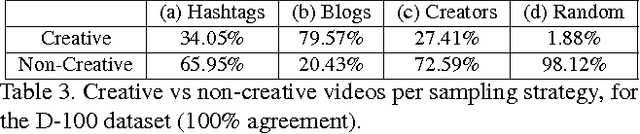
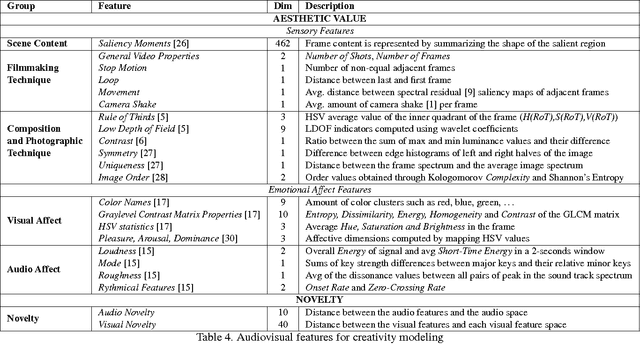
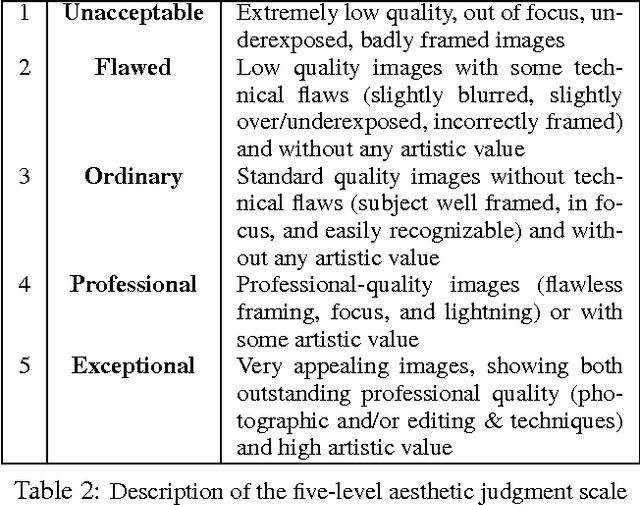
The notion of creativity, as opposed to related concepts such as beauty or interestingness, has not been studied from the perspective of automatic analysis of multimedia content. Meanwhile, short online videos shared on social media platforms, or micro-videos, have arisen as a new medium for creative expression. In this paper we study creative micro-videos in an effort to understand the features that make a video creative, and to address the problem of automatic detection of creative content. Defining creative videos as those that are novel and have aesthetic value, we conduct a crowdsourcing experiment to create a dataset of over 3,800 micro-videos labelled as creative and non-creative. We propose a set of computational features that we map to the components of our definition of creativity, and conduct an analysis to determine which of these features correlate most with creative video. Finally, we evaluate a supervised approach to automatically detect creative video, with promising results, showing that it is necessary to model both aesthetic value and novelty to achieve optimal classification accuracy.
People are Strange when you're a Stranger: Impact and Influence of Bots on Social Networks
Jul 30, 2014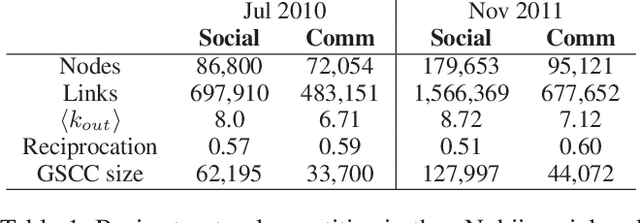
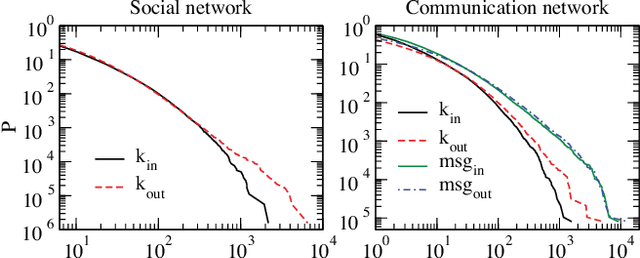
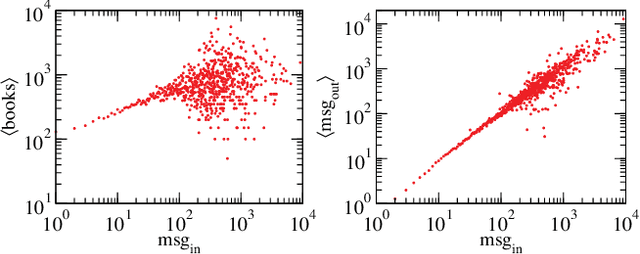

Bots are, for many Web and social media users, the source of many dangerous attacks or the carrier of unwanted messages, such as spam. Nevertheless, crawlers and software agents are a precious tool for analysts, and they are continuously executed to collect data or to test distributed applications. However, no one knows which is the real potential of a bot whose purpose is to control a community, to manipulate consensus, or to influence user behavior. It is commonly believed that the better an agent simulates human behavior in a social network, the more it can succeed to generate an impact in that community. We contribute to shed light on this issue through an online social experiment aimed to study to what extent a bot with no trust, no profile, and no aims to reproduce human behavior, can become popular and influential in a social media. Results show that a basic social probing activity can be used to acquire social relevance on the network and that the so-acquired popularity can be effectively leveraged to drive users in their social connectivity choices. We also register that our bot activity unveiled hidden social polarization patterns in the community and triggered an emotional response of individuals that brings to light subtle privacy hazards perceived by the user base.