 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA critical look at the current train/test split in machine learning
Jun 08, 2021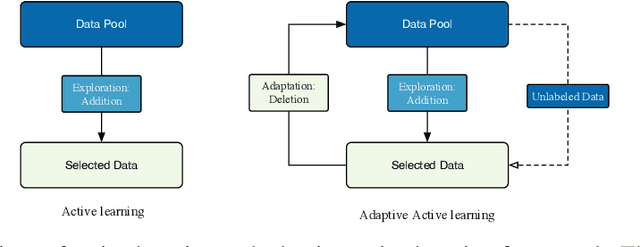

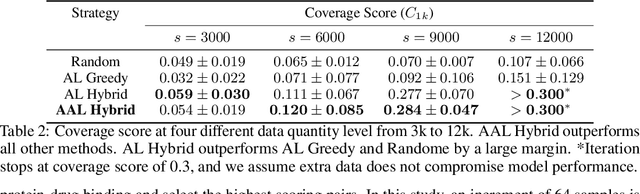
The randomized or cross-validated split of training and testing sets has been adopted as the gold standard of machine learning for decades. The establishment of these split protocols are based on two assumptions: (i)-fixing the dataset to be eternally static so we could evaluate different machine learning algorithms or models; (ii)-there is a complete set of annotated data available to researchers or industrial practitioners. However, in this article, we intend to take a closer and critical look at the split protocol itself and point out its weakness and limitation, especially for industrial applications. In many real-world problems, we must acknowledge that there are numerous situations where assumption (ii) does not hold. For instance, for interdisciplinary applications like drug discovery, it often requires real lab experiments to annotate data which poses huge costs in both time and financial considerations. In other words, it can be very difficult or even impossible to satisfy assumption (ii). In this article, we intend to access this problem and reiterate the paradigm of active learning, and investigate its potential on solving problems under unconventional train/test split protocols. We further propose a new adaptive active learning architecture (AAL) which involves an adaptation policy, in comparison with the traditional active learning that only unidirectionally adds data points to the training pool. We primarily justify our points by extensively investigating an interdisciplinary drug-protein binding problem. We additionally evaluate AAL on more conventional machine learning benchmarking datasets like CIFAR-10 to demonstrate the generalizability and efficacy of the new framework.
Mobile Recognition of Wikipedia Featured Sites using Deep Learning and Crowd-sourced Imagery
Nov 04, 2019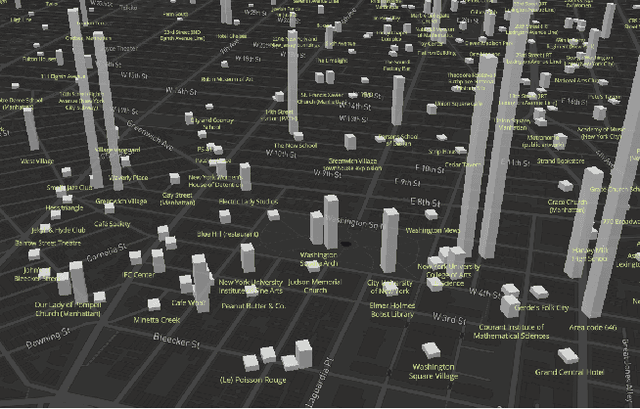
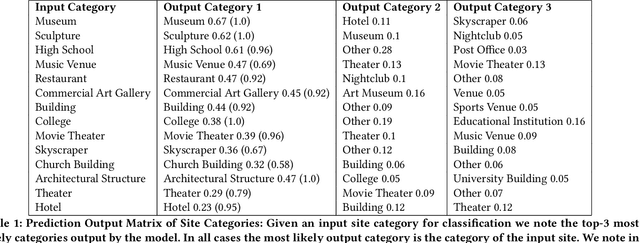
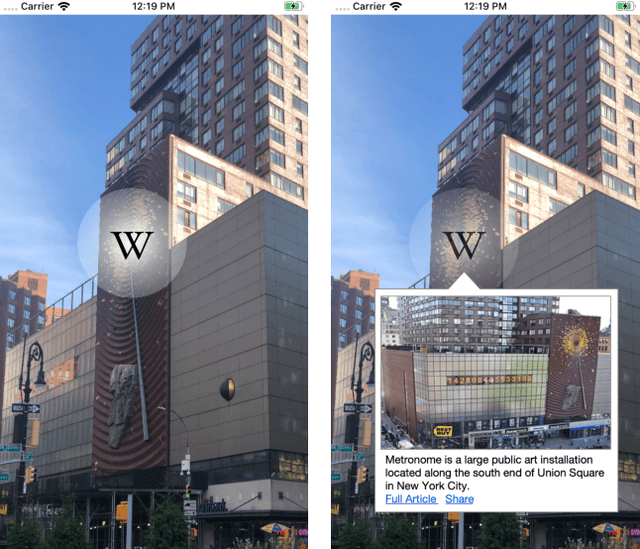
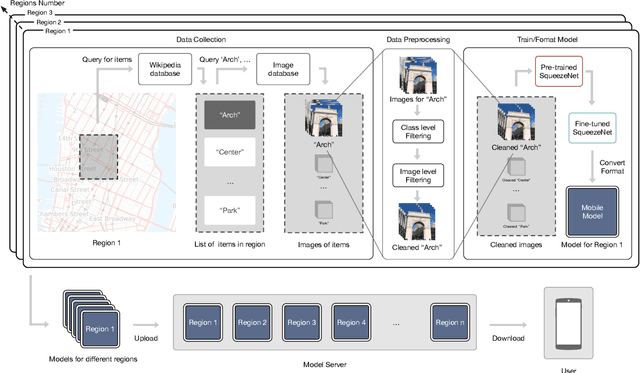
Rendering Wikipedia content through mobile and augmented reality mediums can enable new forms of interaction in urban-focused user communities facilitating learning, communication and knowledge exchange. With this objective in mind, in this work we develop a mobile application that allows for the recognition of notable sites featured on Wikipedia. The application is powered by a deep neural network that has been trained on crowd-sourced imagery describing sites of interest, such as buildings, statues, museums or other physical entities that are present and visually accessible in an urban environment. We describe an end-to-end pipeline that describes data collection, model training and evaluation of our application considering online and real world scenarios. We identify a number of challenges in the site recognition task which arise due to visual similarities amongst the classified sites as well as due to noise introduce by the surrounding built environment. We demonstrate how using mobile contextual information, such as user location, orientation and attention patterns can significantly alleviate such challenges. Moreover, we present an unsupervised learning technique to de-noise crowd-sourced imagery which improves classification performance further.